Reliable ML Pipelines with Clockwork
How we manage scheduling and automation of ML pipelines in Kubernetes.

By Yu-Xi Lim
Next in our series on Gojek’s Machine Learning Platform, we address the scheduling and automation of data pipelines and model training.
One “unsexy” side of data science is the amount of repetitive work. New data needs to be ingested and converted into useful features. Models need to be retrained. Metrics need to be computed and reported. This usually involves multiple dependent steps and a regular schedule. It is tedious and error-prone.
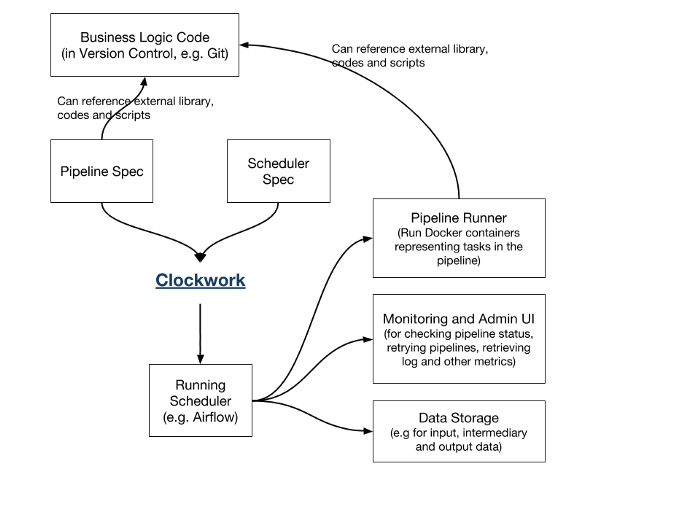
Clockwork is a part of our ML Platform that aims to alleviate this pain. At the heart of Clockwork is AirBnB’s Airflow, but we have layered several useful features on top of it.
Airflow is a popular solution for building and scheduling processing pipelines. It has a rich set of operators that support actions such as reading from a JDBC-compatible database, running Bash scripts or Python code. It has a detailed monitoring dashboard showing the job execution history and quick ways of re-triggering failed pipelines. Usefully, it can run jobs on remote workers, allowing us to run resource-intensive jobs.
Clockwork adds the following:
- Easy sharing of data between tasks: Airflow’s primary concept is around sequences of tasks, without much regard for how data is shared between each task. This means that each user reinvents their own data-sharing practices. We have standardised and simplified this.
- Simpler runtime environment configuration on Kubernetes: Airflow operators are powerful and have a great degree of control. However, this means a huge learning curve for data scientists as they will also have to learn the details of Kubernetes and Docker. We find there are many commonalities in the data science workloads and chose to simplify the runtime configuration, but allow users to Bring Your Own Runtime.
- Decoupling of business logic: It is not obvious how to easily test Airflow DAGs without submitting them to Airflow. Over-reliance on certain operators and Airflow variables can make it easier and faster to write complex flows but impossible to test locally. When local testing is hard, users end up testing in production.
- Pipeline definitions closer to code: Initially, our Airflow DAGs were in a single centralised repository. This meant that code changes will often need to be synchronised across multiple repositories: one for the actual code, and the common repository for the parameters or DAG. Merge conflicts were common. We’ve separated the schedule from the DAG/pipeline definition, allowing the pipeline definition to reside next to the code that it needs to run.
- YAML and Web UI for pipeline configuration: We provide a simple YAML configuration format that Clockwork converts to an Airflow DAG. To make things even easier, we have a Web UI to author the YAML files.
- Easy single-step pipelines: A common use case we see is to use Clockwork (or Airflow) purely for job scheduling (cron replacement) without complex multi-step pipelines. Clockwork gives users the benefits of Kubernetes/Docker, retries, and alerts over a regular cron job, but without the complexity of defining an Airflow DAG.
How it works
Clockwork comes in four parts:
- Clockwork UI: Web interface on top of Git to author Clockwork YAML
- Clockwork CLI: This converts the YAML definitions to Airflow DAGs.
- Clockwork scheduler: CI pipeline triggered on Git changes. It will call the CLI on the YAML files in Git.
- Clockwork Airflow operator and Docker images: Clockwork Airflow DAGs use a custom operator in conjunction with a few standard Docker images that can retrieve the relevant user code from Git.
To configure a Clockwork pipeline, one needs to create two YAML files. The scheduler spec goes into a central Clockwork repository and has a reference to the pipeline spec. The pipeline spec resides next to the business logic code.
A scheduler spec will look like this:
When the scheduler spec is pushed to the Clockwork repository, our CI system triggers Clockwork to process the scheduler spec and any referenced pipeline specs.
Other than pipeline specs, we also provide simple options for single-step pipelines. We allow data scientists to specify a reference to a Python file or Jupyter notebook in Git. More advanced users can also specify a custom Docker image they have built.
Pipeline specs look like:
Task dependencies allow Clockwork to construct the Airflow DAG. We make it simple to specify pre-defined or user-defined Docker images that will be executed on Kubernetes.
Because we have standardised on Docker instead of Airflow operators, it becomes easier to test the pipelines locally using the Clockwork CLI.
What’s next?
Clockwork has been one of our most successful ML Platform products. Many users that were previously using Airflow have migrated to Clockwork, and many users that were previously intimidated by Airflow have started using Clockwork for scheduling and automation.
Given our extensive usage of Kubernetes in Gojek, we are considering Kubeflow Pipelines as a replacement for Airflow. Kubeflow Pipelines will allow us to better isolate and scale resources in Kubernetes, making it safer and cheaper to run our pipelines. Thankfully, with the abstraction provided by Clockwork, our users will not have to change a thing even as we migrate the backend systems.
Stay tuned for more updates about Gojek’s ML Platform, or sign up for our newsletter to have updates delivered straight to your inbox.
If you are excited by the idea of developing such tools for data scientists, please consider joining Gojek’s Data Science Platform team.
Contributions from:
Budi Dharmawan, David Heryanto, Grace Christina, Julio Anthony Leonard
