The Data Dilemma
How GOJEK’s booking data management went from being unorganised and chaotic to relying on a single source of truth.
By Deepshi Garg
As GOJEK has scaled over the past few years, our booking management system has seen a few revisions. There used to be a time when we stored multiple copies of the same data to serve different features. It was a confusingly scattered implementation.
But, don’t take my word for it. See for yourself:
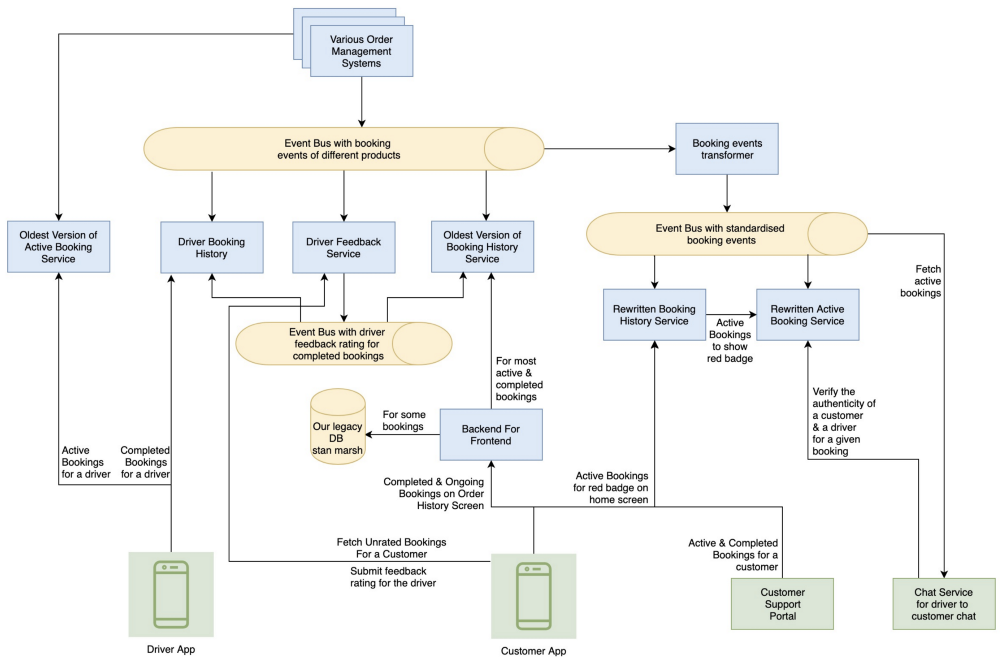
All these services maintained their own copy of booking data, and used it to serve their respective features. Any failure or delay in consumption of a booking event by a consumer would lead to inconsistency of data across systems.
This post will explain how we moved from multiple, scattered data stores to a single source of truth.
Early days, problems galore
- Data inconsistency : Let’s assume a booking is created, and is available with the
Older Active Bookingservice, but a delay occurs in theOld Booking History Serviceconsumer. This would mean that the driver would see the booking, but the customer will get only a red badge indicator on the home screen without any specifications of the ongoing order. Or, if there is a delay inStandardised Bookings Eventsbus, the customer will see the booking, but won’t be able to make a complaint about it, because the customer support portal will not get this booking. - We faced issues with scalability as well. Scaling multiple databases with the same data came to be seen as a pointless. For example, if we wanted to serve booking history of a longer duration, we would have to scale
Driver Booking History,Older Booking History Service, andRewritten Booking History Service. - Adding a new feature to this system became a pain. We had many long and eventually futile discussions about which service should serve the feature. For instance, fetching and validating orders for driver to customer chat was a confusing decision in itself. Adding the feature for the customer to be able to get unrated bookings and then submit driver ratings for them led to the creation of whole new service
We realised it was time for a refactor towards a Single Source of Truth for bookings data.
Thus, we came up with a clear categorised plan. All the data should be divided into two major categories : Active Bookings and Completed Bookings, and should essentially be stored in only two databases.
We could have created a truly singular source and stored both active and completed bookings in a single database, and served them both from a single service. However, that would create a single point of failure for the bookings management system across both driver and customer applications. Active bookings are more critical than completed bookings, and thus needed to be made more available and reliable. Also, again, scaling might be an issue.
Finding answers
We spent some time working this out, and tackled the problems individually:
- The problem of Data inconsistency was handled by having only one service each to manage for active bookings and completed bookings. We eliminated an extra layer of potential delay by including the logic for standardisation of various booking events of multiple products in these services themselves. This logic now resides as an internal library available for use, rather than a new series of events entirely.
- Scalability was ensured differently for active and completed bookings. Active bookings are a crucial requirement for customer, and the number of queries for these is very high (around 100k rpm in peak hours). Also, we don’t need to store data beyond a week or two for this. Thus, it was scaled for high throughput but comparatively less data (response time ~ 3ms). However, completed bookings are not as critical (i.e., can afford a slower response) with lesser throughput (around 50k rpm in peak hours), but it needs to store data for upto 4 months of user bookings. Thus, it was scaled for high amounts of data but comparatively fewer queries (response time ~15 ms). How exactly are these two systems scaled, is a story for another time 😛
- For all the upcoming features, we now clearly segregate whether they need active bookings or completed bookings, and thus use the appropriate service to handle them. For example, now all the unrated bookings for a customer (which are essentially completed bookings) are getting served by the Booking History Service. Driver Feedback Service now only receives the driver ratings, calculates the average rating for a driver and serves it to the driver app.
Finally the following architecture was arrived at:
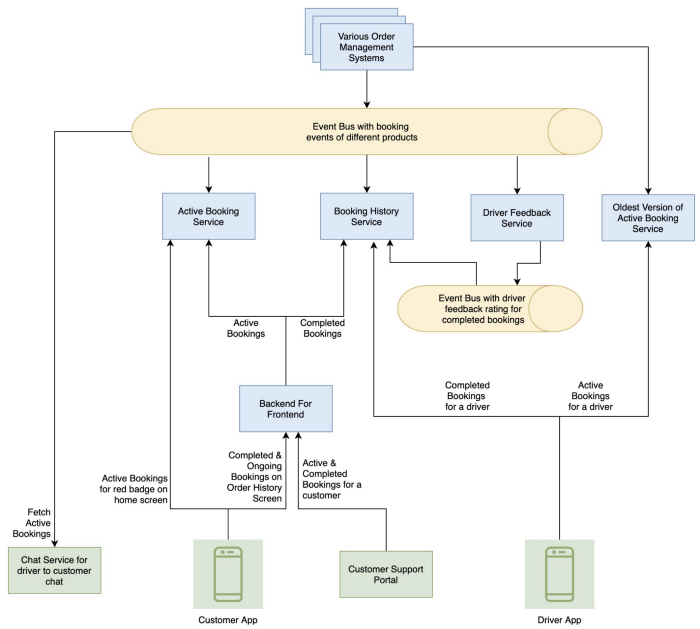
Ha!! This looks better. 😅
We tried to bring down the number of services as much as possible, by clubbing together the essence of features they served.
The Backend For Frontend is up for elimination too. Our older apps made a single backend call on order history screen to fetch both active and completed bookings for a customer. Once the app moves to different API calls, we can get rid of this proxy as well.
For the chat service, we allowed it to consume the booking events directly. We decided to skip the authentication of a driver or a customer for a given order, and rely on this event bus for this purpose.
Examining this ecosystem thoroughly also helped us to perform certain side tasks as a part of this migration. Firstly, we also moved all the products out of stan-marsh. This means we now have a log of all the bookings across multiple order management systems in the same event bus. Secondly, we managed to reduce the payload on the order history screen as well.
Earlier, the API on the order history screen returned about 120 keys for every order. We brought it down to about 40 keys per order.
Results
Our new system ensures consistency of data across the both the driver and customer applications. It is much more scalable, and for now, we have only two databases to manage. If we are to add a new feature, we have clear visibility as to which service should take it up.
As an added benefit, all our products now push events to the same event bus, thus creating uniformity across the GOJEK ecosystem. Also, reduced payload for the order history screen led to reduced complexity of logic on both backend and frontend.
So that’s the story of how we went from a messy system with multiple copies of data to a more streamlined one. Thanks for reading! ✌️

Scaling a Super App, that’s no easy task. Thankfully we have a lot of great teams that make it look easier than it actually is. We’re also looking to expand these teams. So if you’ve got the skills, we’ve got the challenges. Head over to gojek.jobs to see our open positions. Let’s make things official. 👍
