The Curious Case of Phantom Watches
The story of our investigation into unprompted Consul ‘watch’ triggers, and what we learned in the process.

By Dhanesh Arole
In a previous post, we tackled the concept of ‘watches’ in Consul, and dug deeper into how they are implemented.
Previous article: Understanding Consul Watches
As I explained in the post above (which I highly recommend you read to gain some context) GO-PAY uses Consul for service discovery and Consul ‘watches’ help us keep track of the status of a service.
This approach worked pretty well for us over the last two years, but we faced some interesting problems in our adoption of Consul at scale.
In this post, we will explain how we identified the problems, investigated them, and learned more about Consul (and its history of fixes) in the process. Also look out for some tips on operating Consul in production with the larger hive mind.
But I’m getting ahead of myself. Let’s start at the beginning:
The inciting incident
In an ideal world, a watch for a service should only get triggered by these three situations:
1. Whenever a new instance of the service being watched registers itself with Consul.
2. An existing instance deregisters itself when it gracefully shuts down.
3. The health check of that service starts failing.
At least, that was our assumption. But in the Production environment, we observed that the watch for each of our services was getting triggered periodically, without any change in its state (See Figure 1).
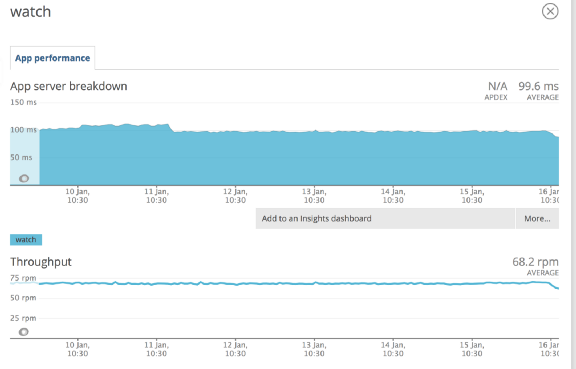
Figure 1 shows our APM dashboard showing a high throughput of Watch retriggers. This is despite the watched service being healthy while running on Consul v0.7.0
Then came the consequences
Our RPC framework is designed to evenly route and distribute traffic to the healthy instances of a destination service. This is done using a Client Side Load Balancing Algorithm (which will be expanded upon in a future post). This mechanism of dynamically switching traffic from unhealthy instances to healthy instances is built using Consul Watch Handlers.
We do this by attaching a Watch Handler function with the corresponding service’s watch. On every watch trigger, this function queries Consul catalog to find current healthy instances of the service being watched and calls a hook to refresh/create connections to them. But as you can see from Figure 1, due to the high frequency of watch triggers, every service was trying to refresh its connection to the destination service too often.
This was a major problem.

{kind=link}
When we observed this issue, we were running Consul Server v0.7.0 and a few agents at higher versions like v0.9.3, v1.0.5, and v1.4.0. After digging through the Consul source code, past issues, and public mailing lists, we realised that the only solution was to upgrade our Consul version from v0.7.0 to at least v1.0.7.
This fixed the problem. (See Figure 2)
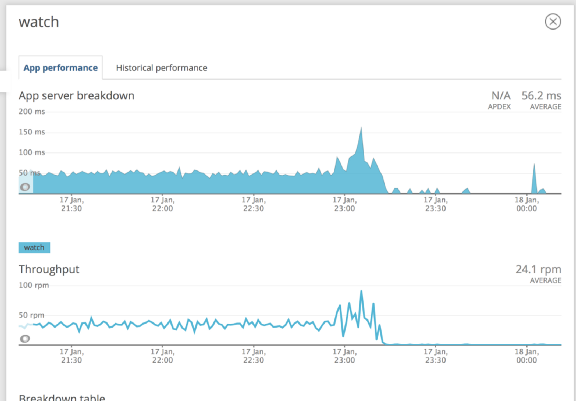
Figure 2 shows the same APM dashboard after a Consul upgrade, reflecting a drop in watch throughput to almost zero when the service is fully healthy. This is expected behaviour.
What was the fix though? 🤔
To understand what exactly has been fixed in recent versions of Consul, let’s start with fundamentals first.
If you’ve read the previous post on Consul Watches, you should be familiar with the concept of the X-consul-index header value. We observed that in our Consul cluster, the value of this X-consul-index header was increasing continuously without any state change in any of the downstream services. This ever-increasing value of X-Consul-Index in each blocking query during the health check was causing watches to get triggered periodically (without any change in the health of service). That led us to the following question:
What can cause ‘X-Consul-Index’ or ‘modifyIndex’ to change frequently in Consul cluster?
Ideally, modifyIndex should only change when a service registers or deregisters itself, or health check performed by a local agent sees a change in its status. Then the agent conveys that new status to Consul server via RPC. (See Consul architecture for more details). But apart from these core operations, Consul also periodically performs anti-entropy.
To explain in brief, anti-entropy is the process of periodically agent syncing its local state with the server’s catalog state, so that the catalog remains in sync.
During this local state sync, the Consul agent running on a given node will fetch all the services and checks registered on that node from the server catalog (uses /v1/catalog/node/<node-id> and /v1/health/node/<node-id> respectively). Then, it fetches all the services and checks from local agents (uses /v1/agent/services and /v1/agent/checks respectively). Once it has both, it compares them by their respective outputs.
In this comparison, it checks for equality of following fields ServiceID, ServiceName, CheckName, CheckStatus, CheckOutput, and ServiceTags. An important thing to note here is it doesn’t look at the output of CheckStatus field alone, it looks at all of these fields to compare for equality. If all of them happen to match, then it doesn’t call the server to sync its local state. Else it will call Consul server to sync check by making an API call to /catalog/register with the request body as the local agent’s check fields.
Now, if this equality comparison fails during every anti-entropy run, then the Consul server will receive a write for that particular service every time, and apply it to raft log. This increases the value of the modifyIndex field in the API response when someone subsequently calls /v1/catalog/service.
These writes that do not have any difference in their state changes are called ‘Idempotent Writes’ in Consul cluster. That’s why all these blocking queries APIs don’t claim that every time you call an API you are guaranteed to get a different output. It might even be the same output but with different X-Consul-Index header value.
see reference[1], [2], [3] for more info about this.
Digging deeper
So the next step in debugging was to find out why the equality check was failing during every anti-entropy cycle. After going through Consul source code and past issue logs on Github, we deduced that there was a bug because of which Consul didn’t support storing ServiceTags on agent health checks. Because of this, during every anti-entropy cycle, catalog check output and agent check output did not match. This was because health checks in catalog would have all the ServiceTags added during service registration, but local agent’s checks on that node won’t have them. This resulted in Consul agent syncing its local state during every entropy cycle, causing lots of Idempotent Writes for that service. This issue was fixed in v1.0.5 as part of this PR for the bug fix.
If v1.0.5 fixed the problem, why switch to v1.0.7? 🤷♀
In Consul’s older implementations, raft indexing had a specific design. I’ll explain by taking an example of a Consul cluster having two services named service-A and service-B. Let’s assume service-A’s state/checks are changed/synced and service-B’s state/checks are not. Even then, the API response of /v1/catalog/service/service-B would have X-Consul-Index header value equal to modifyIndex of service-A.
Simply put, X-Consul-Index header was not service specific. It was the index at which any service in the cluster was last modified in raft log. So a single flappy or wrongly-configured service check in a cluster would cause all watches to wake up, as a write in one flappy service’s modifyIndex would increase the value of X-Consul-Index header on any other catalog service endpoint in the watch loop.
This was fixed in v1.0.7 as a part of this bug fix. So it was necessary for us to upgrade to v1.0.7 on both agent and server, as this logic of populating X-Consul-Index in the response headers is done by the server.
Case diary
Based on our experience using Consul, we realised that Consul changes pretty fast and things often break during version upgrades. Having said that, the community is proactive with necessary fixes, and mentions breaking changes in upgrade notes.
Here are a few things to keep in mind while using Consul:
1. Make sure to have proper automation in place to upgrade Consul clusters in production, as you will need to do it more often than you think.
2. Always read the release changelog before upgrading and make sure you are aware of what’s new and what’s being deprecated or removed.
Find detailed instructions for upgrading Consul here.
References:
- What’s an idempotent write and when does it happen?
- Side effects of idempotent write
- Consul source code function updateSyncState used during anti-entropy
- Consul blocking queries
- Consul upgrade notes
- Instructions for upgrading Consul
- What is service mesh and why you need one?
GOJEK runs one of the largest JRuby, Java and Go clusters in Southeast Asia, processes over 100 million transactions a month, and partners with 2 million driver partners. We’re changing the dynamics of on-demand platforms, improving quality of life and creating social impact along the way. We also happen to be looking for more talent to help us solve hard technical problems. Want to try your hand at tackling scale in the company of the best in the business? Your journey starts at gojek.jobs. Let’s get cracking ✌️