Your Ticket Has Been Resolved
A deep dive into how we used Ruby’s metaprogramming abilities to remodel our ticket arbitration system as a functional pipeline.

By Gaurav Rakheja
At Gojek, we’re a bunch of customer-obsessed folks. So one of our main goals is to provide our users exceptional customer support.
To allow product teams to focus on feature development and iteration, we have a centralized ticket creation/arbitration process. This story is about what it looked like, what it has become, and what it could be.
The Past
First, let me explain our original system.
We have two micro-services written in Ruby on Rails. Any Gojek product that wants to create a customer support ticket to be handled by our agents calls the Ticketing Service which — based on a given set of rules and ticket properties — determines if we can automate this ticket or not. If we can, it raises a Kafka message with the details of the ticket. The other service we listens to this Kafka message and tries to automate the ticket. When it’s done, it calls the ticketing service back to update the ticket details.
We are only going to talk about the Ticket Arbitration Service. For every ticket that we can automate, Ticketing Service assigns aissue_idto the ticket which acts as an identifier for Ticket Arbitration Service to figure out what kind of automation it needs to apply to this ticket.
Historically, this system was modeled as a state machine where each state for a ticket could be represented by a state object. Each state had a name and some metadata required to process it.
Based on this issue_id we had some plain Ruby hash maps that basically drafted the flow to be followed for automation and the state column in the ticket to keep track of what happens to a ticket. A simplified version of the hash looked something like:
SOME_ORDER_ISSUE = {
UNASSIGNED: Transitions::GetDriverDetails
GET_DRIVER_DETAILS: Transitions::GetOrderDetails
GET_ORDER_DETAILS: Transitions::TakeSomeAction
...}The transitions looked like this:
# frozen_string_literal: true
module Transitions
class GetOrderDetails < Base
steps :return_next_state
private
def return_next_state(context)
continue(State::Base.new(Issues::Generic::GET_ORDER_DETAILS, context[:ticket]))
end
end
endThe contract of a transition was to take the ticket and the output of the last state and return a new state object no matter what. So if something unexpected happens, the transition would return the manual state which will tell the system to assign this ticket to an agent for manual intervention.
We did the automation in a sidekiq job which took the current ticket state and the hash applicable for the ticket. Then after getting the state object for the next state, we would trigger another job from the parent job, which would look up another class from a factory method that checked the state object’s name column and provided a relevant processor for the same.
Each processor implemented the perform method to use the configuration/data provided in the state object and performed some logic which could range from getting some information from another service to sending an email which was then called by the job.
Post completion, the job would update the ticket with the name of the state just processed. The job would then just queue itself recursively until there is no next state returned for the current state. This way, whenever the automation fails in say, the second step, the state reflects that the first step was completed — which then results in the right processor being called again.
This started off very clean and easy to understand. However, when we increased the number of automation flows, the system started getting very complex. As the number of states and processors grew, the hash maps simply did not tell us the exact flow of the automation because we soon ended up with the possibility of the ticket going to two possible states from a given state.
To see what actually happens in that state, we would have to go to the transition and read every branch of it to understand what the next state could be. With the number of growing, and increasingly complicated, use cases (eg: automation for an order cancellation issue would be very different than someone saying the driver was rude) we saw a state explosion. 💥
There were now too many states and even when you want to do 90% of what another state does, you end up repeating a lot of code. Also, every transition knew about the output that came out of the previous state, and hence an automation was not order-independent.
We noticed that we had to come up with a better architecture to model this system and started thinking about what the ideal one could be. We realised that maybe there is a problem in how we defined the domain and maybe an automation is not a state machine at all.
This resulted in us performing an exercise where we thought about what the system does — taking away how it does it — to see if there is a pattern.
And we found one.
The Present
Although most of the flows can take multiple paths, they would always end up in two possible situations — ticket is solved and no intervention required or the ticket has to be moved to an agent because either something unexpected happens or the automation logic includes a manual step.
Also, in a typical state machine there are events that trigger state transitions. We realised that we only had a single event i.e. the creation of a ticket and every subsequent transition solely depended on the successful/failed completion of the last state. This told us that our flow could, in fact, be linear rather than cyclic.
For this we devised a mental model but were not sure how it would be implemented. We came up with four terms that would define the new automation domain:
- Query — these are steps that usually get a value from an external system(mostly another Gojek product) and add it to the context
- Actions — these are steps that have external side effects, these must be handled in an idempotent manner in the automation lifecycle
- Condition — these are special kinds of steps that have the ability to branch into one of the two possible flows
- Fragment — an internal step that is required for the flow but has no external dependency, for example: updating a database record with some information
These entities could represent even the most complex automation flows we had and were easy to talk about.
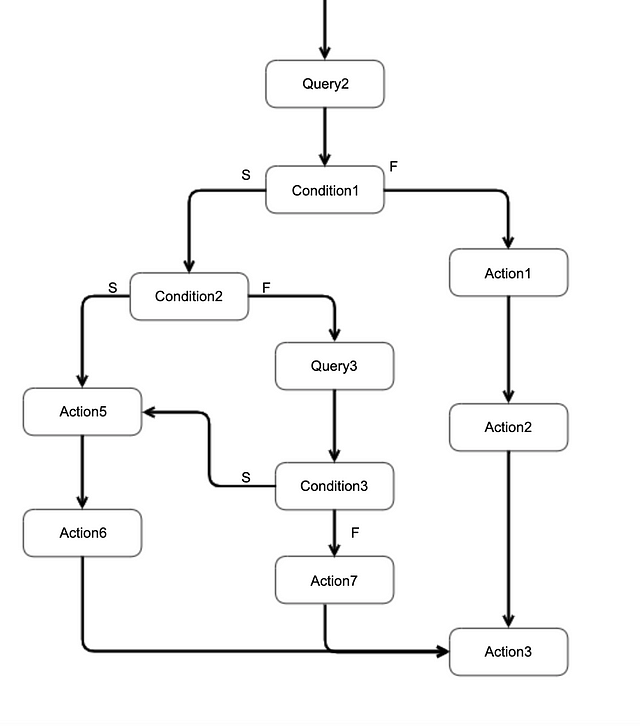
You can see that it practically represents any flow that ever happens in a software system. We also wanted a clean way to make a lot of workflows while sharing the maximum code possible without the loss of readability. This was when we came across the solid_use_case gem. It leverages a technique called Railway Oriented Programming, which turned out to be exactly what we were looking for. There is a lot of content on the Internet about what this technique is, so we’re going to focus on how our team used this library to develop a framework to create automation workflows.
From the gem’s official documentation you can see an example:
class UserSignup
include SolidUseCase
steps :validate, :save_user, :email_user
def validate(params)
user = User.new(params[:user])
if !user.valid?
fail :invalid_user, :user => user
else
params[:user] = user
continue(params)
end
end
def save_user(params)
user = params[:user]
if !user.save
fail :user_save_failed, :user => user
else
continue(params)
end
end
def email_user(params)
UserMailer.async.deliver(:welcome, params[:user].id)
# Because this is the last step, we want to end with the created user
continue(params[:user])
end
endAs you can see, it essentially allows you to chain a set of operations without doing a lot of nested conditionals. Although this is nice, solid_use_case by itself does not have an opinion of the type of value returned from an operation i.e. a step can take a user and return an email.
Although this is valuable, it limits what can and cannot be chained with each other. One of the goals of the rewrite we were doing was to take code that was being run in context of a completely different automation and to use it in a new one, for that we would never know in advance what we will and will not have across different automations.
To make the set up a little more robust, we needed a few things:
- Ever use case should take and return a hash. This would allow us to not limit the use cases to a given set of inputs. We call this hash the ‘automation context’.
- No use case should delete any key from the context
- If you need to read the key from the context you need to validate it. If you want to add a key to the context you need to call it out in advance. This is so that a person does not have to read the logic to figure out what is needed to run a step and what will be added to context after it runs.
We were already using a gem classy_hash to do some schema validations in a completely different context. It allows for a really expressive API to perform validations on a given ruby hash. From the documentation, the usage looks something like:
schema = {
key1: String,
key2: Integer,
key3: TrueClass
}
hash = {
key1: 'A Hash with class',
key2: 0,
key3: false
}
ClassyHash.validate(hash, schema)So we combined the two gems and added a sprinkle of metaprogramming to create what would form the base of our framework. This is the actual code:
# frozen_string_literal: true
class SuperUseCase
include SolidUseCase
class << self
def steps(*args)
args.unshift(:validate_context)
super(*args)
end
def contract(**context_validations)
@__validations ||= {}
@__validations.deep_merge!(context_validations)
end
def adder_for(*keys)
@__adders ||= []
keys.each do |key|
define_method "add_#{key}" do |value, context|
context[key.to_sym] = value
end
@__adders << key
end
end
def can_branch?
true
end
end
private
def validate_context(context)
errors = []
if validate_contract(context, errors)
continue(context)
else
context[:errors] = errors
fail :contract_unfulfilled,
context: context
end
end
def validate_contract(context, errors)
validations = self.class.keys_required || {}
ClassyHash.validate(
context,
validations,
raise_errors: false,
errors: errors,
verbose: true
)
end
endBefore I explain what’s going on, here’s how you use this base class:
class MyUseCase < SuperUseCase
contract some_key: String,
another_key: Integer
adder_for :key1,
:key2
steps :test_step,
:next_step
private
def test_step(context)
result = context[:some_key].something
add_key1(result, context)
continue(context)
end
def next_step(context)
another_result = context[:another_key].another_thing
add_key2(another_result, context)
continue(context)
end
endYou can see there just a subtle difference between how the library presents a use case and how we do it.
- You have to define a contract on each use case that should contain the key and type of what this use case will read from the context
- You have to give a list of keys this use case will add to the context
This makes the framework a little more expressive and also order independent while still telling you how the different use cases are dependent on each other.
Now that we had the ability to build a pipeline, it was time to create a framework that will handle the actual ticket automation. The reason this was not enough was that it only handles linear flows. We had use cases where an automation could branch out at multiple points and then some would even converge back (as pointed out by the diagram). Until this point, we’ve not built that ability.
It was now time to define the actual entities in our domain. The steps actions, queries, fragments were all quite similar and only differed in the kind of code they had. The most interesting bit was to model the conditional/branching steps.
For a use case that branches into multiple flows, the library had no support and railway oriented programming also did not give a solid way to solve our problem. So we leveraged Ruby’s metaprogramming capabilities to dynamically create use cases that could branch. This is the code for the condition base class:
# frozen_string_literal: true
module Steps
module Conditions
class ConditionBase < StepBase
class << self
def inject(success:, failure:)
Class.new(self) do
on_success success
on_failure failure
contract self.superclass.keys_required
adder_for self.superclass.keys_added
.....
end
end
def on_success(use_case)
@__on_success = use_case
ensure_step_added
end
def on_failure(use_case)
@__on_failure = use_case
ensure_step_added
end
def ensure_step_added
return if @__steps.present?
steps :decide_action
end
def success_case
generated_case(@on_success)
end
def failure_case
generated_case(@on_failure)
end
def generated_case(some_steps)
Class.new(SuperUseCase) do
steps *some_steps
end
end
def can_branch?
true
end
end
private
def decide_action(context)
if check(context)
self.class.success_case.run(context)
else
self.class.failure_case.run(context)
end
end
def check(_context)
raise "implement check in #{self.class}. Must return true/false"
end
end
end
endThere’s a lot going on here so let’s break it down:
- The class has an inject method that returns a new use case that copies over the contract and adders from the base class, and sets the instance variables
@on_successand@on_failurewhich are just arrays of use cases on the metaclass of the generated class. - You can see that the base class exposes two methods called
success_caseandfailure_casewhich are generated use cases which have either the@on_successor the@on_failureas the steps. - The base condition also declares that there is only one step in this use case i.e.
decide_action. In the definition, you can see that it calls a method calledcheckwhich has to be implemented by the class inheriting from the condition base.
The concept will become a lot more clear once you see what a real condition step looks like:
# frozen_string_literal: true
class SomeCondition < ConditionBase
contract some_key: String
private
def check(context)
context[:some_key] == EXPECTED_VALUE
end
endA condition in the definition does not declare what happens when it is met or not met, it only defines the keys it needs to check the condition and the condition to be checked. The metaprogramming kicks in when another use case wants to have a condition as a part of its steps.
This is what the end results look like:
# frozen_string_literal: true
module Strategies
class SomeAutomation < SuperUseCase
steps Steps::Queries::GetOrderDetails,
Steps::Conditions::SomeCondition.inject(
success: [
Steps::Fragments::UpdateTicket,
Steps::Queries::GetDriverDetails,
Steps::Actions::DoSomeAction,
Steps::Conditions::NestedCondition.inject(
success: [Steps::Actions::SwitchToAgent],
failure: [Steps::Actions::SolveTicket]
),
],
failure: [Steps::Actions::SwitchToAgent]
)
end
endAs you can see we’ve achieved the following things
- Order independence
- Re-usability/composition as a default
- Increased verbosity and readability of a given workflow
The Future
- A condition is used very similarly to a closure in functionality as the inject method returns a new class that could run either of the two dynamically created flows injected by its caller. This idea can be extended to abstract away steps that share most of the code but differ by some parameter.
- Moving the order of the steps to a database table. Since each step already exposes the keys it adds and the keys it requires.
- Eventually, build a Zapier-like tool that works with all Gojek products and allows creation of custom workflows as long as the logic for what happens in a step is coded.
That’s the journey of how we rewrote our ticket arbitration system to be cleaner and more intuitive. If you liked what you read, consider signing up for our newsletter to have our stories delivered straight to your inbox. 🙌
