Scaling Our Geo-Search Service For 10x Load
This is the story of how we scaled Available Driver Service (ADS), to meet Gojek's ever-increasing demand.

By Prathik Rajendran M
Background
Available Driver Service (ADS) is Gojek’s geo-search system that answers the following query: “Given a location and constraints, who are all the drivers near the location that satisfy the constraints?”
The constraint could be something like “a car that has a sanitizer”. This is extremely crucial, because if the system goes down, we cannot allocate a driver to an order as we don’t have a candidate set of drivers to allocate.
Problem statement
ADS was originally built on top of Postgres and it was not scaling due to the high write load from driver location pings coming very frequently. This led to re-indexing on every update of the location. To overcome this, we moved to Redis but even there we saw that the highest throughput the system could handle was around ten thousand requests per minute. We had an alternative solution that we relied for GoRide (our ride hailing business) that used to get the most traffic. But as GoFood and Logistics businesses grew, the load on our in-house system became much greater to a point where we started getting daily alerts on SLA breach. Along with that we also faced a thundering herd issue during peak load because the system dependent on ADS does a retry every 15 seconds which took the entire system down for approximately an hour. Thus to enable the growth of our Food and Logistics businesses it was imperative that we can scale ADS horizontally to meet the ever increasing demand.
Trade-off
There are two things to be considered before we dive deeper into the specific trade offs made in order to scale up:
- We get location information of the driver very frequently (in the gaps of a couple of seconds).
- Customers want their orders fulfilled as soon as possible (irrespective of whether it is ride hailing, food delivery or logistics, this invariant holds true) — everything else equal customers will always select the option that delivers the fastest to them.
What this means is that if we serve a driver with a slightly older ping it’s not a concern because location doesn’t drastically change and it’s always better if we serve some drivers in a given area even if we are not able to fetch all the drivers in that area.
In a distributed system there is always a tradeoff which is well captured in the PACELC theorem. The Geo-Search system in our case needs to be a PA/EL system which means that during a network partition it favours availability and in normal situations it will favour latency over consistency. Thus we tradeoff completeness and exact accuracy of the location for availability and low latency.
Principles for scaling
Read-write splitting
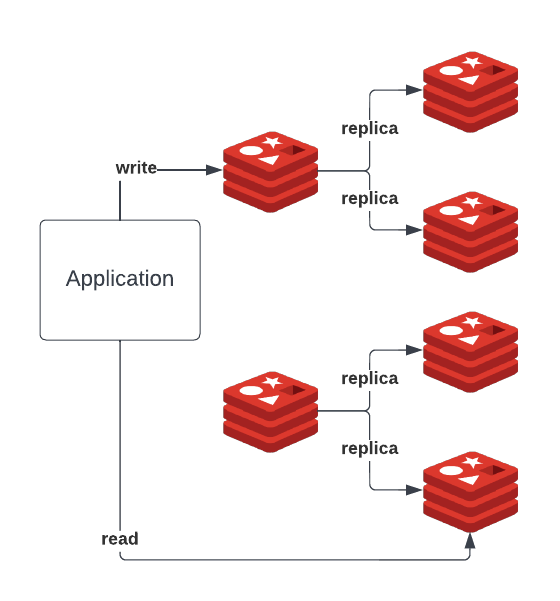
For our Geo-Search service we use Redis as the primary persistence layer as durability of the data isn’t a concern and we want low latency, specifically we use Redis cluster. A Redis cluster is a multi-master multi-replica setup where each master handles a particular shard and each master has multiple read replicas.
For our search use case we also leverage EVAL functionality of Redis where a lot of our filtering for Geo-Spatial search operations happen via Lua scripts. One of the issues that we saw happen due to this was the EVAL commands were being sent to Redis master since EVAL command is not a read only command and Redis replicas can handle only read-only commands.
On top of this the Redis client that we used, go-redis, by default routes all the EVAL commands to Redis master nodes.
To overcome these problems we did two things:
- We proposed a read only variant of the EVAL command called EVAL_RO and EVALSHA_RO to Redis and it got accepted. With this any Redis lua script that has read only commands can safely run on the Redis read-replicas and if there are any write commands in the Lua script it will fail safely. This also overcomes the problem of Redis clients sending non-readonly commands to master.
- We made a contribution to go-redis to enable us to call Redis replicas directly using EVAL commands as a short term strategy.
Each query addressed by multiple nodes
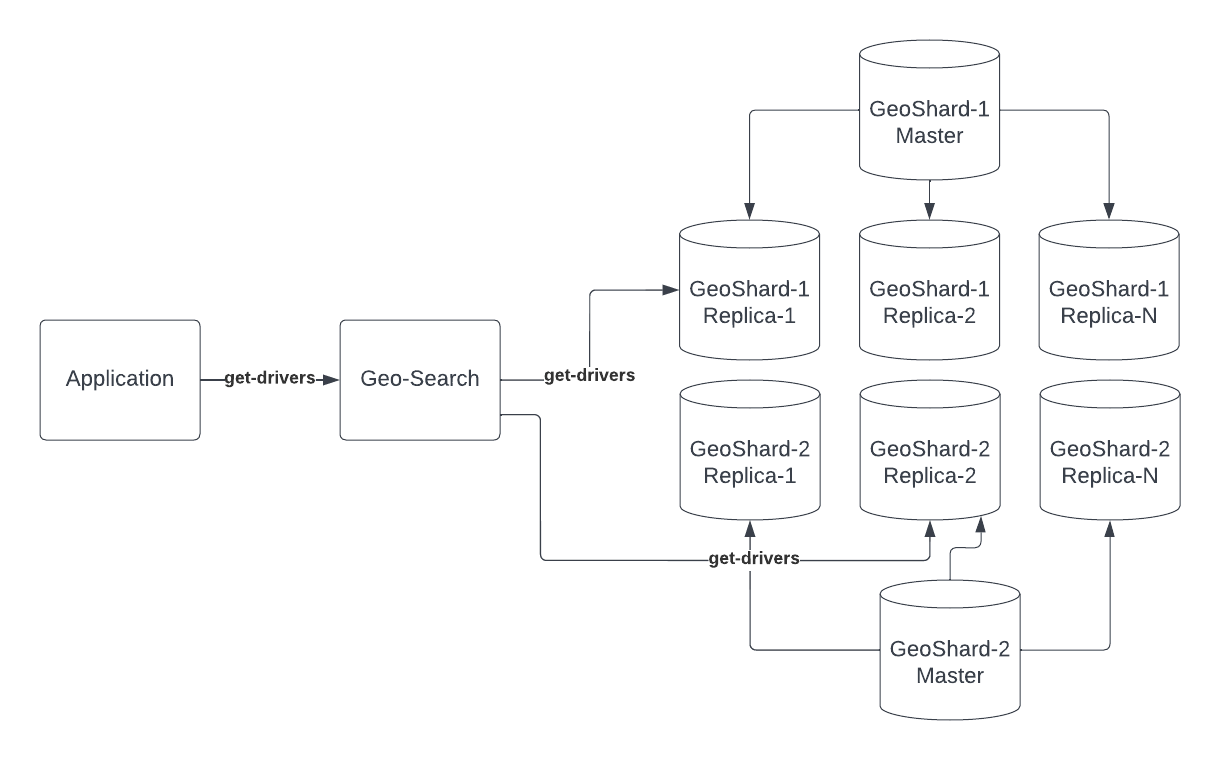
Availability along with low latency is extremely important for the Geo-Search service thus in order to ensure that every search request gets a set of requested drivers what we do is ensure that each search request just doesn’t go to one node, but is fired in parallel to multiple nodes, this ensures that even if one node is down or slow we are not going to face an issue because the other node will respond with drivers.
Our search queries are nearest neighbour queries, that is given a particular point we need to find the points closest to it. When a query comes we split it into multiple smaller geo queries and each one of them are served by different replicas.
Dividing and conquering the query into smaller geo queries enables us to have low latency as it is split across multiple nodes that operate on these in parallel.
Splitting a geo query into smaller regions and executing on different nodes also prevents the occurrence of hot-shards; we ensure that shards are done in such a way that the peak load regions and low traffic regions are mixed together. Being able to divide peak load regions into smaller regions allows us to do this.
Best effort search
As mentioned above the Geo-Search service needs to be a PA/EL system, what this means is that we favour availability and low latency. What we mean by best effort search in this context is that a search query can go to multiple nodes and each node responds back with a set of drivers, however we don’t wait for all the nodes to respond back all the time, we have a set timeout for the query to execute and when that time limit is reached we respond back with all the drivers that have been fetched so far and don’t wait on any slow nodes.
Most of the nodes have a p99.99 SLA to respond with the drivers in the given time limit but there is a small chance that the nodes don’t meet the SLA and in that case we only respond back with the drivers fetched from the other nodes. It’s a small tradeoff we take to ensure that customers get their drivers as soon as possible.
Each query addressed by multiple nodes and having a cap on the response time of each of the nodes ensures that the system is both highly available and at the same time has a low latency, which is the goal of this system.
Impact
Our Geo-Search service, Available Driver Service, has moved to a point where people just assume it works and there is no need to discuss much about it. Simple is not easy, the abstraction simply works and people don’t need to dive deep into the internals and worry about it. But to get to this point was not easy. Prior to scaling up this service it was always on top of everyone’s mind, including business teams, wondering whether it will be able to scale up to meet the growing demands. Today the only discussion is a heads up if the scale would drastically change and everyone just assumes it will work. At peak this service has seen traffic reach up to 600,000 writes per minute and 200,000 search per minute and has been able to handle it effortlessly. Increasing to higher capacity is all about provisioning more nodes which was not possible in the previous design that only allowed vertical scaling.
Applying these principles
You saw above the three principles we applied to scaling our Geo-Search service but these principles are applicable to any system that is eventually consistent, needs high availability and low latency. The implementation details can vary, we use Redis but you could be using some other datastore, perhaps an in memory solution. The principles are especially important if your service needs to respond with some data always but not necessarily all the data. The pattern above favours responsiveness during time of fault, that is the service tries as much as possible to not timeout the request when there are slow nodes.
Future Goals
These principles have led to our service becoming horizontally scalable and operating at really low latency, our systems can scale as much as we want it to, at peak it has seen 200,000 requests per minute of computationally intensive Geo-Search queries and can easily scale much higher based on business needs.
The future goal for us with this is to enable auto-scaling of our Redis replicas which is right now managed manually, this will enable us to lower infrastructure cost to a very low level as we see peak traffic only for some parts of the day and there is much lower traffic during the others.

Check out more blogs from our vault here.
Oh, if you’d like to join us, check out open job positions:
