Using job queues in Go for resilient systems

By Soham Kamani
The job of any application, to put it bluntly, is to do things. Sometimes, those things may take time, and the application cannot wait to make sure they are done. But still, it’s necessary that they are.
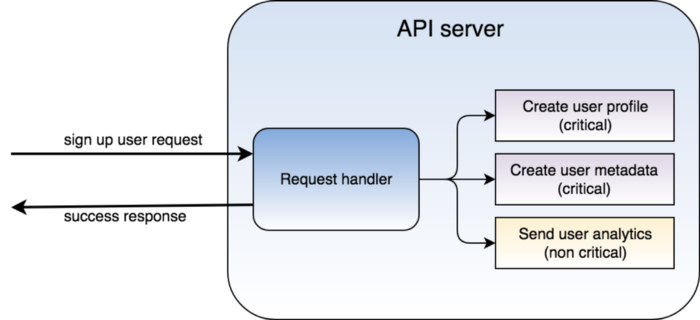
I’ll explain this with an example: For any new user who signs on our platform, we create multiple profiles for our different services. We give every user an instant confirmation as soon as their signup is successful.
A few problems arise if we treat this as a synchronous problem:
- How can we give the newly signed up user an instant confirmation if the profile creation takes time on our systems?
- If we decide to give the user a confirmation (which is instant, but assumes that all profile creations will be successful), then how can we ensure that all profile creations are, indeed, successful in the backend?
Jobs, and batch processing
Whenever there is a need to do a bunch of tasks after the occurrence of some event (in our example, this event refers to a new user signing up), we can treat each task as a “job”. A job is not part of the response to the event that took place (the response, in our example was the instant confirmation we gave to our user of their successful signup), and takes place asynchronously. It’s important for us to classify jobs based on their importance:
- Critical jobs are those that cannot afford to fail. In our case, if a new user signs up, we cannot afford to skip their profile creation in any of our services. Another example would be sending the user a notification when their GO-RIDE arrives.
- Non-critical jobs like sending user signup statistics to our analytics service, or sending promotional notifications to a user, can afford to fail. (of course, we strongly prefer that they don’t 😅. But only talking about what’s absolutely essential and what’s not)
Another way to look at this: In any system we design, non-critical jobs should not fail, and critical jobs cannot fail.
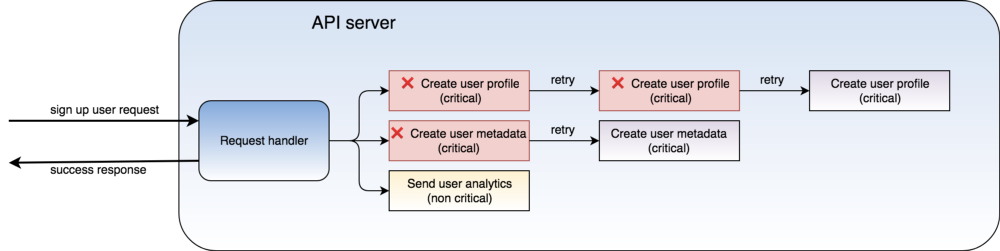
One simple mechanism to make sure jobs don’t fail is to retry them when they do. This may work in smaller systems, but problems arise once you start to scale:
- If too many jobs fail on a single system, they start to build up. And as they do, systems can run out of resources.
- If the machine itself fails, then all jobs that were running, or supposed to run on it, fail as well.
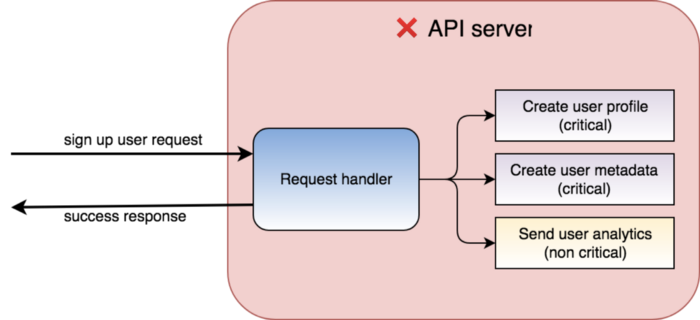
Both of these scenarios are unacceptable.
Job queues
The solution that we use to solve most of our batch processing woes is to set up a worker queue. The way we do this is to have a description of the job itself pushed onto a queue that resides on a different process from the job creator (or publisher). We then create workers that subscribe to the job queue and execute each job in a sequence.
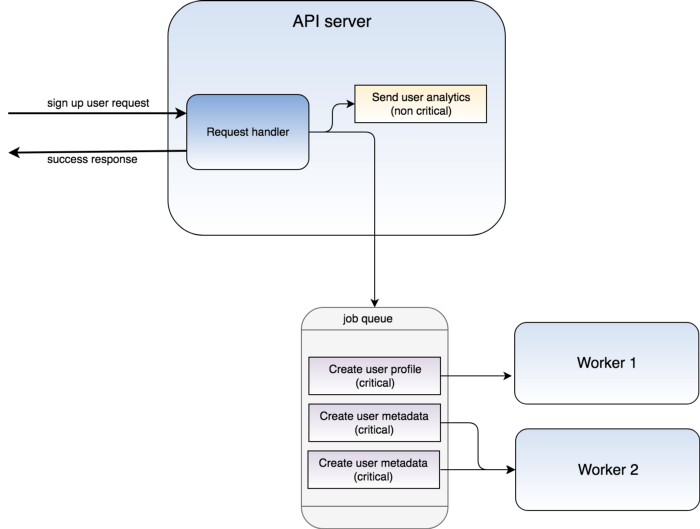
Implementing this kind of a job queue solves a lot of problems for us:
Resiliency
Once we have a job queue running, we protect ourselves from job failures as well as application failures. Messaging queues like RabbitMQ have an acknowledgement mechanism, which clears a job from a queue only once it’s acknowledged (or optionally re-queued when negatively acknowledged).
Job failures are handled by negatively acknowledging the job, which will then be re-queued and handled by another worker.
If the worker itself fails while processing jobs from a queue, those jobs will simply not be acknowledged at all. Instead, it will be redistributed if the connection between the worker and the message queue closes.
You can make the jobs resilient by using redundancy among messaging queues. This is implemented in frameworks like Apache kafka. This ensures even if the job queue itself fails, it won’t lead to the jobs not being done.
Scalability
By moving the workload to another process, it’s now possible to scale out our workload. If we find that there are too many jobs and they’re not getting done in time, all we have to do is increase the number of worker processes to accommodate the workload.
We can do the same thing with the job publishers if we find that the number of requests are more than we can accommodate.
Load distribution
By separating the place at which event creation requests are received, and the place at which they are processed, we have essentially distributed the load. This way an increase in load at one end will not affect the system at the other end.
In our case, this means if there is some delay that affects profile creation on our services, it will not affect the response time or the experience of the user signing up. We make these two processes mutually exclusive, as they should be.
Implementation in Go
Let’s try to see a simple job queue in action, by building it with Go, and using RabbitMQ as the message queue. First, download and install RabbitMQ on your system. Once that’s done, we can start writing our Go application.
First, we’ll create a queue package, which will export functions to initialize, publish and subscribe to the queue:
Next, let’s create a publisher in our main package. This publisher is going to publish “jobs” in which we need to add the two numbers given to us. This will be published as a set of comma separated numbers (which are the numbers 1 and 1 in this case):
This publisher makes use of the Publish function that we defined in our queue package earlier. Similarly, let's make a subscriber process the workload.
The subscriber will consume the payload that we send out from the publisher, and print the sum of its numbers:
Finally, we can make our main function to either start the publisher or the worker, based on the command line arguments:
You might have to change the RabbitMQ connection string passed to queue.Init based on where your RabbitMQ instance is hosted.
You can find the complete working code here.
Running the implementation
Once you have the code in place, and a running RabbitMQ instance, start a new worker by running:
go run main.go workerNext, start a new publisher by running:
go run main.go publisherThe publisher pushes a new job to the queue every half a second. You should now see the output of the jobs appearing in the worker window. To demonstrate how this system scales, try starting another worker. You should see the output on each of the worker windows appear twice as slowly, which shows the job workload (which appears once every half second) being distributed between the two worker instances (which will appear as the worker showing the output once every second).
Add more workers, and the workload will automatically distribute itself. You can play around with adding, removing workers and publishers and seeing the rate of output.
Conclusion
There are many more patterns and architectures to handle larger and more complicated workloads. To handle a simple workload at scale, we found that implementing a job queue works really well. It provides us with a robust and scalable solution to handle critical tasks asynchronously.
If this is interesting and you want to know more, grab your chance to work with GO-JEK! We’re expanding and hiring the best minds in the industry. Our payments arm, GO-PAY, does comparable transactions to India’s largest wallet. Check out gojek.jobs for more.