Upgrading PostgreSQL At Scale
Preparation, process, principles: Everything that went into upgrading PostgreSQL.

By Vishwesh Jainkuniya
PostgreSQL is one of the most commonly used relational databases in the recent times, with over 30 years of active development which has earned a strong reputation for reliability, feature robustness, and performance.
Thus, as the development continues, we get more and more features, and to use them, we have to upgrade. Sometimes it’s a minor upgrade, which can be performed on the fly and sometimes it’s a major upgrade, which requires attention and should be carried out carefully.
PostgreSQL 10 was released with Declarative table partitioning, which simplifies many use-cases. So, in order to take advantage of it, PostgreSQL should run on ≥ 10. But our app was already running with an older version of PostgreSQL, having hundreds of millions of live tuples and serving hundreds of thousands of live traffic. This blog talks about our experience upgrading core PostgreSQL databases.
The process
But first… Here’s a little background: PostgreSQL supports master slave replication and it’s highly recommended to use the same. It gives read/write separation out of the box and we shall leverage it in this upgrade.
Below is what the current setup looks like, where we have the app running either on VMs or Kubernetes, connecting to the database.
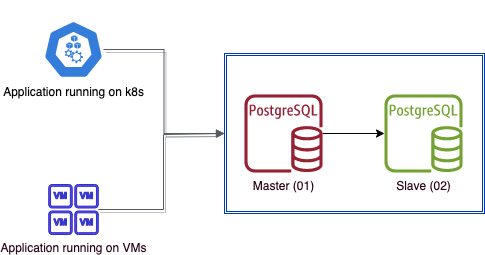
The preparation
Since meddling with production databases is always risky, it makes the most logical sense to have a backup. We leverage PostgreSQL replication and setup two cascading slaves which will be our new master (03) and slave (04) post upgrade. As it is a streaming replication, these two new instances should be running the same major version of PostgreSQL. To be on safer side, one can also take disk snapshots of current PostgreSQL instances. Install newer PostgreSQL on 03 and 04 in the preparation step.
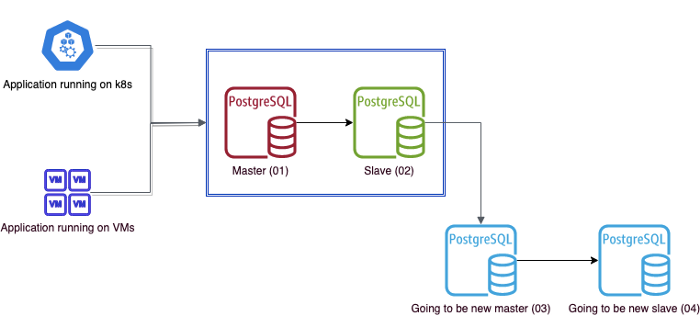
Depending on your database size and network bandwidth, it will take some time to create snapshots and to catch up replicas with master. Here’s one way to setup replication using pg_basebackup.
⚠️ Make sure to tune PostgreSQL configs on new master/slave. At that instance since they don’t have any traffic, restart won’t cause any downtime.
Once the replicas are up, start the upgrade process.
👉 We will be scaling down all the application pods running on k8s (and VMs).
👉 Ensure no writes to current master (01).
👉 As a verification step compare Log Sequence Number (LSN) across 4 instances.
👉 Then, promote new master (03) to master and run pg_upgrade on it, and start upgraded PostgreSQL server on the instance (03).
The master is now ready with upgraded PostgreSQL, but slave is still on older version. pg_upgrade doesn’t work on slave.
So how do we upgrade slave?
One way to go about this is, since we have upgraded master (03), we setup another replication. But depending on your data size, it will take longer to catch up with master.
pg_upgrade provides an option of linking ( — link) old PostgreSQL cluster data with the new cluster instead of copying data to the new cluster. Thus, pg_upgrade will be quick on master. In addition, we need to somehow perform similar linking on slave as well to run newer clusters on it. Hence, we take help from rsync to achieve this.
rsync is known for its extraordinary speed of copying data.
We shall be running rsync on data directly from master (03) to slave (04). Once we have the same linking on slave as well, we can begin the new upgraded cluster on slave and it will start replicating from the upgraded master (03).
As a verification step, check for the Log Sequence Number (LSN) on new master (03) and slave (04), and it’s a good practice to verify PostgreSQL logs as well before scaling up the application.
📝 Note: At any stage, if LSN doesn’t match, don’t work check again. Keep en eye on PostgreSQL logs and look for any error.
Voila! we have upgraded PostgreSQL 🎉
Here are the five simple principles, which are crucial while working at scale. These rules helped us in carrying out the whole process effortlessly and the upgrade was achieved with minimal user impact and overall downtime of 15 mins.
Have a playbook
Best way to be confident about your plan is to jot it down and list all possible tracks migrations that could happen. We hadn’t meddled with existing master/slave, so if anything went wrong while migrating, at any step, we could just scale up the application with the existing master/slave setup. So, list all the things that might go wrong and prepare for the rollback and fallback.
Have a playground
Production environment is not made for experiments. Create a playground locally to rule out all confusions and come up with a concrete playbook.
How should I make sure that my playbook is sufficient?
The playbook needs to be self explanatory. It should contain all information on when to do what, listing all the commands step by step. Most importantly, one should be in a position to handover this playbook to anyone and they should be able to upgrade it on their own without asking any questions.
Define concrete rollback strategies
Even after multiple mock drills on the playground, there can be things which might come up while performing it in production. Like connectivity issues, VPN or with the person who is handling the task. It’s recommended to have a backup who can take over in case of such issues.
There could also be a situation where your production environment configs differ from playground. So, be prepared for all such scenarios and make note of them in your rollback section.
In our case, we were not even actually intervening with live master/slave. So in case of any issue, we could just abort the process and scale up the application.
Minimise user impact
Upgrades are not rare scenarios. Taking downtime always is not a good idea since it impacts businesses and the moment the user sees an error, the product is deemed unreliable.
Introduce one new component in between the app and the database, which will be responsible to serve while the database is being upgraded.
Depending on your use case and flow criticality, it can be a simple Redis instance which will sync back to the database once we have the upgraded database. Or it can be any queue/log like RabbitMQ/Kafka, which take requests and queue them up. Once the database is up, it can be experimented on. Both require additional component setup, like workers.
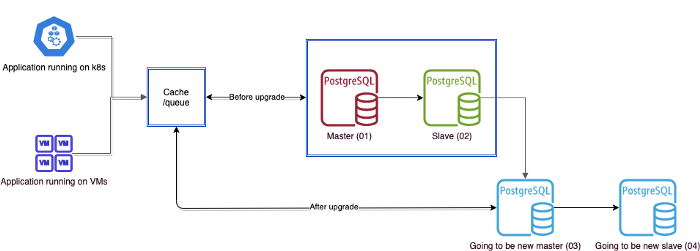
Prepare indigents, scripting
Upgrade process involves running multiple commands across instances, like scaling down application, promoting to master, checking LSN etc. It’s better to create scripts which will take care of all these steps one by one and you just need to confirm. Something like IVR, enter 1,2…
They can be simple shell scripts or Ansible or anything else you’re comfortable with.
End notes:
Leaving you with some useful PostgreSQL commands:
Promote to master
# pg_ctl promote -D /data/dir/path -t 60Check if PostgreSQL instance is salve mode
# select pg_is_in_recovery();Get current LSN on master
# SELECT pg_current_xlog_location(); < 10 // for PostgreSQL < 10
# SELECT pg_current_wal_lsn(); // for PostgreSQL >= 10Get last received LSN on replica
# SELECT pg_last_xlog_receive_location(); // for PostgreSQL < 10
# SELECT pg_last_wal_receive_lsn() // for PostgreSQL >= 10
Click here for more stories about how we build our Gojek #SuperApp.
Click here if you’d like to build it with us. 💚