Reducing Latency with Sidecar
How the sidecar pattern helped in our ongoing quest to reduce latency in our experimentation platform.


By Muhammad Abduh
You’ve probably heard about Litmus, Gojek’s in-house experimentation platform. Since we built it, the adoption of Litmus across Gojek teams has been steadily increasing. More experiments are executed and more clients (in this case, Gojek teams) are integrated.
Besides this, another requirement is to integrate Litmus with other backend services directly, instead of solely with the mobile app. However, various client backend services have their own SLA and most of them are linked to latency. So, in order to client requirements, we have to reduce Litmus latency as much as possible.
In this post, we talk about our thought process behind delivering an initial sidecar design to achieve this goal,
Know your enemies
First thing first, we needed to figure out where the bottleneck was. After digging through some data, it turned out 30% of total time in a Litmus API call was dominated by database call, and the number of database calls is ~2000 qps.
Based on this fact, we decided to use cache. Now, we obviously could not use an external cache like Redis or Memcached. If we used those, we would be adding an additional call. 😑
Instead, we decided to use in-memory cache. Since Litmus was written in Clojure, we went with caffeine cache, which is good enough to be used in JVM. We implemented the in-memory cache and the database calls dropped from ~2000 qps to ~10 qps. The API latency also dropped around 10%.
Good, but Not Good Enough. We Needed More.
The implementation of in-memory cache and further tinkering with Litmus processes would not be enough on their own. Our next approach was to reduce the hops between client and Litmus servers.
How? By moving Litmus server so it is geographically closer to the client?
Nah, we can do one better.
We pulled our Litmus server as close as possible to the backend service client. To achieve this, we used sidecar pattern. We created a Litmus sidecar that resides in the same box as the backend service client. A Litmus sidecar can be seen as a mini version of the Litmus server that specifically serves the dedicated backend service client in the same box (VM).
Tweaking the Nuts and Bolts
To know how effective the sidecar pattern is, we need to know the base latency of Litmus server. We created 10 new active experiments specifically to get the base latency number. With 20 concurrency and 10 request per second, the 99 percentile was 23.55 ms.
Need faster API calls? Use gRPC
We used gRPC over REST wherever we could in our Litmus sidecar. gRPC also has various features such as push/pull streaming and client-side load balancing that can be utilised for further enhancement. It’s fun stuff! 😁
How do we maintain our sidecar without permission to maintain the backend service client box?
In Gojek, each team can only have permission to access its own components/boxes. It is not possible (or scalable) to access all our backend service client boxes.
We could have considered this if we had only two or three clients. However, when you’re building for an organisation of Gojek’s scale with the hope of having all teams adopt Litmus in their services, we couldn’t go down this route.
On the other hand, we still needed the ability to check the health of Litmus sidecars in every backend service client and develop a sidecar app that complies with several 12 factor apps criteria (treat logs as event streams and store config in the environment).
{kind=link}
We decided to use Consul for service discovery and key-value config. In addition being easy to use and having a nice dashboard UI, Consul service discovery also supports health checks.
After we set up the infra (Consul server, agent, etc), we just needed to add our service definition config along with our litmus sidecar to the backend service client box. For the Consul KV itself, Consul supports hot reloading, which means we don’t need to restart clients’ litmus sidecar if there are config changes.
However, we needed to handle the logic of hot reloading in the litmus sidecar app by ourself. For the logging part, Gojek already has a logging tools called Barito that forwards the system logs so that we don’t have to access client boxes with ssh.
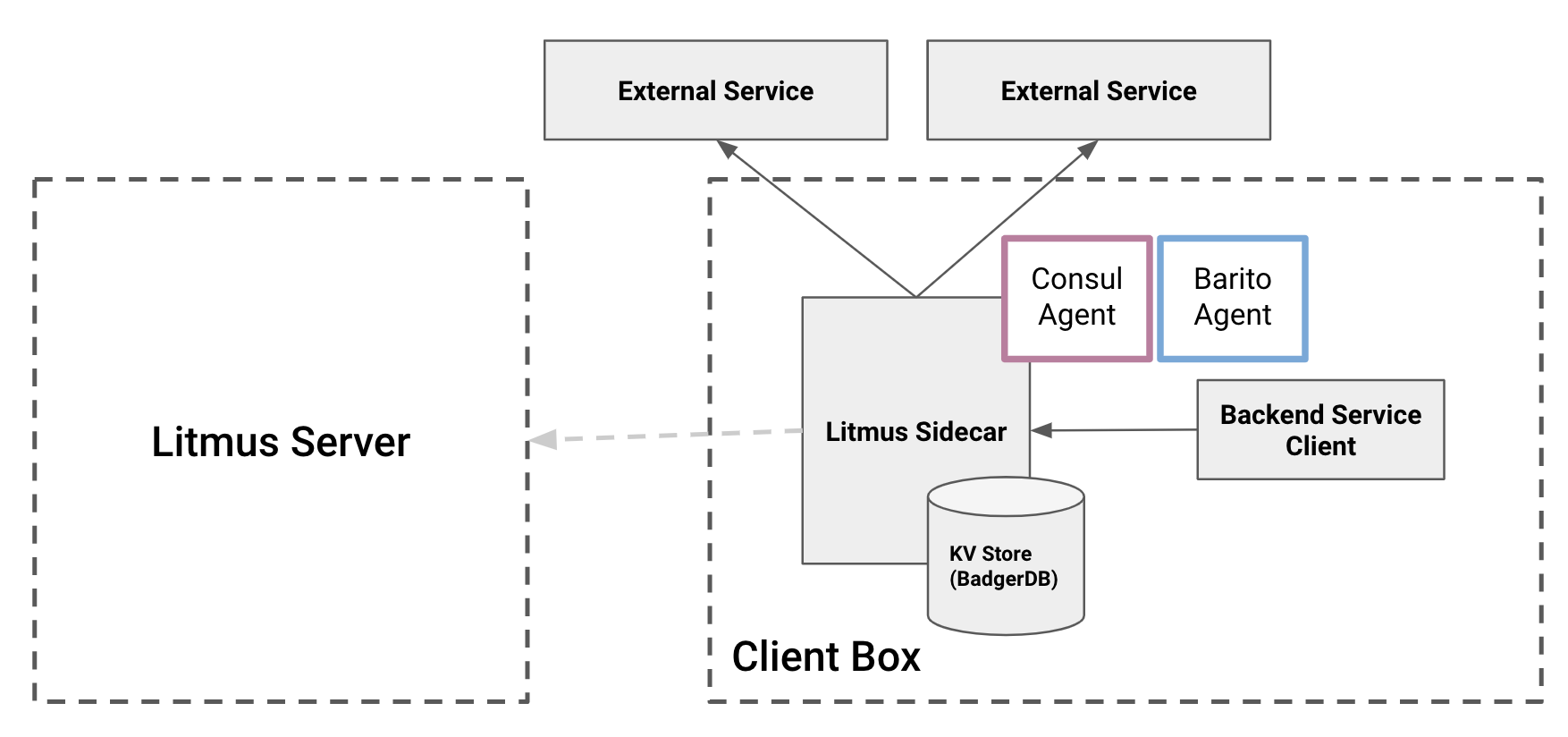
Here is the high-level architecture of how litmus sidecar integrates with client backend services. Instead of pointing to Litmus server address, now backend service clients only need to point to its localhost with Litmus sidecar port.
How is the data distributed?
As an agent of Litmus server that resides on the same box as the client, Litmus sidecar needs to have access to the same data as Litmus server.
This was something we discussed long and hard. The trade off between speed and data consistency, the trade off between consistency and availability, and so on.
As our purpose was to reduce latency, speed became our first class citizen. At least for now, it is okay for us to have eventually consistent data in our Litmus sidecar. We also decided to persist the data in the client box. We don’t store all Litmus server data, only what the client needs.
We wanted our Litmus sidecar as light as possible, so it does not disturb the main process in the box. Instead of using some SQL database, we decided to use KV store BadgerDB for persistence storage.
How to synchronise data between Litmus sidecar and server?
We came up with several ideas around this, but decided to use the simplest one for our initial design. Litmus sidecar pulls the data that it needs periodically and persists it with BadgerDB.
Alrighty then, let’s measure how good our sidecar is
Using the same setup as we did in measuring base latency, the 99 percentile latency dropped to 6.91 ms. ✌
New clients are now integrating with sidecar, but we didn’t stop there. We are continuously optimising our Litmus sidecar app, and you can read more about our efforts in this post.
So, that was the thought process behind building sidecar to reduce latency. We believe there is still room for improvement, and would love to hear your thoughts in the comments.

Want our stories sent straight to your inbox? Sign up for our newsletter!
