Sink Kafka Messages to ClickHouse Using 'ClickHouse Kafka Ingestor'
How we use our in-house Golang application to sink Kafka messages to Clickhouse.

By Nikko Khresna
In a previous article about Clickhouse, Detecting Fraudsters in Near Real Time with ClickHouse, we spoke about why we chose ClickHouse for our Near-Real-Time rule engine. It is fast, high performing, easy to debug, and uses a syntax familiar to everyone, SQL. We encourage you to take a look at the detailed information in the article. The article also touched on our Clickhouse Kafka Ingestor, an in-house Golang application to sink Kafka messages to Clickhouse, that we will describe in depth here. Firstly, let’s touch on a few points about ClickHouse and Kafka that will be important later on.
Brief introduction to Clickhouse
ClickHouse is an open-source, OLAP, column-oriented database. And because it stores data in columnar way, ClickHouse is very fast on performing select, joins, and aggregations. On the other hand, insert, update, delete operations must be done with precaution.
In the case of ClickHouse, it stores data in small chunks, called data parts. Data parts are the reason why it is blazingly fast at read operations. It helps to narrow down the data you are interested in when reading from a table. And when there is an update operation it has to find every column that needs to be updated/deleted, then rebuild the parts, and these operations are heavy and expensive. That is why ClickHouse is perfect for sinking Kafka messages, just streams of data without update/delete operations.
Brief introduction to Kafka
In brief, Kafka is a very popular event-streaming platform, although previously it was conceived as a message queue platform. The reason it is so popular among tech companies is because it is a very versatile tool, there are over a hundred supported Kafka clients to either publish or consume the messages. Below is the overview of Kafka Components:
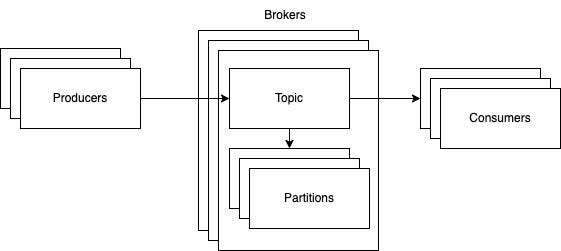
From the overview above, Kafka has several components:
- Producer: a component that publishes events to event stream
- Consumer: a component that listens to event stream
- Broker: a component that responds to producer and consumer requests and hosts topic partition data.
Kafka is used widely to publish events so other systems can listen to the event and process the message. The same is true in Gojek’s ecosystem, there are hundreds of kafka topics that are consumed and published at any time, ranging from informational to critical events. These events are critical for the Risk department in detecting potential fraudulent activities.
Kafka use case for decision making system
The messages or events published to Kafka are critical information for our analysts that they use to detect potential fraud posed to our users. Some of the biggest examples are detecting fake gps, and completed undelivered order. That is why we have spent a huge amount of time to find a solution to process multiple Kafka datastreams at ease, because joining multiple streams and querying with a lookback period have been one of the most important capabilities for our usecases.
Another important point is that we use Proto schema to define our Kafka message schema. This is a very convenient way to make sure that Kafka producers and consumers can send and interpret messages as expected.
Processing Kafka Streams with ClickHouse
Clickhouse comes with native Kafka support to sink messages to table, here’s how it looks in a high-level overview:
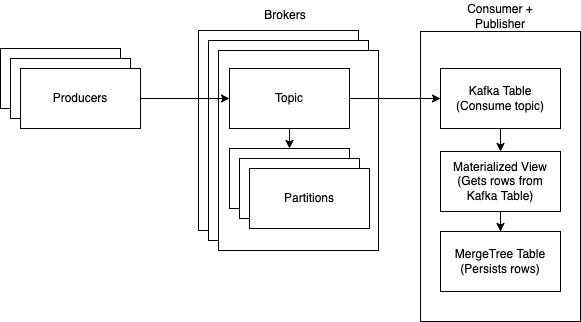
This looks very similar to image 1 “ Kafka Overview”, but adds more details on the consumer part. The added complexity here is something we also want to emphasize and walk you through a little bit. There are 3 important components that we need to concentrate on: Kafka table, Materialized View, and MergeTree table.
The Kafka Engine
Before we talk about the Kafka table engine, we need to discuss what a table engine is. Whenever you create a ClickHouse table, you’d need to specify the engine you want to use. There are engines such as MergeTree, Log, Buffer, View, MaterializedView and so on. They define how the data is stored, where to store and read the data, what queries are supported, etc. Kafka engine essentially lets you consume Kafka messages from configured topic and broker. Messages can only be read once, just like consuming from Kafka using any other client. Another important point to note is that this table can also act as a publisher if we insert into it. We will touch more on this later on.
Sink-ing Kafka to ClickHouse
To sink Kafka messages to a Clickhouse table, we need to create a table in ClickHouse with the Kafka() engine.
ClickHouse can use Protobuf schema out-of-the-box, to use proto schema as table schema we are required to put the proto in this directory /var/lib/clickhouse/format_schemasfor example: /var/lib/clickhouse/format_schemas/account_registration_log.proto. We define a table as follows: (to keep examples relevant, we will use the account registration log example moving forward):
CREATE TABLE default.account_registration_log_kafkastream
(
// column definitions
…
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'account-registration-topic',
kafka_group_name = 'group_name',
kafka_format = 'data_format',
kafka_row_delimiter = 'delimiter_symbol',
kafka_schema = 'account_registration_log.proto:RegistrationMessage',
kafka_num_consumers = N,
kafka_max_block_size = 0,
kafka_skip_broken_messages = N,
kafka_commit_every_batch = 0,
kafka_thread_per_consumer = 0Values passed above are not necessarily correct values, they are there just to give an overview of the settings. This will create a table with the name account_registration_log_kafkastream which acts as a topic consumer, and sinks messages into the table. Interestingly, this table behaves like Kafka, once you read the row of this table using SELECT, the rows that are read will be gone, similar to when you ack a message in Kafka. Because each message in this Kafka engine table can be read only once, we need storage to persist the data, the Materialized View.
Persisting Sink-ed Kafka Messages
Because the rows will be gone once they are read from the Kafka Table, we need a way to persist the messages, and that’s when Materialized View or MV for short comes into picture. Think of it as an insert trigger that will be run when new rows are about to be inserted into the source table (in this case, the account_registration_log_kafkastream table). It runs the AS SELECT FROM query that is defined when creating a MV against the to-be-inserted rows. Finally it inserts the result into target table (in example default.account_registration_log_mt table)
Below is an example on how we create materialized view:
CREATE MATERIALIZED VIEW default.account_registration_log_mv
TO default.account_registration_log_mt
ENGINE = MergeTree
ORDER BY …
AS SELECT … FROM default.account_registration_log_kafkastreamLet’s dissect the previous query to understand more about Materialized View, so that it is easier to understand.
CREATE MATERIALIZED VIEW default.account_registration_log_mv
TO default.account_registration_log_mtWe need to specify the name of the Materialized View a.k.a the insert trigger (default.account_registration_log_mv) and also the target table (default.account_registration_log_kafkastream), We also need to specify the engine of the target by defining the engine using following expression:
ENGINE = MergeTree
ORDER BY …MergeTree is a table engine that can process batches of data very efficiently. When writes come, the table stores data in small parts and merges them in the background. For a more detailed view of MergeTree I suggest you check the article I mentioned in the beginning. And the last expression is a normal select query.
AS SELECT … FROM default.account_registration_log_kafkastreamThe SELECT query is the query that will be performed on each insert that happens on the source table, that is default.account_registration_log_kafkastream. And the result of this query will be inserted into the the target table (default.account_registration_log_mt)
With this approach, the persistence is achieved by duplication of data and we can query the data from default.account_registration_log_mt any number of times we need.
Common Challenges
The steps for the previous approach are easy to follow and work right away. However, from our experience, we found some challenges with the built-in ClickHouse capability. In this section we will zoom in on the challenges, and discuss why they are drawbacks for us in Gojek.
Protobuf support lacks ease of maintenance
The first challenge is related to how we store the protobuf descriptors. ClickHouse can use Protobuf schema out-of-the-box, which is convenient. Within the Kafka() engine table, the transformation of protobuf messages to table rows happens internally in ClickHouse, so we have to store the proto schema in /var/lib/clickhouse/format_schemas.
However, we at Risk Platform store our proto descriptors in a common repository, so every team only needs to import the repository and have access to all proto descriptors available. This is problematic when using it with ClickHouse, the repository has to be present under /var/lib/clickhouse/format_schemas directory and updated periodically. We can already estimate the time required to update the descriptors in every ClickHouse node and also the risk of having our credential stored in the nodes.
Hand-writing ‘CREATE TABLE' SQL
From our experience, hand-writing SQL often needs a trial-and-error approach. And when it gets repetitive, it quickly becomes very tedious, not to mention that the number of fields in Protobuf descriptors greatly vary from few to tens of fields. In our early analysis, we had foreseen tens of Kafka topics to be sinked. With an increasing number of requests to sink Kafka topics, the effort to accommodate these requests can get out of control easily. With that as one of the considerations, we were convinced that we need a tool that can help us generate these queries fast and accurately.
No documentation of schema changes
The lack of schema changes history would pose a great challenge when we need to ensure consistency of table schemas across application environments. We also like to keep the habit of ensuring that schema changes are documented and reviewed to prevent human errors and make sure the schema is what we expect.
Non-configurable batch insertion
There are settings we can configure when creating Kafka table in ClickHouse
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'account-registration-topic',
kafka_group_name = consumer_group_name,
kafka_format = Protobuf,
kafka_schema = 'account_registration_log.proto:RegistrationMessage',
kafka_num_consumers = NWhile this may be sufficient, we would like to be able to fine tune the Kafka consumer even more, for example we want to control the maximum number of messages kept in the buffer, and maximum buffer time before flushing to the ClickHouse table. And there is no way of doing it when using the ClickHouse Kafka() table engine.
Schema change of Kafka table, Materialized View and Merge Tree table
After you create a table with Kafka() engine, it is not possible to modify the schema of the table, for example when the protobuf descriptor has column addition. We’ll get following error message when trying to ALTER, in this example to add column
c22031d0ea72 :) ALTER TABLE default.account_registration_log_kafkastream ADD COLUMN last_name String
Received exception from server (version 21.8.3):
Code: 48. DB::Exception: Received from localhost:9000. DB::Exception: Alter of type 'ADD COLUMN' is not supported by storage Kafka.The possible approach is to drop the Kafka table and create a new Kafka table with updated schema. But we still need to update the MV and the Merge Tree table so that new column addition is also reflected in the MV and Merge Tree table.
First we’ll need to detach the MV to stop receiving data from the Kafka table to avoid data discrepancy.
DETACH TABLE default.account_registration_log_mvThen it is safe to do required modification to both MV and Merge Tree tables.
-- Add column to target table
ALTER TABLE default.account_registration_log_mt ADD COLUMN last_name String;
-- Reattach MV with updated query that includes new column
ATTACH MATERIALIZED VIEW default.account_registration_log_mv
TO default.account_registration_log_mt
ENGINE = MergeTree
ORDER BY …
AS SELECT … FROM default.account_registration_log_kafkastream;The process is not straightforward and prone to human error. When data evolves and tables need frequent changes, we foresee it will take a lot of maintainer’s time and effort.
Accidental insert to `account_registration_log_kafkastream` table will publish the message to the topic
As we discussed earlier, account_registration_log_kafkastream table (the table that consumes the messages) can also act as a publisher if we insert into it. Great care must be taken to ensure that there is no accidental insert to this table. Because in our case, Kafka is used organization-wide to publish and listen to events, accidental inserts may result in third party systems processing the generated event unintentionally.
ClickHouse Kafka Ingestor
The challenges described above did cost us engineering time and effort, and we predict they will greatly burden other engineers too in keeping up with the ad-hoc requests and maintaining the system. So we decided to create an in-house Golang application to ingest Kafka messages to ClickHouse and tackle all the challenges we have covered. The application works by listening to Kafka topics, and then transforming the messages to sql expression and storing them in a buffer. When thresholds are met, these sql insert expressions are flushed and inserted to ClickHouse. We use two thresholds, one is maximum time to wait and maximum number of sql expressions before flush happens. The thresholds are also configurable for each Kafka topic the application listens to.
Below is the flow overview of ClickHouse Kafka Ingestor that Gojek Risk Platform built in-house.
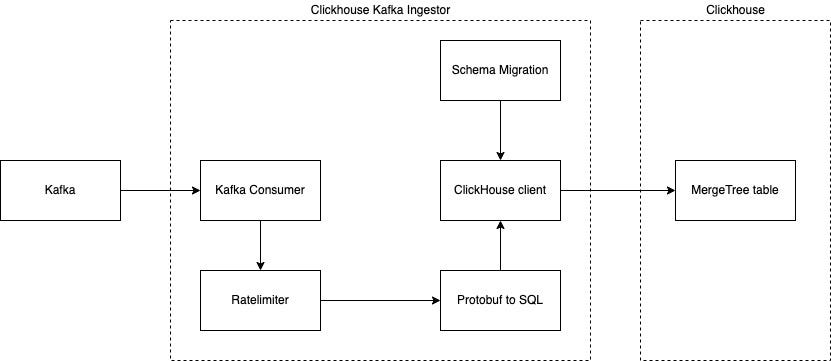
With the ClickHouse Kafka Ingestor application we are able to solve the challenges that we discussed earlier. We’ll go through each of the challenges and describe how the application is able to greatly improve our quality of maintenance life-cycle.
Ease of maintaining Protobuf descriptors
The first challenge we need to tackle is related to updating Protobuf descriptors. To do this, we leverage the Go compiled Protobuf descriptors that are available via the common repository. So when the application consumes a Kafka message, it can deserialize that message and then create INSERT SQL according to that deserialized message.
Below is an example of a Go mod file that shows how we keep track of said Go compiled Protobuf descriptor dependency and its versions.
# contents of go.mod
module gitlab.com/clickhouse-kafka-ingestor
go 1.17
require (
gitlab.com/risk-go-protobuf-descriptor-repository v1.18.0
)We see that dependencies are defined in a go package with the version. So whenever a descriptor in the gitlab.com/risk-go-protobuf-descriptor-repository repo is updated, the package version will increase. We then need to update the protobuf package version in the Go mod file to have access to the newest version of the descriptors. In summary We only need to change in one place to update the descriptor that we use to deserialize Kafka messages, as opposed to the process of updating the descriptors in every ClickHouse node.
Code generated `CREATE TABLE` SQL
Earlier we mentioned about the issues related to handwriting the CREATE TABLE SQL, and the need of a tool to generate these SQLs. To accomplish this, we take advantage of our already imported Protobuf descriptors in the application and create a simple tool that generates a migration file. The tool takes the Protobuf URL and table name as arguments, finds the Protobuf definition with that URL. Then finally generates a CREATE TABLE SQL for the table with column definitions that match the Protobuf definitions.
The migration file will be run when we deploy the ClickHouse Kafka Ingestor. As a standard deployment process, we deploy the application to the staging environment first. This side-effect also benefits us to be able to do checks before deploying it to the production environment.
Documented schema changes
The migration files are handy for replicating the database schema to multiple environments for debugging purposes and it is a good practice to have them in general.
Because the migration files are committed to the application repository, we gain the benefit such as the ability to peer review before being merged to master. Other than that, it serves as a source of truth on the database structure. With the help of migration files, we have been able to minimize handwriting error before we create or modify tables and also replicate the database structure to multiple environments.
Configurable batch insertion for each topic
To sink Kafka topics we’ll need to define configuration that defines brokers, topic name, consumer group name, and some threshold before flush happens. We can configure them from the environment variables of the application that are very straightforward.
KAFKA_INPUT_STREAMS: [{
"consumer_group_prefix": "group_name_",
"brokers": ["host:port"],
"topic": "account-registration-topic",
"table_name": "account_registration_log_mt",
"proto_url": "gojek.account.AccountRegistrationLogMessage",
"flush_max_message": 50000,
"flush_timeout_ms": 1000
}]The most important configurations are the flush_max_message and flush_timeout_ms, they define events that need to happen before the flush (writing to ClickHouse) happens. In this case either when the application has consumed 50.000 messages or when 1 second has passed. We can also add other events in the future when necessary.
Schema change is straightforward by using `MergeTree` engine
Now that we have only the MergeTree table to worry about, we have omitted huge maintenance costs. Not only that, MergeTree also supports the ALTER TABLE statement. So when schema change is needed, we don’t need to drop the Kafka table, detach Materialized View, and update the Materialized View & Merge Tree table.
To achieve it, we can create a new migration file, then we’ll just need to write an ALTER query based on our needs and it will run automatically on deployment. Sweet!
Accidental insert is contained within the table
Without the Kafka engine table, there is no component that can accidentally publish a message to Kafka. So we can be confident that even when a client accidentally writes to our table, it won’t cause incidental publishing to Kafka topics, especially when another application connects to ClickHouse with a write-permission client. This allows us to maintain the reliability of Kafka messages that we consume.
Impact
The ClickHouse Kafka Ingestor has been running since 2020 and countless messages have been sink-ed to ClickHouse as data points of our fraud rules. Here is a glimpse of the production environment performance.
We deploy the ClickHouse Kafka Ingestor in cluster setup for production, consisting of 2 application instances, each connected to 2 ClickHouse write-only instances. Our ClickHouse server runs on 2 instances for write-only and 3 instances for read-only to optimize read queries. So far, we have been able to utilize the application to sink Kafka messages at the rate of more than tens of thousand messages per second and consuming tens of Kafka topics. With the data points in place, we are able to detect risky and potential fraudulent activities even before they occur.
What’s next
We believe that we are not the first and the last team to have to face the challenges. We do hope that this may solve the issues who had and will stumble upon them. So as the next milestone, we are in the process of open sourcing the ClickHouse Kafka Ingestor. Stay tuned!

Find more stories from our vault, here.
Check out open job positions by clicking below:
