So you think you can index?
Tips and tricks to keep in mind while creating indexes.

By Akshit Jain
Database Tuning is one of the most discussed topic in any high scale organisation. Index tuning is a part of database tuning for selecting and creating indexes. For indexes, you can check this. As part of adding one feature in GO-PAY few days back, we had one such discussion around adding Index to achieve better performance results. I will be sharing some key observations and learnings out of that discussion. This will include the following metrics:
- Percentage of time the index is being used while querying a table.
- Cache Hit Ratio -> Defines the percentage of time indexes that are accessed from cache, rather than disk.
I will be referencing a table which GO-PAY uses for payment requestsstorage. For clarity, I will use the name “dummy_table” . We’re using Postgres 11 (Updated recently from Postgres 9.5). It currently has 11 GB of data (growing at a stupendous rate now) and 5 indexes spanning 12 GB of disk space. The machine used is c4.xlarge (4 cores, 7.5 GB RAM).
Below is the index usage of the table. Postgres creates a table pg_stat_all_indexes internally to store the index usages. The query used:
select * from pg_stat_all_indexes where relname = ‘dummy_table’;

Here is the complete list of indexes for this table:
id_index -> btree(id)
idempotency_index -> btree(request_id, payment_id, wallet_id, transaction_amount)
idx_prevent_duplicates -> (payment_id, wallet_id, desc)
order_id_index -> btree(payment_id)
reference_id_index -> btree(request_id)
Issues:
I will start with idempotency_index . This index’s usage is 0 😞 as seen in Fig A and this data is from the time this index was created. In a table of 10 GB and increasing data, this index was never used. Let’s see the space taken by this index.
select pg_size_pretty(pg_table_size(‘idempotency_index’));

What that means: an index which is not being used is taking almost 5 GB out of 12 GB total space in disk. What a waste 😞.
The other issue that came out during discussion is related to creation of this index.
The index was created for the below query:
SELECT id, request_id, wallet_id, transaction_amount, desc, payment_id, comments, created_at, updated_at, receiver_handle from dummy_table where payment_id = $1 and wallet_id = $2 and desc= $3 and transaction_amount= $5Now, the question is, “Do we need to have a composite index” after knowing that one separate index is already there for payment_id as can be seen from Fig A.
Running this explain query gave me results shown in Fig. C
explain ANALYZE SELECT id, request_id, wallet_id, transaction_amount, desc, payment_id, comments, created_at, updated_at, receiver_handle from dummy_table where payment_id = $1 and wallet_id = $2 and desc= $3 and transaction_amount= $5
Focus on index usage and the execution time of the query.
Now, I removed this idx_prevent_duplicates index and reran the query. I got this result:

NOTE: None of the above are actual field names and are just used to explain the issue.
Observations
Both queries gave similar results. Strange for us, not for Postgres. So here is the theory:
The theory says, as long as the leftmost column in the query already has a single index or that leftmost column is the leftmost column on some other composite index, then there is no need to have another composite index . The crux: other columns should not be having a lot of data corresponding to that left most column.
Let’s say A,B,C,D are columns of a table and we have single indexes on A and B.
Case 1:
You write a query that involves A and C. If we are sure enough that for a single A, there would not be a lot of C data, then we can safely ignore, creating a composite index on A and C and can reuse the already existing index on A.
Case 2:
You have a composite index on A and B. Now you write a query that involves A and C. As A is the left most common column between the query and the current composite index, there is no need to have a different composite index.
In both the cases index creation will not lead to a significant improvement in the execution time, but memory will surely be used.
Other questionable thing was: why was that idempotency_index never being used. It’s because the ordering of query and index doesn’t match with each other, rather it matches with some other index.
Learnings
- Percentage Of Index Used:
SELECT
relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM
pg_stat_user_tables
WHERE
seq_scan + idx_scan > 0
ORDER BY
n_live_tup DESC;
Learning 1 -> While there is no perfect answer, if you’re not somewhere around 99% on any table over 10,000 rows, you might want to consider adding an index.
2. Cache Hit Ratio
SELECT
sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
(sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio
FROM
pg_statio_user_indexes;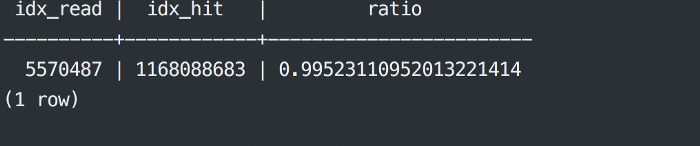
Learning 2 -> Generally, you should also expect this to be in the 99%
Impact Caused By Unused Indexes:
- It reduces the cache hit ratio since it will occupy some space in cache in the beginning. It’s highly probable that part of some other useful index lies in the disk rather than cache. So when a query comes, it goes and checks in disk, thereby reducing the cache hit ratio.
- Percentage of indexes used will decrease.
Conclusion:
- When any index is created, we should look thoroughly on what kind of query we are running. Does it require more indexes or not?
- If an index is created, what will be the most optimised way so the same index can be used later for other queries.
- Recheck whatever index has been created and if it is being used or not.
- After Index creation and collection of fairly handsome amount of data, check out the impact on the above two metrics of Cache Hit Ratio and Percentage Indexes Used.
And… That’s a wrap from me. What do you think? Any tips, suggestions? Please leave a comment below. And if you’re looking for jobs in team GO-PAY, check out gojek.jobs. Fun Fact: We handle more than 30% of overall e-transactions in Indonesia. And our digital wallet is just about 18 months old. Sounds insane right? Come over and help us!
References:
- http://www.postgresqltutorial.com/postgresql-database-indexes-table-size/
- http://www.craigkerstiens.com/2012/10/01/understanding-postgres-performance/
