When Kafka Went Offshore
Two weeks. Multiple untimely failures. Here's how we improved Kafka streams reliability.
By Anmol Vijaywargiya
Our Engineering Platform team redefines how teams inside Gojek work with realtime events, and powers 250+ applications.
During mid-February 2021, numerous product teams reported untimely failures on producers and lag on consumers. This nightmare went on for two weeks. 😐 When we dug deep and compared all the times this had happened over the past few weeks, we found a common event: Migration of Kafka broker(s) done by Google.
This wasn’t a normal migration, but a live migration. Here, the virtual machine instance is kept running, and it is migrated live to another host on the same zone instead of requiring the VM to be rebooted.
Produce failures were of the following type:
failed to publish message with exception with topic xxxx java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.On the customer front, there were two types of consumers facing the lag
- Ones which auto-recovered after a while.
- Ones the streams of which shut down, and recovery meant restarting the service.
Why and how a live migration could be the culprit was still a big question! 👀
However, there were a few speculations as to how a misbehaving broker could cause lags in consumers:
- Streams were stuck in re-balancing because one of the stream threads died and consumers using Kafka client version less than 2.3.0 could be facing issues because of it. Refer KAFKA-7181.
- Consumers did not implement an UncaughtExceptionHandler and encountering a Timeout Exception killed the thread. However, this understanding was wrong as explained below by a Confluent Engineer.

Time was ticking. We had to figure a way out.
Before I jump into what we did to solve this, let’s understand a few relevant Kafka terminologies.
Partition Leaders and Replicas
Every partition, in ideal conditions, is assigned a broker that acts as a leader and has zero or more brokers which act as replicas, governed by the replication factor. The leader handles all read and write requests for the partition while the followers passively replicate the leader and remain in sync.
Controller
A controller is a broker. A cluster always has one controller present. In the events of the controller going down, the zookeeper elects a new controller for the cluster.
Zookeeper always expects heartbeats to be sent from all the brokers in the cluster and if a heartbeat isn’t received with a certain interval, then the zookeeper assumes the broker to be non-functional. (This interval is governed by ZOO_TICK_TIME which by default is 2000 ms).
So, if the controller doesn't send a heartbeat within the configured time, controller re-election takes place and another broker is made the controller instead.
Also, the controller’s job includes:
- Monitoring the health of all the other brokers in the cluster.
- Mediate the leader election for a partition and announce this to the replicas.
Leader Election
For a Kafka cluster to function properly, every partition needs to have a leader and in the events. If this leader isn’t functional because of some failures, a new leader is selected from the in-sync replica list. Zookeeper is the one that gets to know about these failures, which in turn signals them to the controller which then mediates an election.
Preferred Election
This is an election mediated by the controller to fix the uneven distribution of leaders for the topic. You could read more about it here.
What did we do next?
Our Ziggurat team had now entered the scene and we started discussing/debugging why this could be happening. Since we are the ones who build solutions on top of Kafka’s library, which is then used by the consumers, our findings and fixes were extremely crucial. 😅
We started going through the logs for time intervals in which the consumers went down. Upon rigorous monitoring of all the affected consumers, we found out two prominent exceptions.
- DisconnectException
org.apache.kafka.clients.FetchSessionHandler:handleError: [Consumer clientId=application_id_offset_reset_86be-ea18bbcf-c774-40e3-ba21-aedda1d16004-StreamThread-8-consumer, groupId=application_id_offset_reset_86be] Error sending fetch request (sessionId=91025901, epoch=1235409) to node 1: org.apache.kafka.common.errors.DisconnectException.- TimeoutException
org.apache.kafka.common.errors.TimeoutException: Timeout of 60000ms expired before successfully committing offsets {topic-5=OffsetAndMetadata{offset=1126387, leaderEpoch=null, metadata=''}For consumers whose stream threads died, we saw that the Timeout exception came up for each partition, after which the thread goes into an ERROR state.
By then, we also understood a little about how and why a live migration could cause this. Live migration was observed to have caused network failures on the broker which results in communication failure between the controller and the broker. This leads to the broker getting kicked out of the cluster.
Leader re-election takes place on those partitions for which the broker was a leader creating a leader imbalance in the cluster. Once the broker is back up, it rejoins the cluster, and the controller triggers a preferred election.
If this broker has a very high throughput, the preferred election leads to a delay in recovery and can cause the partition to be leaderless for several minutes. This has also been discussed in KAFKA-4084. This would also lead to timeouts happening on consumer threads consuming from that partition.
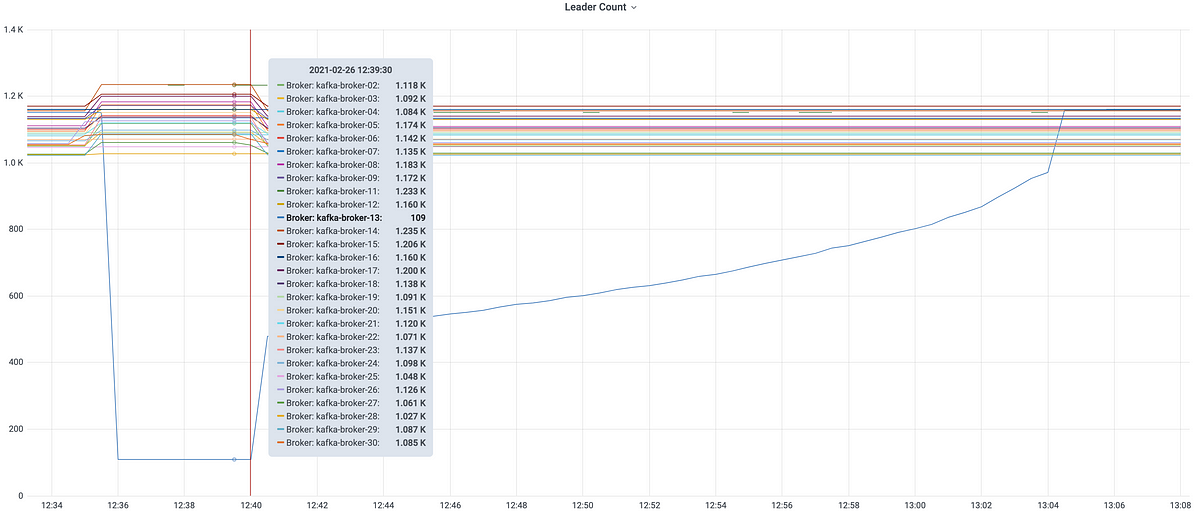
As you can see in the picture below, maintenance had happened on kafka-broker-13 (leader count dropped considerably).
The leader count went down at 12:36, and a recovery started by 12:40. During this period, a lot of consumers experienced lag, and a few didn’t recover. The rate of recovery seemed directly proportional to the time taken by their topic partition which was lead by kafka-broker-13 to overcome the imbalance.
So, the next task in hand was to reproduce it on local or integration, in order to try various Kafka configuration settings to mitigate the issue. The only caveat was that we might not get accurate results because of the variance in load when compared to production.
To speed up, we split ourselves into two pods:
- The first one focused on reproducing the issue on the local machine.
- The second one put all their efforts into reading through the documentation to figure out the best-suited Kafka consumer configurations which could help.
Local Reproduction
Since we already had a docker setup of 1 Kafka broker and 1 Zookeeper, we thought of starting with that.
Steps and observations:
- Ran the Kafka-Zookeeper docker setup locally.
- Produced messages into Kafka.
- Ran a consumer locally, with bootstrap-server pointed to local Kafka.
- Observed that the consumer started message consumption.
- After a while, stopped the container which was running Kafka.
- Observed DisconnectException and TimeoutException in the consumer logs, but also observed that the stream threads didn’t die even after waiting for 20 minutes.
- After bringing the broker back, the consumer started consuming messages by itself.
Also found a similar Kafka issue KAFKA-3468 which tells that consumers do not fail on such scenarios and rather try to fetch the metadata in a loop, forever.
Since we didn’t see any issue with the above setup, we thought of moving on. As our production environment runs a Kafka cluster, we decided to go ahead with a similar setup.
Figuring out the details of setting up a cluster locally sure took some time, but we got it sorted.
To reproduce the issue, we just needed to ensure the partition had no leader for a while and re-election couldn’t take place.
So basically, if the leader is down, and the controller is not able to elect a new leader, the partition would become leaderless. This could lead to Timeout Exceptions on the consumer assigned to that partition.
The immediate question was — How does a controller know when it has to trigger an election?
Like we discussed above, the Zookeeper is the one that signals it to the controller. Hence, the next step was to block communications from Zookeeper to the controller. Blocking the communication is as simple as adding an IP table rule in the controller to block all requests from the Zookeeper.
But, if the Zookeeper isn’t able to reach the controller, it would elect a new one, right?
Well, you might have figured an answer to this already.
It’s ZOO_TICK_TIME! If this configuration is increased to a huge number, then even Zookeeper wouldn't know if the controller isn't functional and hence, a new one wouldn't be elected. Smart, right? 😆

Since we cannot have high throughput like the production in the local environment, going the preferred election route wasn’t possible.
Hence, to reproduce the issue, implementing the above idea made more sense.
Note: The implementation makes use of Kafka-CLI-tool to talk to Zookeeper and Kafka.
Steps and observations:
- Create a cluster using the docker-compose file mentioned above, ensuring
ZOO_TICK_TIMEin Zookeeper configuration is a high value, say 600000 (10 minutes). - Create a topic with 3 partitions and 12 replica-count using kafka-topic.
./kafka-topics.sh --create --topic topic-x --bootstrap-server localhost:9092 --replication-factor 3 --partitions 12- Produce messages into
topic-x - Run a consumer consuming from the topic specified above and see that it’s consuming the messages
- Find the Kafka controller’s broker id by running the following command using zookeeper shell
./zookeeper-shell.sh localhost:2181 << get /controller- Exec into the broker’s container found above and put a rule in the iptables to not accept requests from Zookeeper
-A INPUT -s -j DROP- Observe that the new controller isn’t elected even after waiting for 5 minutes. Kudos to the high value of ZOO_TICK_TIME
- Find a partition, the leader of which isn’t the controller. This can be found using kafka-topics
kafka-topics.sh --describe --topic topic-x --bootstrap-server localhost:9091- Stop the broker using docker stop <container_id> (Container ID can be figured out using
docker ps -a) - Keep monitoring the consumer’s logs. You’ll see disconnect & offset commit timeout exceptions. In about 5–10 minutes, the streams will shut down
- Getting the leader back up didn’t restart the message consumption either
Resolution
Let’s go through all the configurations the second pod believed this issue could be solved with.
- retries
- session.timeout.ms
- default.api.timeout.ms
retries - The number of retries for broker requests that return a retryable error. Since DisconnectException and TimeoutException are both, a type of Retryable error, we thought configuring retries to a high value would solve it.
session.timeout.ms - The timeout used to detect client failures when using Kafka's group management facility.
The client sends periodic heartbeats to indicate its aliveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove this client from the group and initiate a re-balance.
default.api.timeout.ms - This configuration is used as the default timeout for all client operations that do not specify a timeout parameter.
Since we didn't find any configuration for offset commit timeout, we believed the default API timeout would be in use for offset commit as well.
Before starting experimentation with the configurations, we also set an UncaughtExceptionHandler and added a log just to gauge the exception which causes the stream to die.
Observations for each of the configs:
retries - Retries somehow didn't have any effect on the timeout. We observed that the number of times we received the timeout exception on a consumer is always equal to the number of partitions irrespective of the number retries were configured to.
session.timeout.ms - In our case, since the consumer was shutting down completely, the session didn't matter and hence this config didn't help at all.
default.api.timeout.ms - We observed that if the value of this config is greater than the time it takes for the cluster to stabilize, the streams do not die and start consuming messages once things come back to normal.
Knowing default.api.timeout.ms worked, we tested it out on integration and intimated all the stakeholders about it. Hurray!
Apart from figuring out the right consumer config, we realized that since live migration is the one creating all the fuss, we updated the migration policy from migrateOnHostMaintenance to terminateOnHostMaintenance and also set compute.instances.automaticRestart to be true.
Shutdown and restart would mean a faster preferred-election. Since Kafka is a highly available setup, one broker being down for a few minutes will not have much effect.
Thus, after a week of rigorous efforts, we were FINALLY able to figure out a viable solution!
The positives
The last week of February was THE WEEK when we got to learn a lot about Kafka.
This was also the week, where the whole team paired together all the time, which in turn contributed to strengthening the bond.
Kudos to such production issues! 😉
In conclusion…
Kafka in itself is a mammoth. A new version gets released once every quarter and one has to stay updated by being on top of the documentation and release notes.
What we also learned with this outage is, the default configuration which Kafka provides isn’t always good enough to run production systems at scale.
There is no perfect configuration and one needs to tweak them repeatedly to figure out what works for their systems.
Helpful Links
https://betterprogramming.pub/a-simple-apache-kafka-cluster-with-docker-kafdrop-and-python-cf45ab99e2b9
https://bravenewgeek.com/tag/leader-election/
https://kafka.apache.org/documentation/#consumerconfigs
https://hub.docker.com/_/zookeeper

To read more about how we build our #SuperApp, click here. To build it with us, check out the link below:
