Sakaar: Taking Kafka data to cloud storage at GO-JEK
How we created a zero data loss cold storage data lake out of streaming Kafka data.
By Sumanth Nakshatrithaya
The Data Engineering team is responsible for building solutions that help orchestrate data across GO-JEK. We rely on Kafka to distribute events across various services.
New topics get added almost every day across different Kafka clusters which serve enormous throughputs. One of the perks we give users of our platform is that any data put into Kafka will be available for analysis (powered by Spark) with infinite retention in cloud storage with atleast once guarantee.
Why build a new solution?
With existing open source applications, we found occasional data losses due to app crashes. Also, they couldn’t scale well when throughput increased. Due to the data losses, we had to put an audit system in place which called out the data loss so we could replay the data archival using Kafka’s retention. With ever increasing scale of data it led to frequent maintenance work and need for high retention in Kafka.
Another reason for building Sakaar was that we didn’t want to restart/re-deploy the application every time a protobuf message schema was updated. We wanted a push mechanism where apps get the updated schema at runtime.
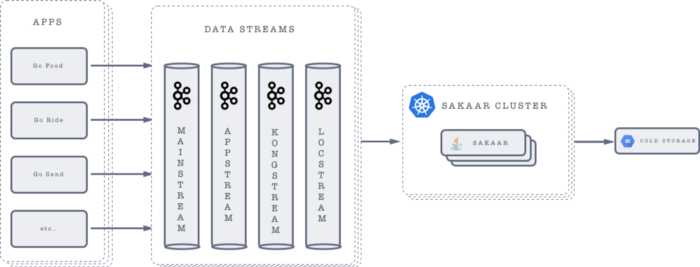
How it works?
We took an Occam’s razor approach to building this app and kept the logic as simple as it could be for the requirement in hand. As at the time of writing of this blog, it only supports protobuf de-serialization and google cloud storage for upload, but it can be easily be extended to support more.
Key features of Sakaar
- Atleast once guarantee
- High performance
- Resilience
- Easy configuration
- Ease of scaling
Atleast once guarantee
Pursuing an exact once guarantee in a system that spans across technologies is a hard problem to solve and tightly couples each link in the chain. Eventual consistency is what we generally aim for. Even Kafka’s exact once processing is limited to transactions with in the same cluster.
The guarantee that we give our users is that their data in Kafka will always be recorded. But, there could be duplicates when there is a bad runtime condition. We recommended that messages contain fields which help uniquely identify a message in case of duplicates. If the messages are transactional in nature its highly recommended to have a dedicated idempotency key in the message.
The idea behind the guarantee is simple: commit back to Kafka only after messages have been uploaded to storage.
The app is stateless and always starts with a clean slate by purging any files left by the previous run and starting from previously committed offsets. Kill the application, scale it up/down, it never drops a message.
High performance:
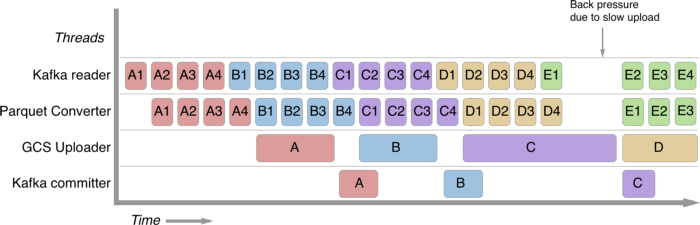
Data is stored in Parquet fomat. Files are finalized at the end of the time window (default being 1 hour) or after hitting a file size limit. The application functioning can be roughly split into 4 stages:
read messages -> accumulate to file -> upload -> commit offsets
We use blocking queues to run these four stages as a parallel executing pipeline. (i.e.) when a uploader is uploading, the converter is parsing and writing the next batch of messages. While the convertor is writing parquet files, the reader is reading the next batch of messages, etc.
This 4-stage pipeline enables us to ingest data fast while limiting the worker thread count to just 4.
Blocking queues enforce that stages work in lock step, and back pressure due to a slow stage communicated to all workers throttling the speed of the app. The size of blocking queues helps dial a balance between back pressure reaction vs smoothing of performance jitter in the workers.
Resilience:
When we were gathering the requirements for the app, we put down graceful shutdown almost instinctively. On a second look, we asked ourselves: can we achieve at least once guarantee without having to engineer a graceful shutdown? This meant you could interrupt or kill the application at will and still get the guarantee.
If instead, we relied on a graceful shutdown, a sig-kill would kill our guarantee. So we went ahead and didn’t add a shutdown hook or a bunch of error handling with thread co-ordination. Instead, we relied on Kafka commits to see us through with our guarantee. Any error at runtime just bubbles out taking out the app (after configured retries). We made sure all the stages of the pipeline run as daemon threads monitored by the main thread and nothing can leave the application in a hung unresponsive state.
Easy configuration:
We have a minimum number of explicit configurations required to get the app up an running by providing good defaults and concise configs.
Example for configuring hourly partitioning:
#before
partitioner.granularity.hour=true
partitioner.granularity.minute=false
partitioner.granularity.date.prefix=dt=
partitioner.granularity.hour.prefix=hr=
partitioner.granularity.date.format=yyyy-MM-dd
partitioner.granularity.hour.format=HHVS
#now
PARTITION_FORMAT='dt='YYYY-MM-dd'/hr='HHIn-fact, partitioning takes a string literal as per java simple date format. So you can have a second wise or even millisecond wise partitioning set up with just this one config.
It also supports topics with different schemas and different timestamp fields.
TOPIC_SCHEMA_MAPPING=audit-log:com.gojek.AuditLog:edit_time|booking-log:com.gojek.BookingLog:event_timestampEase of scaling
Sakaar apps are regular Kafka consumers and rely on Kakfa’s consumer balancing to distribute data to different pods. There is no other form of co-ordination between the pods. Being stateless allows to spin up/down containers without the need for any volume mounts.
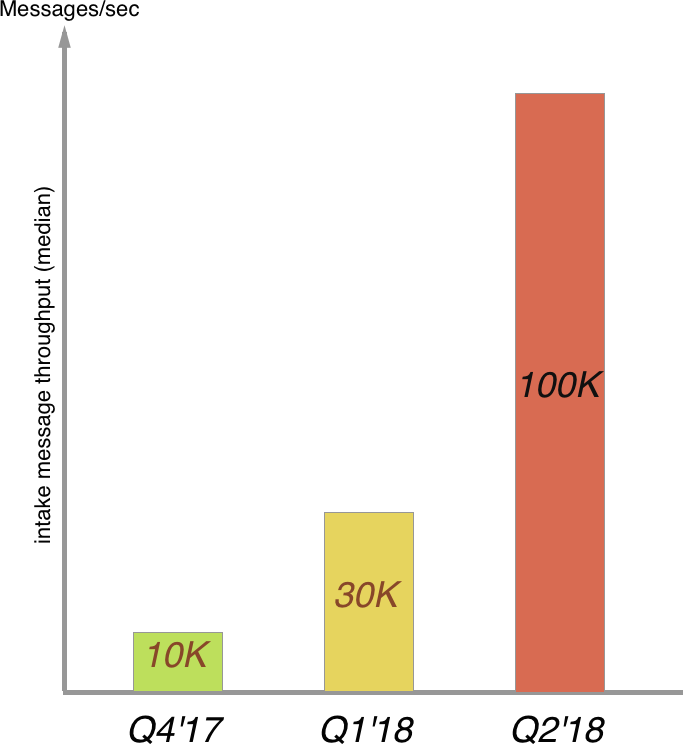
Impact
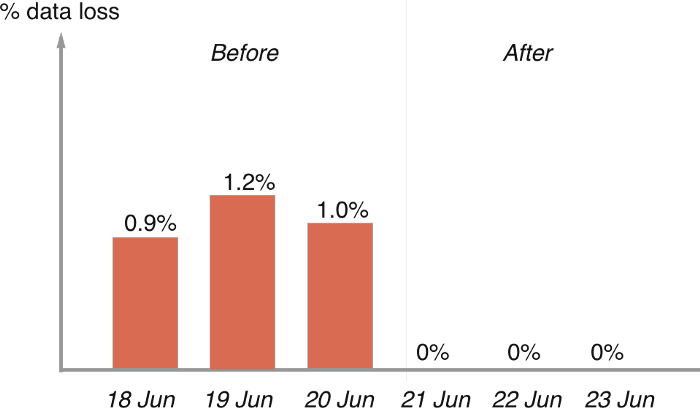
The results were evident in our audits. There has been no drop of messages since. We now offer cloud storage retention by default for all topics on Kafka with zero message drop guarantee and take no operational effort for providing the same.
We have no shortage of complex, interesting problems that require the best talent. Join us, we’re hiring. Enough problems to solve! Check out gojek.jobs for more.
