Detecting Fraudsters In Near Real-Time With ClickHouse
Here's how we ensure our constantly evolving Gojek ecosystem is safe for our customers, driver partners, and merchant partners.

By Siyao Li
In Gojek, we constantly seek innovative solutions to solve our evolving challenges on keeping the platform safe for our customers, driver partners, merchant partners, and our entire ecosystem.
ClickHouse is used for this very purpose.
It is one of the technologies we deployed recently to battle fraudsters on our platform. In this article, we aim to describe our approach towards ClickHouse adoption, covering the following topics:
- Using ClickHouse with a simplified use case
- Building a data pipeline for ClickHouse
- Our production setup
The problems we’re trying to solve
For years, our fraud detection engine focused on batch detection. It has worked well for a few years helping us with battling fraudsters. However, as our business complexity grows, we increasingly see use cases where catching fraudsters in near real-time is necessary. Real-time rules help to limit the damage done to our customers before the order is completed. It also helps us create better customer experience as we will be able to react before damage is done.
We naturally looked at our existing infrastructure. We have an existing data warehouse which backs our batch detection logic. However, it is not suitable for frequent and repeated real-time queries as it is a relatively cold storage that requires minutes before data update happens. For small queries, it also requires a few seconds as it needs to provision resources and process the queries. Therefore, we started looking at an alternative near real-time solution to complement our batch-based solution.
Our goal is to find a new data store for the near-real-time rule engine. Our users, data analysts, have voiced out their desires for the new rule engine to have following properties:
- SQL based, fast deployment, and fast execution (<1s) for queries that are relatively simple
- Easy to debug with clear error messages
- Join real-time data streams with millions of data points with static reference data with hundreds of millions of data points
- Join multiple real-time data streams with millions of data points
- Able to see the result immediately and perform further analysis easily with SQL
- Frequent executions of queries at intervals of a few seconds to less than a minute
Experimenting with ClickHouse
With the requirements given by analysts, we turned to stream processing engines and Online Analytical Processing (OLAP) databases. We tested a few databases with the same experimental scenario in mind. After our evaluation, we landed on ClickHouse, which is an open-source OLAP Database with focus on performance.
We picked it as our solution because of the following reasons:
- Smooth learning curve (for SQL users)
- High performance and horizontal scalability
- Acceptable maintenance cost
Experimental scenario
We will explain in detail with a simplified sample scenario that we used during the experiment. In the experiment, we would like to find new accounts with concurrent bookings. Concurrent booking is defined as a booking that overlaps with any other booking, and the booking duration is defined by the booking creation event + booking completion/cancellation event. New accounts are defined as accounts created within the last 30 minutes. Therefore, we limit our lookup window to T-30 minutes.
We have two corresponding Kafka streams for customer account activities and food booking activities. However, those streams are general-purpose streams that reflect all updates in customer account activities and food booking. We should also not perform any optimization specific to the example, as in reality they can be used in multiple queries and our data analysts have absolute freedom in writing the queries for new use cases.
When we were deciding the simulated scale of our experiment, we looked at the most common size of the problems that our data analysts need to solve. For most real-time queries in a time span of 30 minutes, the average number of events is around tens of thousands to tens of millions depending on stream. Hence, we picked the typical load of streams, where we simulated 50 thousand events on customer account activities, and 2 millions events on bookings. The query we are going to run includes a self-join on the food booking event to find out the duration, as well as usual selection, filtering, and sub-querying. We would like the query to be executed every 5 seconds, and the query should complete within 1 second.
Defining tables and populating data
To accommodate our use case, we started with a single-node ClickHouse instance on a e2-standard-8 machine on Google Cloud. The first task we had to accomplish was to make the test data available in ClickHouse. Table creation is slightly different from the usual Data Description Language (DDL) in other RDBMSes, but we were able to come up with our first table definition for food booking events as shown below by following the common examples.
CREATE TABLE order_log (
customer_id Int32,
order_number String,
status String,
event_timestamp DateTime64(3, 'UTC')
) ENGINE = MergeTree()
ORDER BY (event_timestamp)
PARTITION BY toYYYYMMDD(event_timestamp)
SETTINGS index_granularity = 8192We also defined our customer account activities table as below.
CREATE TABLE customer_log (
customer_id Int32,
new_user UInt8,
event_timestamp DateTime64(3, 'UTC')
) ENGINE = MergeTree()
ORDER BY (event_timestamp)
PARTITION BY toYYYYMMDD(event_timestamp)
SETTINGS index_granularity = 8192To avoid the complexity of consuming production data in our testing environment, we did not collect data from the production Kafka stream at this stage. Instead, we created a dump for a few hours of data for both streams and used the default client to insert it into our test ClickHouse instance. In our production setup, we have implemented a specialized data ingestor to cope with the various challenges we faced, and more details could be found in the later part of this article.
The most alien part in the code above will be the line ENGINE= MergeTree() and what follows it. Let’s dive into the internals of this line and understand how it helps in our use case.
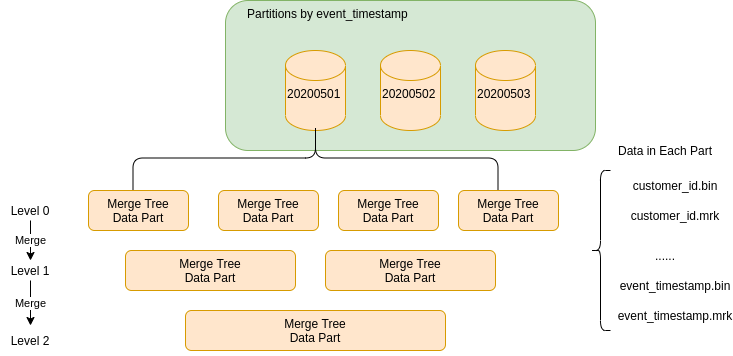
MergeTree Engine
The ENGINE clause defines the engine that the table uses, which defines how data is stored and queried from the table. MergeTree is the most common engine in ClickHouse and it is one of the reasons that ClickHouse offers good performance. Engines in the MergeTree family are designed for inserting a very large amount of data into a table in a batch manner.
To understand how MergeTree works, we start from the most familiar concept of partition, defined by the PARTITION BYclause. The partition concept here is similar to the traditional one in RDBMS, but the difference is that there are no separate tables created for each partition. It is a logical grouping of data, and it is used for more efficient querying: when a SELECT query contains a condition on the column specified by PARTITION BY, ClickHouse automatically filters out those unneeded partitions, hence reducing the amount of data read.
Within each partition, there will be many data parts. Therefore, a single ClickHouse table consists of many data parts. Each insertion will create a new data part, which is represented by a new directory in the file system as shown below. As you could imagine, this is not very efficient for point insertion, where each insertion only contains one row. Therefore, ClickHouse advises batch insertion, and also performs optimization after data is written, where rules are applied for merging the parts in the background for more efficient storage. In our understanding, that’s why the engine has a Mergeword in it.

Efficient query usually relies on some specialized data structure and ClickHouse is not an exception to that. Just like other RDBMSes, the primary key plays an important role. The primary key is usually the same as what’s defined in the ORDER BY clause, but can also be a subset of it. Data is sorted by primary key across and within data parts. Each data part is then logically divided into granules, which is the smallest indivisible data set that ClickHouse reads when selecting data. ClickHouse does not split rows or values, so each granule always contains an integer number of rows, e.g. 8192 rows in one granule. The first row of a granule is marked with the value of the primary key for the row. The positions where the granules are located in the data part is represented by marks. For each data part, ClickHouse creates an index file that stores the marks. Imagine if a query arrives and it contains a condition on the primary key. ClickHouse will be able to quickly find the data part as well as the granule using the marks. If we keep the marks in memory, the lookup will be lightning fast, and ClickHouse can directly locate the data on the disk.
Lastly, ClickHouse is a columnar database. It means data in ClickHouse is stored per column instead of per row on the disk. This reduces the amount of data read from disk at query time, as there is no need to read or skip unnecessary data. The columnar data needs to work together with the index. Therefore, for each column, whether it’s in the primary key or not, ClickHouse also stores the same marks. These marks let you find data directly in column files.
Here is a summary of the structure of MergeTree.
Optimizing Performance
Once we set up the tables and infrastructure, We proceeded to execute the query prepared by our data analysts on this example. With some minor tweaks, we were able to execute the query (so we believe our data analysts can do this with a breeze too!).
In our first attempt, we found the performance reasonable. At the scale of problem we described, the query takes roughly 1.5 seconds to run. We adopted some tweaks to improve the performance.
- Make a smaller partition. As our rule does not need a day of data, we change our
PARTITION BYclause from daily to hourly to reduce the amount of data read. - Making the enum column (e.g. status) as
LowCardinality. LowCardinality is a superstructure that changes a data storage method and rules of data processing. ClickHouse applies dictionary coding to LowCardinality-columns. It helps improve the performance by reducing the size of data read from disk. - Enable uncompressed cache. In our example, the customer account activities table is relatively small, and therefore can be cached. Therefore, we enabled the cache by setting
use_uncompressed_cacheto 1 to avoid reading the table every time from disk. This can be done safely as ClickHouse avoids caching large tables automatically. We also noticed that this works even for larger tables when the amount of data read is small.
After optimization, we successfully reduced the query duration to less than 800ms. We are satisfied with the performance as it meets our performance target.
ClickHouse Data Ingestor
As mentioned in the previous section, we dump data directly from CLI for our experiment. When we proceeded to the production setup, we thought it would be a breeze to replicate Kafka stream in ClickHouse because there is a Kafka engine readily available in ClickHouse. However, after attempting to make use of it, we decided to write our own Golang-based application to handle the data ingestion from Kafka. The application has simple responsibilities:
- Read data from Kafka as a consumer
- Buffer the data in its memory for a short duration
- Flush the data from memory to ClickHouse
There are several reasons behind this decision.
Protobuf Support
Data in our Kafka stream are all serialized with Protobuf. If we use the built-in Kafka engine, our table definition will look like the example given by ClickHouse as below. In order to resolve the schema, we need to put our Protobuf definition in /var/lib/clickhouse/format_schemas and create the table like below.
CREATE TABLE table (
field String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'topic',
kafka_group_name = 'group',
kafka_format = 'Protobuf',
kafka_schema = 'social:User',
kafka_row_delimiter = ''It works out of the box, but it creates an issue in our infrastructure. Our Protobuf schemas are stored in a common repository, and are constantly updated due to evolving business needs. We often need to add or update our protobuf schema by taking the latest version from our repository. We sometimes update our Kafka topic names as well. If we use the built-in approach, manual changes in our servers using git pull are needed for each update. We would like to avoid such manual actions.
By having a separate data ingestor, we are able to import our compiled protobuf as a dependency. Pulling the latest version of protobuf schema will be accomplished by an application deployment, and there will be no manual change required on our ClickHouse infrastructure. Additionally, as ClickHouse does not support all of the data types in Protobuf (e.g. Map), having a custom data ingestor helps us maintain the data compatibility between the two formats. We can safely ignore the unsupported fields or even perform customized mapping if the data is crucial in our business case.
Version Control of DB Schema and Performance Tuning
Whenever a new Kafka stream is replicated in Clickhouse, we need to create a corresponding table for it. As usual, we would like to have version control on it and be able to fully recover our database schema in doomsday scenarios, or when we need to expand our capacity by adding new ClickHouse nodes. We need an application to handle the migration process, and data ingestor turns out to be a good place.
We see an added advantage when we build the feature to automatically generate a table definition DDL from a given Protobuf schema. As our analysts are not familiar with the performance tweaks, we are able to apply some of the performance tuning techniques on our table definition, such as defining Enums as LowCardinality columns and encodings. This ensures that tables are adequately optimized for general purpose query. It would be harder to achieve if data ingestor does not exist.
Configurable Batch Insertion
As ClickHouse advises insertions to be batched, we need to create a buffer for the data points that we would like to insert and only perform the insertion at the frequency of several times a second. The challenge is that different Kafka streams have very different traffic, ranging from over tens of thousands records per second to a single record in a few seconds. For high-traffic streams, we need to control the frequency of ingestion by changing the batch size and flush interval. On the other hand, for low-traffic streams, we need to make sure that data will not be buffered for too long as the queries are running in near real time.
Therefore, although the logic for each stream is always the same, we apply different configurations for different streams. In our data ingestor, we extracted the following configuration for each of the streams. flush_max_messages controls the maximum size of the buffer, and flush_timeout_ms defines the maximum time that a record can be kept in the buffer. By changing the values, we can make sure ingestion is well handled for each stream.
[
{
"brokers": [
"The list of brokers, depending on the environment"
],
"topic": "topic to which the ingestor listens to",
"table_name": "destination table in ClickHouse",
"proto_url": "the Protobuf Schema URL, so that we can deserialize the message",
"flush_max_message": Maximum number of messages per batch,
"flush_timeout_ms": the interval that the messages are inserted into Clickhouse, if flush_max_message is not fully utilized
}
]Testability
The last but also important benefit of an independent ingestor is that we are able to fully test our data ingestion before putting it into production. In our CI/CD pipeline, we perform the following:
- Create a Clickhouse Cluster
- Migrate the database schema
- For each of the table, find its proto in the configuration described above
- Populate test data for the proto and perform ingestion
- Verify the same is present in Clickhouse
This ensures that we never push a problematic schema into production, and we are confident enough to make our deployment pipeline fully automated with the set of tests. Moreover, these tests do not require much maintenance, as the logic is unified across all tables and streams.
Production Deployment
Clickhouse became the core part of our rule engine on fraud detection. Therefore, our system needs to be highly available, and there should be no data loss if one ClickHouse node goes down. ClickHouse allows us to solve this problem with configurations. It supports cluster mode and also supports a `ReplicatedMergeTree` engine for the table. The `ReplicatedMergeTree` engine is just a normal MergeTree engine with the capability to replicate data across ClickHouse nodes. Using Apache Zookeeper, ClickHouse handles this for us and we do not have to worry about this.
The deployment should also handle the following requirements:
- On demand data ingestion. We need to ingest data from Kafka to Clickhouse in real time. This will be on demand as requested by our user, so we will frequently need to add new data streams in Clickhouse.
- Data ingestion and data query will happen in parallel
- Users will run experiments on production data, and those experiments should not impact production run time.
We handled the above requirements with Read/Write separation and you can get a glance at it below. Note we excluded ZooKeeper in the graph.
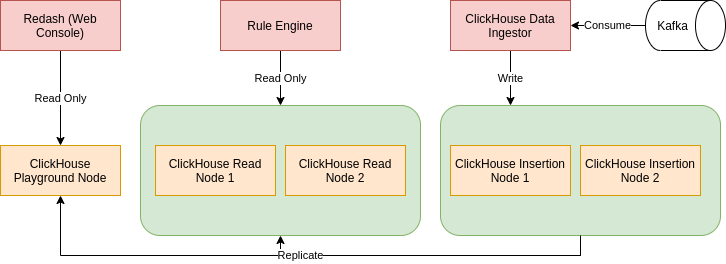
Read/Write Separation
Our ClickHouse cluster contains 5 nodes in total at this moment, where two of the nodes are only for data ingestion and three of the nodes are for reading only. Those nodes are all managed by the same ZooKeeper cluster. We define their responsibilities clearly as below.
Insertion Node
Insertion Node is only used for writing data and never used for query execution. We make sure all data writes goes to the ingestion node only from our data ingestor. After data is written to the insertion node, it will be automatically replicated to all other nodes using ReplicatedMergeTree Engine. Insertion node is configured to have visibility on all other nodes, so that it always replicates data into all nodes.
Production Node
Production Node is responsible for executing the queries written by our data analysts in their rules. We never write data into production nodes. We also ensure that our rule engine only has connectivity to the Production Node.
Playground Node
Playground Node has the same data as Production Node and it is read-only, but it is used for data analysts to experiment with their queries using data consoles such as Redash. Our rule engine does not connect to Playground Node. The separation of Playground Node from Production Node is to ensure that experimental queries will not impact the runtime of queries in production.
Capacity Planning
The difference in responsibilities creates flexibility in capacity planning. There is a significant difference in the processing power and scaling-up requirement. Here is a summary of the capacity of each of the nodes we end up using.

We planned our capacity based on our monitoring statistics and observations from our sample queries. Firstly, the capacity of the insertion node is much less than other nodes. The reason is that the job performed by insertion nodes is very simple and no query is running there. We initially used the same capacity for insertion nodes as other nodes, but we found they are very much under utilized. We then decided to significantly scale down our insertion node. At this moment, our insertion node is able to handle tens of thousands of writes per second without issue.
Secondly, we opted for a highcpu setup for our production node and playground node instead of a standard setup. Our queries are near real time and have complex logic. Most of the time, it does not require data size over tens of GBs but it needs a lot of computational power. Our monitoring also shows our queries are more CPU-hungry, even for queries with large amounts of data. Therefore, CPU is more likely to be a bottleneck in query processing. The decision to use highcpu setup is made according to the characteristics of our queries and resources used when performing the queries.
Ending Note
Our ClickHouse cluster has been in production for about a year. To date, we have tens of near real-time rules running on it, while more rules are being developed or converted from their batch-based counterparts.
We have seen that our current ClickHouse setup is able to support the evolution of our business needs to battle different fraud cases. Clickhouse-based rules have been integrated into many downstream applications, allowing us to achieve what was not possible in the past. We look forward to seeing more use cases on-boarded to our ClickHouse cluster in near future.

Here are more stories on how we do what we do.
Oh, we’re hiring! 👇
