Resiliency in Distributed Systems
.

By Rajeev Bharshetty
Before jumping into discussing resiliency in distributed systems, let’s
quickly refresh some basic terminology:
Basic Terminology
Resiliency
The capacity of any system to recover from difficulties.
Distributed Systems
These are networked components which communicate with each other by
passing messages most often to achieve a common goal.
Availability
Probability that any system is operating at time `t`.
Faults vs Failures
Fault is an incorrect internal state in your system.
Some common examples of fault in systems include:
1. Slowing down of storage layer
2. Memory leaks in application
3. Blocked threads
4. Dependency failures
5. Bad data propagating in the system (Most often because there’s not enough
validations on input data)
Healthy systems in the absence of faults:
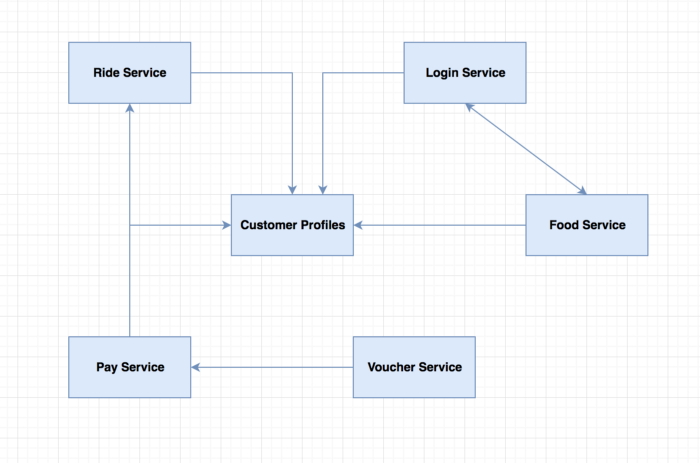
Systems affected in the presence of faults:
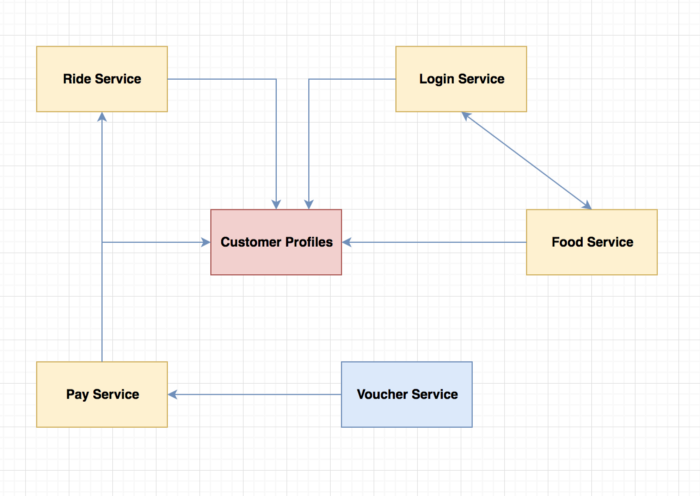
Whereas, Failure is an inability of the system to perform its intended job.
Failure means loss of up-time and availability on systems. Faults if not contained from propagating, can lead to failures.
Systems failing when fault turned to failures:
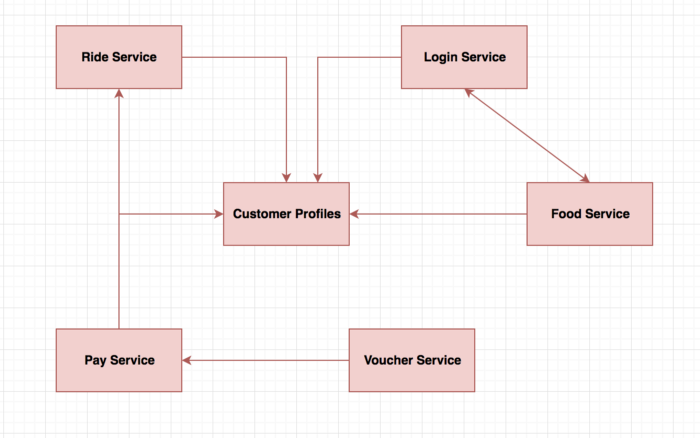
Resiliency is all about preventing faults turning into failures
Why do we care about resiliency in our systems ?
Resiliency of a system is directly proportional to its up-time and availability. The more resilient the systems, the more available it is to serve users.
Failing to be resilient can affect companies in many ways.
For GO-JEK, not being resilient means:
1. It can lead to financial losses for the company
2. Losing customers to competitors
3. Affecting livelihood of drivers
4. Affecting services for customers
Resiliency in distributed systems is hard
We all understand that ‘being available’ is critical. And to be available, we need to build in resiliency from ground up so that faults in our systems auto-heal.
But building resiliency in a complex micro-services architecture with multiple distributed systems communicating with each other is difficult.
Some of the things which make this hard are:
1. The network is unreliable
2. Dependencies can always fail
3. User behavior is unpredictable
Though building resiliency is hard, it’s not impossible. Following some
of the patterns while building distributed systems can help us achieve
high up-time across our services. We will discuss some of these patterns
going forward:
Pattern[0] = nocode
The best way to write reliable and secure applications is write no code
at all — Write Nothing and Deploy nowhere — Kelsey Hightower
The most resilient piece of code you ever write will be the code you
never wrote.
The lesser the code you write, lower are the reasons for it to break.
Pattern[1] = Timeouts
Stop waiting for an answer.
Let’s consider this scenario:
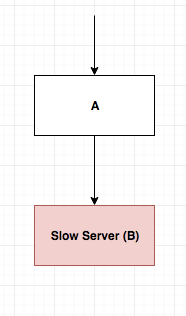
You have a healthy service ‘A’ dependent on service ‘B’ for serving its requests. Service ‘B’ is affected and is slow.
The default Go HTTP client has no HTTP timeout. This causes application to leak go-routines (to handle every request Go spawns a go-routine). When you have a slow/failed downstream service, the go-routine waits forever for the reply from downstream service. To avoid this problem, it’s important to add timeouts for every integration point in our application.
Note: Heimdall is a GO-JEK OSS which implements some of the following resilient patterns.
For example: One can set a timeout using Heimdall:
This will help you fail fast if any of your downstream services does not reply back within, say 1ms.
Timeouts in application can help in following ways:
Preventing cascading failures
Cascading failures are failures which propagate very quickly to other
parts of the system.
Timeouts help us prevent these failures by failing fast. When downstream
services fail or are slower (violating their SLA), instead of waiting for the answer forever, you fail early to save your system as well as the systems which are dependent on yours.
Providing failure isolation
Failure isolation is the concept of isolating failures to only some part
of a system or a sub system.
Timeouts allow you to have failure isolation by not making some other
systems problem your problem.
How should timeouts be set ?
Timeouts must be based on the SLA’s provided by your dependencies. For
example, this could be around the dependency’s 99.9th percentile.
Pattern[2] = Retries
If you fail once, try again
Retries can help reduce recovery time. They are very effective when
dealing with intermittent failures.
For ex: You can do retries with constant backoff using Heimdall like:
Retries works well in conjunction with timeouts, when you timeout you
retry the request.
Retrying immediately might not always be useful
Dependency failures take time to recover in which case retrying could lead
to longer wait times for your users. To avoid these long wait times, we could potentially queue and retry these requests wherever possible. For example, GO-JEK sends out an OTP sms message when you try to login. Instead of trying to send SMS’s synchronously with our telecom providers, we queue these requests and retry them. This helps us decouple our systems from failures of our telecom providers.
Idempotency is important
Wikipedia says:
Idempotence is the property of certain operations that they can be
applied multiple times without changing the result beyond the initial
application.
Consider a scenario in which the request to some server was processed but failed to reply back with a result. In this case, the client tries to retry the same operation. If the operation is not idempotent, it will lead to inconsistent states across your systems.
For example: At GO-JEK, non-idempotent operations in the booking creation
flow can lead to multiple bookings being created for the same user as well
as the same driver being allocated to multiple bookings.
Pattern[3] = Fallbacks
Degrade gracefully
When there are faults in your systems, they can choose to use alternative
mechanisms to respond with a degraded response instead of failing
completely.
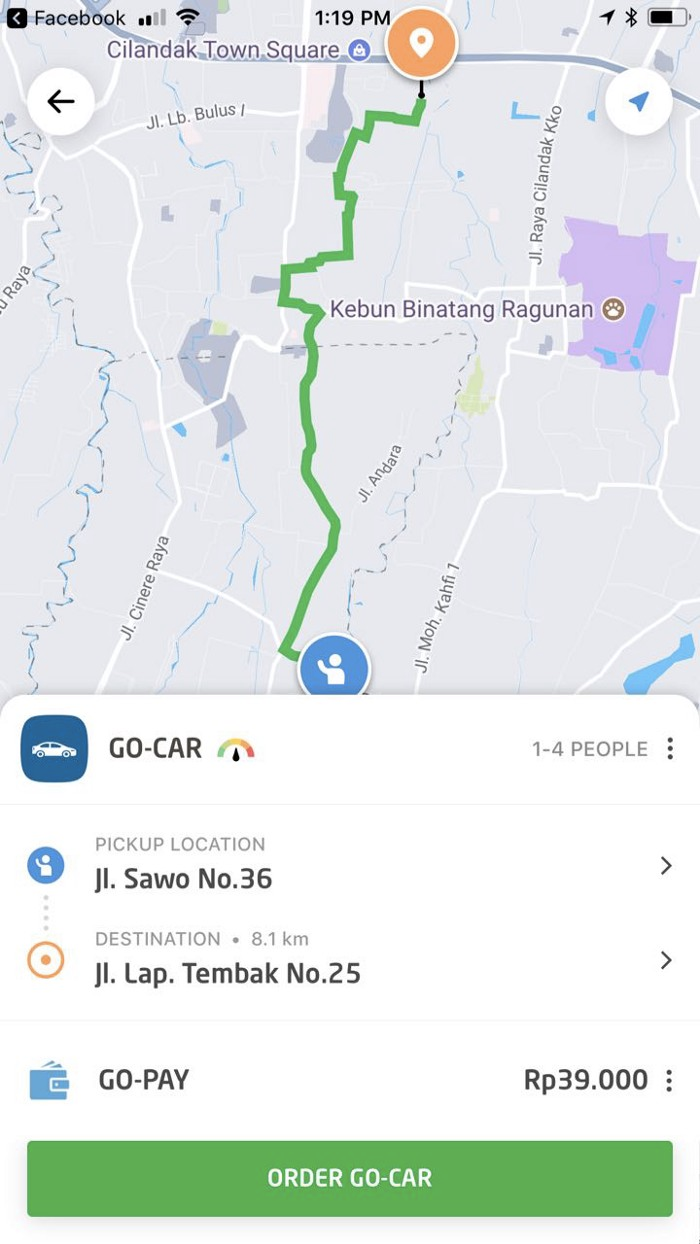
The Curious case of Maps Service
At GO-JEK, we use Google Maps service for variety of reasons. We use it to
calculate the route path of our customers from their pickup location to destination, estimating fares etc. We have a Maps service which is an interface for all of our calls to Google. Initially, we used to have booking creation failures because of slowdown on Google maps api service. Our systems were not fault tolerant against these increases in latencies. This is how the route path looks like when systems are operating as expected.
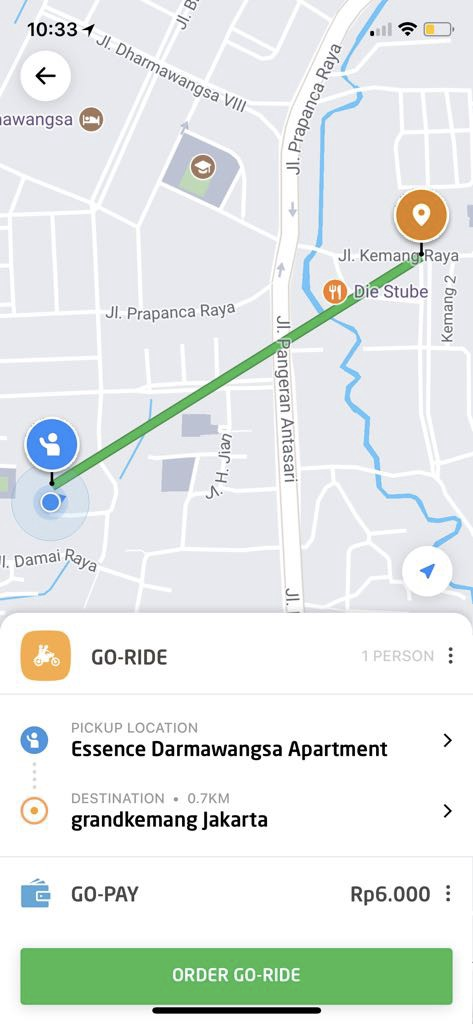
The solution we went with was to fallback to a route approximation for
routing. When this fallback kicks in, systems depending on maps services work in a degraded mode and the route on the map looks something like this:
Fallback in the above scenario helped us prevent catastrophic failures across our systems which were potentially affecting our critical booking flows.
It is important to think of fallback at all the integration points.
Pattern [4] = Circuit Breakers
Trip the circuit to protect your dependencies
Circuit breakers are used in households to prevent sudden surge in current
preventing house from burning down. These trip the circuit and stop flow of current.
This same concept could be applied to our distributed systems wherein you stop making calls to downstream services when you know that the system is unhealthy and failing and allow it to recover.
The state transitions on a typical circuit breaker(CB) looks like this:
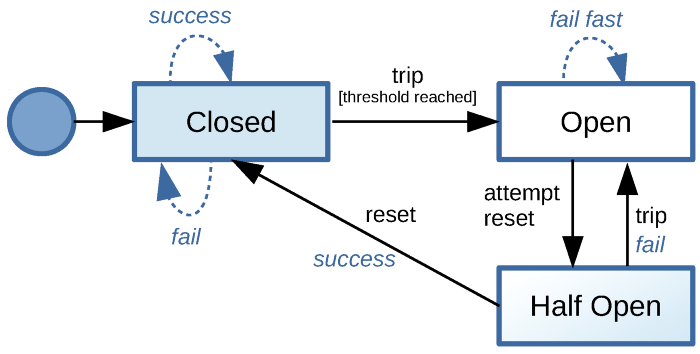
Initially when systems are healthy, the CB is in closed state. In this state, it makes calls to downstream services. When certain number of requests fail, the CB trips the circuit and goes into open state. In this state, CB stops making requests to failing downstream service. After a certain sleep threshold, CB attempts reset by going into half open state. If the next request in this state is successful, it goes to closed state. If this call fails, it stays in open state.
Hystrix by Netflix is a popular implementation of this pattern.
You can setup a simple hystrix Circuit breaker at your integration point using
Heimdall:
The above code sets up a Hystrix circuit breaker with timeout of 10ms allowing 100 max concurrent requests, with an error percent of 25% and sleep window of 10ms.
Circuit breakers are required at integration points, help preventing cascading
failures allowing the failing service to recover. You can also add a fallback for the circuit breaker to use it when it goes in open state.
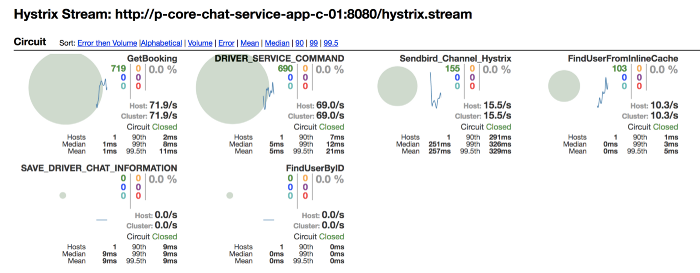
You also need good metrics/monitoring around this to detect various state
transitions across various integration points. Hystrix has dashboards
which helps you visualize state transitions.
Pattern[5] = Resiliency Testing
Test to Break
It is important to simulate various failure conditions within your system. For example: Simulating various kinds of network failures, latencies in network, dependencies being slow or dead etc. After determining various failure modes, you codify it by creating some kind of test harness around it. These tests help you exercise some failure modes on every change to
code.
Injecting failures
Injecting failures into your system is a technique to induce faults purposefully to test resiliency. These kind of failures help us exercise a lot of unknown unknowns in our architectures.
Netflix has championed this approach with tools like Chaos Monkey, Latency monkey etc which are part of the Simian Army suite of applications.
In Conclusion:
Though following some of these patterns will help us achieve resiliency,
these is no silver bullet. Systems do fail, and the sad truth is we have
to deal with these failures. These patterns if exercised can help us achieve significant up-time/availability on our services.
To be resilient, we have to:
Design our systems for failure
References:
- We have open sourced Heimdall — Enhanced HTTP client in
GO which helps us implement some of these patterns in a single place - Would recommend reading Release It by Michael Nygard
- This blog post is an extension from the talk I gave on the same topic at
Gophercon India 2018, the slides for which can be found here - Code companion for the examples in the blog post here
- I write more on these topics at my blog
Would love to hear more on how you build resiliency in your systems. And…we’re hiring. Check out gojek.jobs for more.