The Dynamics of Scaling an Organisation
.

By Misrab Faizullah-Khan
At GO-JEK, I had the privilege of scaling a Data Science team from a few members in one location, to about 30+ people across three countries.
This, and past experiences have helped me come to certain preliminary conclusions on how teams best function. This is my version of “general theory of organisations”, if you will. 😉
In this post, I’ll try and discuss relatively general ideas, as opposed to details that apply specifically to data science teams. It’s also most definitely a work in progress, and I’m more than happy to be proven wrong on certain points, and refine these views. It’s not meant to be a comprehensive theory, but hopefully contains some nuggets of wisdom. I highlight certain concepts that I think serve as crucial mental checkpoints in the framework.
My favourite characterisations of organisations are “just a bunch of people working together to create a product or service”¹, or “information processing systems”². In other words, there are one or multiple goals to achieve beyond what a single individual could output, so a group was formed. Simply put, organisations are a solution to the scaling of a problem. So let’s start by talking about how we can scale them optimally to best address scaling of challenges.
Scaling
I like to think of scaling as depicted in the diagram below. Output is typically related to the product or service of the organisation. It can be represented at different levels of granularity³, or relate to different objectives; such as low
staff turnover or morale.
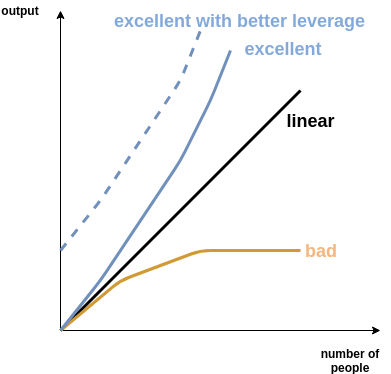
I would argue most organisations encounter diminishing returns to scale, or the “bad” line. Incremental team members contribute less and less marginal productivity as complexity and communication bottlenecks arise. In fact, even scaling output linearly with respect to team members is probably quite a feat. Hopefully, this feels anecdotally intuitive to you: ever felt the difference between having a 3rd member on a project, versus a 20th?
However, imagine an organisation that was able to achieve increasing returns to scale labeled as “excellent”. This team would experience network effects as it grew (presumably within reasonable bounds?). If it were a company, it would leave the competition in the dirt. Think it’s only a theoretical proposition? I disagree.
I’ve seen and built teams where adding a novel skillset to a homogeneous group was like rocket fuel for productivity.
And it gets better: one can presumably both shift these “excellent” levels of output upwards (dashed line), and increase their slope, by improving leverage — tools and processes that enhance individual productivity, and team communication. More on this in a bit.
Organisations as a Graph
It helps in many ways to view organisations as graphs; made up of nodes and edges. Typically, nodes would represent individuals, and edges would represent interfacing/communication between them. It may make sense to view multiple individuals as a node under certain circumstances. For example, when communication overheads within that team is genuinely negligible, or when we’re modelling at a lower level of granularity.
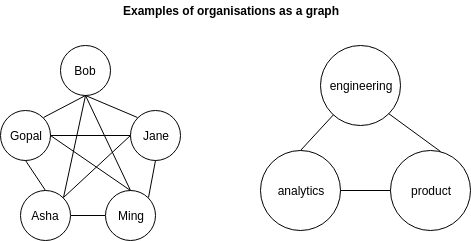
Remember: organisations are a way to scale output. From a graph perspective, stuff happens at two places in the org: within nodes (1), and at edges, the interface of nodes (2). So these are the two dimensions we can optimise. Let’s consider one at a time.
Optimising on the node level (1) is a bit more straightforward, regardless of whether the node is an individual or an extremely tightly knit group. It involves things like:
- Keeping the individual(s) motivated. This can range from compensation to a holistic Maslow approach.
- Tools to be productive e.g. software, non-communication processes.
- Efficient information dissemination (a whole section on this later)
- Career growth and guidance.
- Clarity of purpose. Output can definitely be low if one is targeting the wrong output!
- Self-development: learning skills, design thinking. A lot of this rests on the individual’s own imperative
There seems to be more literature addressing (1), so I’ll spend more time on (2): optimising communication. Many believe, (including me once upon a time), that communication structures are a reflection the underlying product being built. If we’re building a web application for businesses, one might expect a certain divide between an engineering team focusing on the tech, and a business team focusing on corporate clients. If one component of the product is a recommendation system, one might expect a separate data science team working on this, with perhaps limited communication with the other teams (relative to internal team communication).
I believe it was Alan Kay who argued the exact opposite: it is in fact underlying communication structures in an organisation that chiefly determine the product (although there is of course feedback). I personally call this the process-product paradox. This seems counter-intuitive, but increasingly true from my experience.
Consider startups, whose products often directly reflect the founding teams’ identities in the early days. Or consider the previous example, where we now divide the org into three teams: one with mainly engineers, but a couple of data scientists and business folks. Likewise another team with mainly business folks and a few of the others, and so on. What I argue would result is a product that solves business problems, informed by what’s possible through tech (perhaps even things that don’t yet exist on the market), with indeed a recommendation engine, but also fundamental personalisation built in throughout. Not bad for a paradox.
So we get it. Communication patterns are important. Let’s explore how we can organise these patterns, reduce their overhead, and improve quality.
Edge Scaling
If you’re not familiar with Big O Notation, here’s some of the best advice I’ll ever give you in life: spend the next ten minutes understanding it. Seriously. It’s a way to think about scalability in any field, and the world would benefit tremendously if people in all domains, from politicians to scientists to artists understood it better.
Consider a dense or complete graph. How does the communication overhead (edges) increase as we increase the number ’n’ of people (nodes)? In the complete case, you connect the first node to all others. The next node has one less connection to be made, and so on. We calculate the sum:
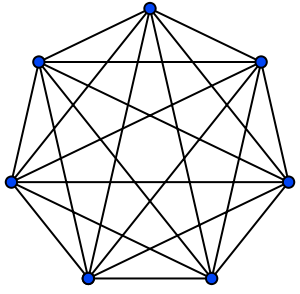
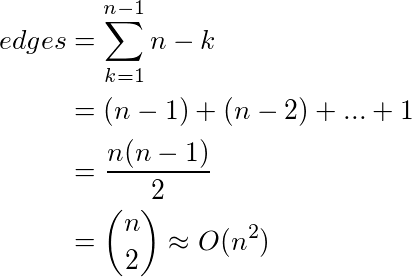
For an idea of magnitude, this means 100 individuals end up on the order (remember this is Big O) of 10,000 communication channels. Think that’s unrealistic? Even if divided into teams of 5, we’re talking talking 4000 channels. Fancy halving the graph’s density? We’re still talking 2000 channels. The point is that it scales quadratically. In other words, it does not scale. If you’re a business, forget about competitors committing homicide. You’ve just committed suicide.
The good thing is alternative organisational designs are completely possible. Take the most common solution approach, for instance: hierarchy. Graphically speaking, this means organising nodes into a k-tree, where k is the number of splits at each level of the tree.

This could represent a CEO, to whom VPs report, to whom team leads report. The good news is that trees with n nodes have n-1, or O(n) edges. The problem in this case is that there are downsides to excessive hierarchy, including team isolation, employee dissatisfaction, and communication breakdown itself. The height of a tree with k splits is the number of times you need to multiply k to get number of leaf nodes (hence the logarithm). For example, if we had 156 individuals (for simplicity), we would have 125 leaves, and a communication depth of at least 3. This is reasonable for smaller organisations, but doesn’t scale much further. In fact, I would go so far as to say that any indirect communication across nodes (Chinese Whispers) leads to issues.
Another alternative is to divide people into extremely tightly woven, multi-skilled SWAT teams. The multidisciplinary nature of such teams, and their small size (e.g. ~5 people) is precisely why we can think of them as independent nodes in the organisation, able to take reasonably sized projects end-to-end. Communication can still build up across teams, so one might choose to limit the degree of any node to, say, 2.
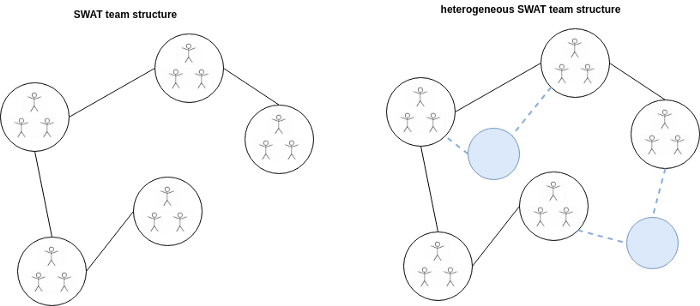
The SWAT team structure is in fact a special case of a very common structure: large functional teams like “product”, “data science” and “business intelligence”. I think the problem with those are threefold:
1. Such teams often get too big, meaning the node abstraction doesn’t really apply.
2. Node degree (number of connections to other teams) usually explodes
3. Skillsets tend to be relatively homogeneous. This again fails the node abstraction (1) if one believes such teams work less as a unit, and contributes to (2) as constant cross-team, cross-skill interaction is required
That said, there are benefits to having specialised functional teams. This leads to what I call a heterogeneous SWAT team structure. You have your usual SWAT teams, but certain functional teams or individuals float around as required. These are kept small, but perhaps don’t figure into SWAT teams’ degree restriction.
The kind of nerd analogy I have in my mind is SWAT-like teams of superheroes/differently skilled characters in a game/military tactical units (pick your favourite or make up a new one) going on quests end-to-end. As multi-skilled as these teams are, they sometimes encounter an obstacle that requires a drill team/some artillery. So they call the functional support team in to do some temporary heavy lifting, and then carry on.
There is a separate advantage to this approach: individuals’ motivation levels. Think about how you would feel going to work with your band of brothers and sisters, versus a large homogeneous amorphous group. It also doesn’t have to be a permanent situation; there is plenty of scope for occasional rotation of individuals across nodes.
The heterogeneous SWAT team structure is currently the best I can come up with for any organisation of more than 10 people. And I think it scales well. That said, I can imagine all sorts of alterations that might work best in any given environment, albeit with the same underlying principles from this model.
A Note on Concurrency
Organisations are in many ways distributed systems of human beings, and I would be remiss not to highlight the absolutely crucial point of concurrency, as well as point out a common misconception about parallelism.
The usual analogy is that of digging a hole. To dig it faster, you could get a bigger spade. This corresponds to making nodes better at what they do, for example with skills mentorship. An alternative would be to get your friends to help you out. At some point you’d probably get in each other’s way, so it might make sense to increase your output by each digging an identical hole at the same time. This is the basis of parallelism: doing many similar tasks independently at the same time.
Concurrency, sometimes confused with parallelism, is a much broader idea. Now you and your friends are doing different tasks: some of you digging, some of you sharpening spades, some of you carrying dirt out of the way. Importantly, different parties will have to interact at certain points, and this can lead to bottlenecks. If you can’t shovel anymore because you’re waiting for someone to clear the dirt around you, you’re stuck idle and unproductive. In fact, we can visualise what happens when an interdependent group has to wait for its slowest member. The tasks can be different (i.e. this is not just parallelism, hence the different colours), and we simplify by illustrating members syncing at the least common denominator (rather than drawing out the full concurrency graph):
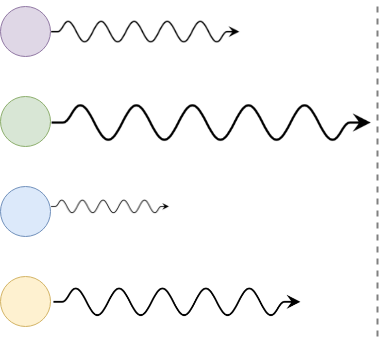
There are two mains things we can do to avoid painful idle time. Firstly, we can try and make interactions asynchronous (non-blocking e.g. a text message) instead of synchronous (e.g. a big meeting). We’ll describe this more in the section on edge (communication) quality. Secondly, we can limit cross-team dependencies, which is exactly where the SWAT team model comes in. It’s worth noting that beyond simply wasting productivity, idleness due to excessive dependencies can be a leading cause of demotivation.
Edge Quality
Now that we’ve spoken about scaling communication, let’s look at how to maintain high standards of communication quality. This could be translated into our model as edge weights/thickness, denoting the quality or alternatively the cost of a given interaction link. (though cost makes more sense in that we could look at metrics — like the weighted average number of edges in the graph, as something to minimise subject to constraints).
I have a couple of strong views on this topic, so I’ll convey them one by one. First of all, a knee-jerk solution to communication breakdown I’ve seen at multiple organisations as they scale is to “overcommunicate”. On one hand, good communication is indispensable. On the other hand, as we’ve seen, quantity of communication simply does not scale. It’s like staying at the office an hour later, or two hours later…you’ll get more done, but not by a factor of 10 or 100. For that you need leverage.
In the context of communication, leverage can often be seen as bandwidth: in this case, how much information can be exchanged per unit time. I just mentioned “information”, and indeed the lens of information theory proves useful in analysing communication (of course!). If you think about it, an open-ended conversation with a person allows for the most flexibility in what is discussed. The tradeoff is that it takes more time, as you never quite know what the other person will say next. Ironically, despite amazing flexibility, one would characterise the bandwidth as very low.
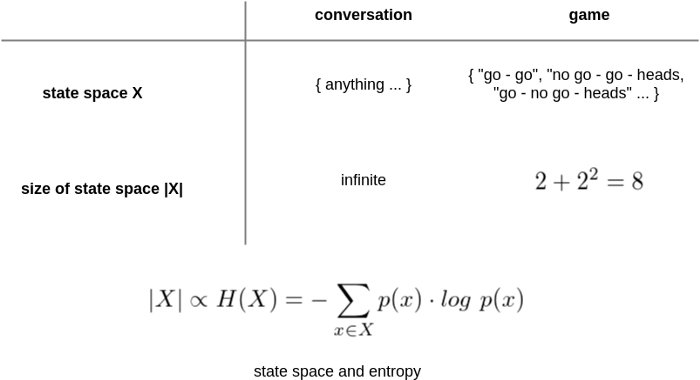
Now consider the other extreme. Let’s say two people, Alice and Bob, are playing a game, deciding whether to launch a new product feature. The game is as follows: Alice says “go” or “no go”. Bob then does the same. If they coincide, the decision is made and they simply execute. If they disagree, they toss a coin, heads Alice wins, tails Bob wins. Flexibility is reduced; they would certainly have a hard time talking about the colour of the sky in this game. But bandwidth is extremely high; the interaction could take seconds.
Formally, we’d say each example has a state space X, the set of possibilities. Assuming a uniform distribution over possibilities, systems with bigger state space will have a higher entropy of communication. We want low entropy communication as much as possible. This model helps me reason about things, but feel free to use or discard it as you please.
As a rule, for maximum output and minimum burden, interactions should always use the lowest entropy medium possible. If it can be a web form, don’t make it a conversation. If it can be histogram, don’t make it a paragraph over email. Improving communication entropy may be one of the lowest hanging fruits in increasing organisations’ effectiveness. A bit of design thinking can go a very, very long way.
When in-person meetings are required, a couple rules can be useful. Example rules could be:
- Amaximum of 5 people in any meeting.
- 30-minute duration on a given topic on a given day, unless it’s a brainstorming/design session.
- Ruthless punctuality, otherwise things get sloppy and everyone’s time is wasted.
- A clear agenda, which when reached, ends the meeting regardless of time allotted. Extend with caution.
One outlandish idea I’ve had is to enforce scarcity on meetings by fixing the maximum number of meetings any given individual can have per day. Other parties need to bid on those slots if they’d like that individual to join them for a meeting, using some sort of currency. This currency could be anything from an internal organisation token to a portion of one’s bonus.
The game theoretic motivation would be that people are included in meetings where they’ll have the most impact on productivity, assuming bonuses are sufficiently tightly coupled to objectives.
I wouldn’t invite someone for a meeting unless I thought they would add more value than the amount it’s costing me. In fact, a rigorous game theoretic analysis of company processes can also go a long way, but that’s perhaps a topic for another post.
Information Dissemination
If an organisation is an information processing system, with nodes communicating periodically, it makes sense to not only consider bi-directional channels, but one-way information dissemination as well. There are a couple of typical channels through which information is usually spread:
- email
- social text messengers e.g. Whatsapp, Telegram
- work messaging e.g. Slack
- publish-subscribe systems e.g. Twitter, Yammer
- kanban e.g. Trello
- integrated systems e.g. Jira, notion.so
- many others
Now that we have a few powerful concepts and some terminology under our belts, it’s pretty straightforward to articulate principles that might be useful for information dissemination. In particular, some considerations are:
- Whether ad-hoc requests are required, or self-service is possible
- Synchronous vs asynchronous
- Structured vs unstructured (entropy)
- Minimum duplication: complexity overhead of many specialised dashboards vs all in one place.
Massive amounts of information need to traverse companies on a daily basis, and digestible summaries in one place can trump a constant email barrage.
Meta-Organisation
It’s always seemed striking to me organisations devote so much effort to building a product, and yet building the organisation itself is an afterthought. It is so common to have data structures representing the product itself, but how often do we thoroughly model the members who build the product, and their interactions. Take the following relational database view of an actual product (say a delivery application) versus its counterpart for the organisation itself:
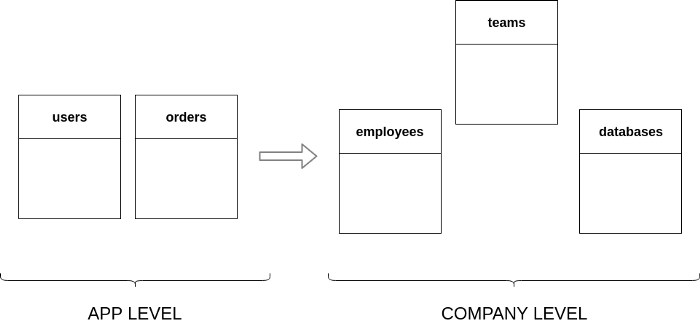
Imagine the possibilities if a small meta-team within the organisation focused exclusively on optimising the company itself, as opposed to the product directly.
Conclusion: The Human Touch
This post is getting long, so I’ll wrap up with one final note. The engineering principles I’ve applied to organisations are extremely useful. But at the end of the day, we must of course remember: people are people. A couple miscellaneous things I’ve learnt are:
- Diversity (cultural, gender, etc…) makes the product better, and people happier.
- Balance diversity with shared qualities. The lists are endless and ubiquitous (teamwork, excellence etc…), so I’ll focus exclusively on one: humility. Make sure every single member has low or no ego, because life is too short.
- Strictly cultivate a zero BS environment. This goes hand in hand with humility, but also involves a commitment to the Truth. It means always focusing on the reality of the problem. Teams that focus on this will always win in the long run.
Finally, enable humans to maximally fulfil their humanity. We all need inspiration. Inspire by practicing qualities you aspire to yourself.
Take an organic approach to things. Create an atmosphere where people can simply be themselves as much as possible. Everybody secretly just wants to be more like themselves, but we’re often too afraid, or restricted, or indoctrinated to do so.
And most of all remember, we’re all in this together. Would appreciate any thoughts around how you guys have been able to crack this.
Acknowledgements
Thanks to all the inspiring people I’ve known and/or worked with over the years, and the experiences that have helped me formulate these views on organisational theory.
[1]: http://www.businessinsider.com/elon-musk-says-theres-no-such-thing-as-a-business-2015-9
[2]: http://www.dtic.mil/get-tr-doc/pdf?AD=ADA128980
[3]: For example [OKR](https://en.wikipedia.org/wiki/OKR)s/[KPI](https://en.wikipedia.org/wiki/KPI)s at the team level. N.B. I find these terms extremely corporate. Aesthetics do matter!
We’re hiring. We have 200 engineers serving 261 million people. We practice the philosophy of “lean engineering” and have 18+ products with quick decision-making because of our culture and people. Be part of this amazing team. Check out gojek.jobs for more.