The Story of Our Big Android App Rewrite
The steps we took to overcome inefficient architecture and sub-par design to give our driver SuperApp a much-needed overhaul.

By Aritra Roy
The Gojek SuperApp is an ecosystem of 20+ products and our 2 million+ driver-partners form the backbone for most of them. While most of you may know about our consumer-facing SuperApp, our driver app is very much a SuperApp in its own right.
Driver partners depend on this app to earn their bread and butter, and the responsibility of maintaining this app lies with Gojek’s Driver Platform team — which I am a part of. If the app doesn’t work as expected for even an hour or two during peak business hours, our partners would lose a significant amount of income for that day. Not a responsibility to be taken lightly.
This is the story of our big driver app rewrite, in which I’ll share why we took this initiative, how we planned and executed it, the challenges we faced, the mistakes we made, and everything we learned in the process. I will also talk a bit about our team, our culture, the principles we follow, and the processes we built — all of which contributed towards making this a success.
Prologue: To New Beginnings
The idea for the rewrite was born sometime in early 2018. The reason: even though our app was functionally strong, there were a few important areas where we were lacking:
Design
From a design standpoint, our app looked quite dated and boring. Our consumer-facing apps looked way more refined, polished, and modern than our driver app.
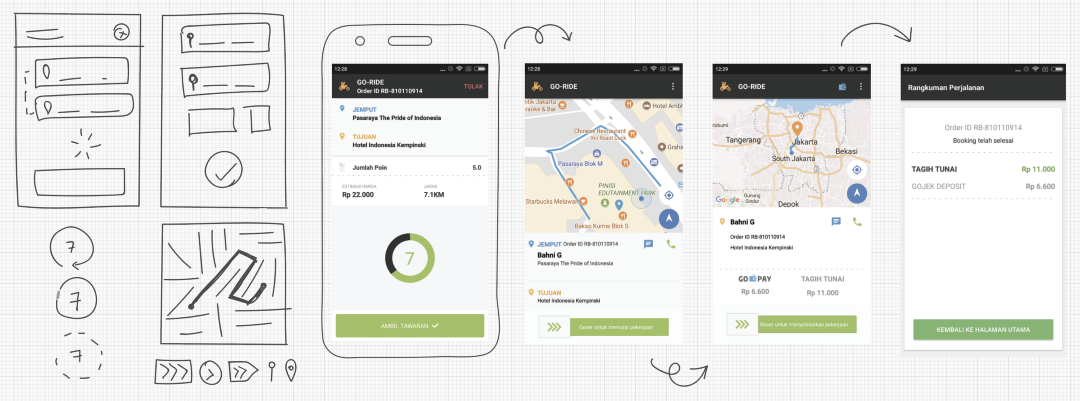
Clearly, our app was desperately in need of a complete makeover. We wanted our drivers to have an equally good user experience as our consumers.
Tech
From a tech standpoint, there were some serious issues as well. Our app didn’t have a consistent and well-defined architecture in place. It was a pretty old legacy codebase we were working on. Things were quite cluttered (to put it lightly), which not only made it difficult to develop new features, but also to maintain existing ones.
With the existing architecture, it was quite difficult to support the scale at which Gojek was growing at the time.
Experience
And lastly, from an experience standpoint, things were not at their best as well. Here I am referring to the smoothness and stability of the app, and how efficiently it runs throughout the day.
For the driver app, there are a few unique challenges that made things a bit difficult for us:
- It is used by drivers on very low-end devices (512MB of RAM is not uncommon)
- It is used continuously by our drivers for 10–12 hours every day
- It needs to be battery-efficient and not drain the devices’ battery rapidly. Drivers have a tough time charging their phones multiple times a day,
- It needs to consume minimum network data and work in areas with poor network connectivity as well

These are some of the many challenges that make it quite difficult to provide an excellent and consistent user experience to all of our drivers across all devices and OS versions.
How It All Started
All of these things were bugging us for quite some time and we desperately wanted to do something about it. Making minor tweaks in our legacy codebase was not going to solve these problems. We needed something big, something fundamental — a “rewrite”.
The team was unanimously convinced that we needed a big rewrite. But we were not sure as to how we were going to pull this off given how big our app was and the new features we were continuously adding.
Approach #1: The Big Bang Rewrite
Initially, we were swayed by the idea of taking a fire-break and stopping all active development for a few months. We could use this time to work on rewriting the app and making it feature-neutral with what we already had.
Sounds stupid? Yes, it was.
Our app at that time was quite huge, consisting of a lot of features and user flows for different countries and services.
A quick estimation showed that it was nearly impossible to rewrite the entire app in 6–8 months, maybe even a year. And these were still highly optimistic estimations.
Positive people tend to overly underestimate things.
Also, not being able to build any features during this time would have a significant impact on our business which was something that we were not ready to afford at any cost. We wanted our tech to support our business and not jeopardise it.
So, this idea quickly went off the table.
Disclaimer — Big bang rewrites are not always bad. They do work sometimes depending on what stage your project is in or how big it is. If your project is small enough to be re-written in 2 weeks, sure, go ahead.

Approach #2: Progressive Reconstruction
We decided to redesign and rewrite the app incrementally, one feature at a time, making sure we do not stop any active feature development that our business needed.
But wait, what? This was like chasing a moving target where we will never be able to completely rewrite the entire app.
We decided to modify this idea slightly — we would dedicate approximately half of our resources towards rewriting the old features while the other half would continue building new features following our new design language and app architecture.
In this way, we would eventually be able to re-model (re-design + re-architect) the entire app.
We would also be able to make it to the market quickly, get early feedback from our drivers and make quick improvements. It was very important for us to make small but frequent releases so that we don’t get intimidated by the prospect of a big release.
Release early, release often. Be quick to the market.
This sounded like a solid plan for success and we decided to move ahead.
Getting The Foundation Ready
We knew we had a long journey ahead of us, so it was important for us to plan it thoroughly, right from the beginning.
We decided to start by rewriting the home screen and the booking flow of our app. Though the driver app has a lot of features, the booking flow is the core of it.
If you have a long journey ahead, make sure to plan it right.
Analysis
We took a few weeks to analyse how our tech stack would look, what architecture we were going to use, etc. We also had to think of properly managing the legacy code along with the new code in the same codebase.
It was important for us to ensure that our new code does what our existing code already did. As we were not the original authors of the existing code, it was difficult for us to get the edge cases right. Ideally, the existing code should have served as a spec and guided us on the rewrite, but in reality, this was far from the truth.
Make sure your new code does what your existing code already did.
As we were going to rewrite only a part of the codebase, we had to make sure that the existing features were perfectly compatible with the new ones. We needed to keep this compatibility layer simple and clean so that we could easily remove the legacy features in the future.
The idea was to cover as much as possible during this analysis phase and make sure that we set the sail in the right direction. But we also made sure to time-box this and not run into “analysis paralysis”.
If you spend too much time thinking about a thing, you will never get it done.
Estimation
This operation required a clear idea of when we would be able to release this new design to our drivers, so that we could align our business, operations, and other dependent teams accordingly. We defined the operation into clearly-defined granular tasks with individual estimates, figured out dependencies, and allocated developer bandwidth accordingly.

Under-The-Hood Stuff
As we had planned an incremental and parallel rewrite, we wanted to get some foundational stuff ready before anyone could start working on anything.
This included building things like a networking layer, data persistence layer, event tracking library, remote toggle management library, utilities for easier screen navigation, animations, runtime permissions, logging, and a few essential domain-specific utilities.
There are a lot of custom requirements that we have in Gojek. So it was important for us to get the foundation rock-solid so that both the development streams could benefit from it.
Stop Making It Worse!
Before we started the rewrite, our goal was to make sure we don’t end up doing another one anytime soon. In an ideal world, there would be no deadlines and engineers would have an infinite amount of time to polish things, but then reality kicks in and tech debts start to accumulate.
To avoid this, we decided to refrain from cutting corners to meet deadlines. We wanted to make our analysis, estimation, and prioritisation better so that we don’t end up fighting tight deadlines every now and then.
If you are fighting deadlines often, then the process is broken somewhere.
In reality, it is almost impossible to entirely avoid tech debt, but our strong stance on repaying them quickly helped us maintain our codebase in a healthy state.
What’s On The Tech Side
Now, let’s have a look at the tech side of our app.
As I had mentioned before, we were working on a legacy codebase which was written years back in Java. There were a lot of fundamental problems in the codebase which made it incredibly difficult and time-consuming to add new features and maintain the existing ones.
Making even a small change turned out to be a painful experience for our developers. We were also seeing rapid growth in the number of contributors to our codebase every day, but unfortunately, the architecture was not ready to scale with it.
Architecture
We explored a variety of mobile architectures and finally decided to go ahead with Uncle Bob’s Clean Architecture. There is always an endless debate among Android developers on which architecture is better and quite a few of these happened in our team as well.
But in the end, we wanted to keep things simple and stick to the basics. There is always more than one way to skin a cat, but what matters in the end is how happy your end-users are using the app.
Objectively, we had a few fundamental principles that we wanted our architecture to satisfy:
- It should be easy to write exhaustive tests for our app
- It should be easy to maintain over time and debug issues
- It should be simple to understand and contribute
- It should be flexible enough to be evolved easily with future business requirements
- It should be easy to scale for future expansion
Our architecture consisted of four main layers — data layer, domain layer, presentation layer, and the UI layer.
The “data layer” talks to the framework directly and is responsible for managing all data-related operations in the app like making network calls, accessing the database, reading/writing files, etc. We use the Repository Pattern in our data layer to manage multiple data sources easily.
The “domain layer” is responsible for holding the business logic. We ensure that this layer has pure Kotlin code and we do not introduce any framework related dependencies in it.
After that, we have the “presentation layer”, which takes care of all the presentation-related logic in our app. We try to keep all these layers free from any framework dependencies so that we are able to exhaustively unit test them.
We finally have the “UI layer” which mostly comprises of the activities, fragments, and other custom views. This is the layer which the user can directly see and interact with. We try to keep this layer as dumb as possible and push all of our logic to the other layers.
Components
The idea behind it is quite simple but it has proven to be quite useful for us in reusing both UI and logic across multiple screens in a consistent and efficient way.
A “component” is nothing but a collection of UI elements combined with some business logic that can be rendered in a particular area of the screen and reused across multiple screens.
Every component has a 1:1 mapping with its presenter, which in turn can communicate with the domain and data layer to get its job done. It can define its own set of dependencies and request for other dependencies from its parent (or host). It can optionally also be aware of the lifecycle of the host containing it as well.
Reactive Programming
We make heavy use of RxJava in all the layers of our architecture — data, domain, presentation, and UI. We try to model most of the operations as reactive streams where each layer does some processing and manipulation on these streams and passes on to other layers.
Over the years, we have realised the benefits of Rx as it has helped us perform many complex operations quite easily while keeping the code consistent, flexible, and easy to understand.
Testing
We expect our developers to write exhaustive test cases for every feature they build. It is not possible to merge any pull-request if the test coverage requirements are not satisfied in our CI pipelines.
In our architecture, we try to keep almost all of our logic (data, domain, and presentation) in their respective layers and keep the UI as dumb as possible. This helps us in writing fast unit tests for each of these layers exhaustively and get away with writing fewer instrumentation tests to cover the UI layer.
This also helps us get faster feedback during development as we can run our unit tests (a few thousand of them) in a few minutes before committing any code change. Apart from having unit and instrumentation tests, we also have our automation suite consisting of end-to-end tests that are written and maintained by our QA team.
There are a lot of things from our tech side that I won’t be able to go into detail in this blog, such as our move towards a Single-Activity Architecture, our CI infrastructure, how we run code quality checks, unit, and UI tests and some of our in-house tools for every commit and merge request. We’ll address these in future posts.
Remember Those Deadlines? We Missed Them 🙈
The release date was near, but we were not production-ready yet. In spite of spending months redesigning the app, we missed the deadline. This also had an impact on our business as there were many other initiatives that were planned based on this.
As a team, we decided to do a “retrospective” on it. No heated arguments, no blame game, just a bunch of people sitting together in a room trying to understand what went wrong and what we could have done better. We took it as an opportunity to learn.

We knew there was a long journey ahead, not just for this redesign but for many more things that we were going to build together as a team.
It is in tough times like this, that you understand the true values of your team.
A few important aspects had been missed during our analysis, and we had also underestimated the effort required for a few things. Estimations are hard, really hard, and it takes time and experience to get it right.
We re-estimated (this time more accurately) and set a new deadline. Even though we put a lot of effort and hard work in achieving this new deadline, we still made sure it was a realistic one. This was to ensure no one had to end up working late nights or on the weekends to meet unrealistic deadlines.
That’s not the kind of culture we wanted to build. 🖖
Release It!
Finally, we were ready to release the new design to our driver partners. We started by rolling it out to a small group that were a part of our beta program.

A Few Things We Incorporated
Feature Toggles
For a long time, we have been making heavy use of feature toggles in our app. Almost every feature we build is kept behind feature toggles which enable us to control the rollout of a feature in a variety of ways.
We can incrementally roll-out a feature, or roll it out to a specific group of pre-defined users, or a group of users dynamically selected based on certain properties. We can even roll-out a feature in a particular country, city, or a small area inside a city — like an airport, mall, etc.
There are a few more use cases in our app where we leverage feature toggles. We have even built a few in-house feature toggle management tools to meet our custom business needs.
Monitoring & Feedback
We initially rolled out our redesigned app to a specific group of drivers and gathered some initial feedback directly from them. Our drivers were ecstatic to see the refreshing new design and loved the fast and smooth experience of the new app.

The new design, though significantly different from the existing one, was very well accepted by our drivers and quickly went viral across various driver groups, forums, etc. in social media. We also took the feedback received from our drivers very seriously and made several UI/UX improvements in the app based on that.
Here’s what the redesigned app looks like:
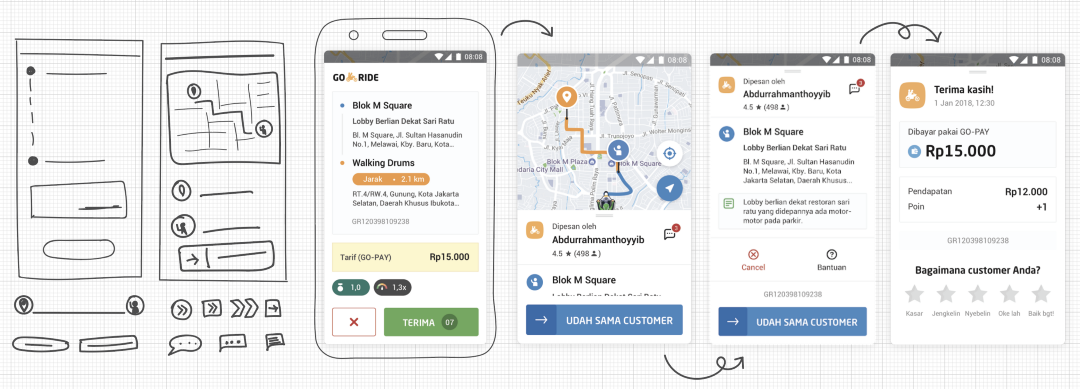
We kept on slowly increasing the rollout and monitored the key business and tech metrics. Not everything was sunshine and rainbows in the initial phases of the rollout though. As we were trying to scale up, we did face a few critical issues because of which we had to halt the rollout, fix the issues, and release hotfixes.
Since then we have been putting a significant amount of effort into tightening our manual, automation QA, and overall development process so that we can prevent these issues from slipping into production.
Performance Matters!
We put a lot of focus on the performance of our app and consider it a first-class citizen in our ecosystem. Our app needs to work well in some of the most low-end devices on the planet and that too for 10–12 hours every day.
We also have quite a few time-critical flows in the app where even a second or two of delay could potentially leave the feature almost unusable. Over time, we have seen many performance issues making their way into the app and breaking functionality in production.
It became incredibly difficult to debug some of these issues reported in production. We wanted to improve the visibility of these performance issues and catch them before they make their way into production, as well as build tools to collect data and help us debug issues that did make it to production.
Over the years, we have built multiple such tools and currently have a dedicated team inside our Driver Platform team whose primary focus is to invest more in tooling and automation to make sure the performance of our app is maintained across every single release.
Epilogue: The Journey Continues…
We had successfully redesigned and rewritten a major portion of our app and rolled it out to 100% of our driver partners in production, but the journey was not over yet.
Our driver app codebase is massive and there were still a lot of features waiting for their turn to be rewritten. We made sure that all of our new features were being developed in the new design and architecture while we kept on prioritising the old features one by one and continued rewriting them.
As we were incrementally rewriting the app, we were always carrying the baggage of both the old and the new code together in the app. It was also very important for us to make sure that we deprecate support for the old features and remove them completely from the app once they have been rewritten and released to 100% of the driver partners.
This rewrite was one of the biggest projects undertaken by our team. It was a long journey filled with a lot of challenges, but it definitely was a rewarding one for sure. We were finally able to give our valuable driver partners an app experience we could be proud of.

Our codebase was now ready to scale, not only in terms of supporting bigger and more complex features, but also in terms of the rapidly growing number of developers working on it.
We had a chance to learn a lot during this journey and grow together as a team. It was never going to be easy, but where’s the fun in doing something that’s easy anyway? ✌️
