Our learnings from Istio’s networking APIs while running it in production
How we run Istio 1.4 in Gojek and everything that goes behind the scenes.
By Tasdik Rahman
We at Gojek have been running Istio 1.4 with a multi-cluster setup for some time now, on top of which, we have been piloting a few reasonably high throughput services in production, serving customer-facing traffic.
One of these services hits ~195k requests/minute.
In this blog, we’ll deep dive into what we have learnt and observed by using Istio’s networking APIs.
How we do what we do
To help visualise the process better, let’s consider a workload that can be thought of as a logical unit (VMs, k8s pods, etc.), which is the source of traffic. A workload comprises of a service and an envoy proxy sidecar. Simply put, 2 workloads would comprise of 2 sets of service + proxy.
A service inside this workload is something present in the service registry, which is addressable over the network. Services define a name, which is typically a valid DNS hostname, a set of labeled network endpoints, ports, and protocols. The service registry could be the k8s service registry/consul, etc.
A gateway would be a proxy that receives traffic on specific ports, which can be a logical or a physical proxy in the network that defines L3-L6 behaviours, the sidecar (in this case, the Istio proxy) is also a gateway in that sense. Similar to workloads, a gateway also represents a source of traffic.
If you’re on a cloud provider, like GCP, you can create a service object of type Loadbalancer for the ingress gateway, and it’s not a bad idea to have staticIP for this.
With the above in picture, the networking APIs of Istio which we have dabbled with are VirtualService, DestinationRule, and Gateway.
Making use of these networking APIs
Here are a few combinations which can be used to achieve respective results:
- Ingress (Gateway + VirtualService)
- Traffic splitting, TCP routing (VirtualService)
- Canarying, Blue-green (VirtualService + DestinationRule)
- Loadbalancing Config (DestinationRule)
- Egress to external Services (ServiceEntry)
One setup which we use is to create a default gateway for the cluster, which would handle all Ingress traffic for the services in the cluster. It’s also possible to have multiple gateways.
If one wants Ingress and nothing else, defining a VirtualService object for the service enables routing traffic to their service — Given the A record to point to the static IP of the gateway LB has been already created.
For capabilities like traffic shaping, an extra object of class DestinationRule has to be defined. This allows us to specify multiple subsets, which in turn need to be defined in the VirtualService spec to specify the weights for the different versions of the service. Based on the desired weights and rules defined in the VirtualService spec, the traffic needs to be routed.
How does traffic get shaped?
Traffic shaping happens in this form 👇
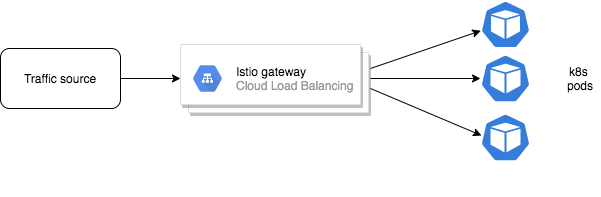
…although it may appear as below:
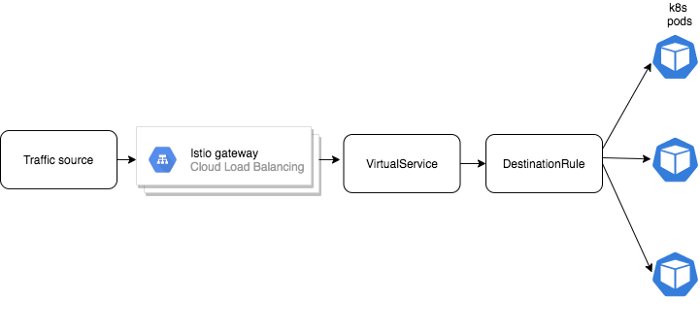
Here’s why:
When the traffic hits the gateway pods, the envoy proxy sidecar attached to the gateway would already know the pod IPs of the destination service. In simple words, the VirtualService and DestinationRules spec get translated to the envoy config.
But… What about the orchestration of CRUD operations of these resources?
Looking at this from an orchestration perspective, if one is to have 0 disruptions in the requests being serviced by the end service, the ordering of the creation of these resources also matter.
For starters, orchestrating the CRUD of these resources happens by putting them behind different CI pipelines and by using Helm would also work.
We use the istio/client-go to manage the lifecycle of the Istio resources, using our in-house deployment toolchain, powered by our service called Normandy (more on this in another blog post). This gets orchestrated by another service, which is our internal service registry, where we also store our service-related information and cluster mapping, along with other relevant information.
A big advantage of this approach of not letting a developer orchestrate the rules themselves is that we directly remove any room for errors that would occur because of the changes introduced manually. Leaving this to the tool in hand (Normandy and our service registry, in this case) allows us to put our logic inside a tool. This enables us to standardize the way we do the CRUD over the networking APIs of Istio, as well as the Kubernetes objects. Hence, any bugs we found would find their way back to the tool, standardizing, and enhancing the tool further.
If only VirtualService is being used to direct traffic to the service, the orchestration is pretty straight forward:
Create the k8s service object and deployment object for the service, after which the VirtualService object is created. No changes to the gateway.
The orchestration for deployment for a service would be:
Deployment object → VirtualService update/create
While using VirtualService + DestinationRule, the orchestration would be to:
Do the CRUD of DestinationRule first, and then the CRUD of VirtualService.
⚠️ The above ordering is important.
When there is already a VirtualService and DestinationRule existing for the service, and if the VirtualService is updated first, the subset being pointed to would not be present in the DestinationRule, causing 5xx errors till the DestinationRule is updated.
Everything seems in place now. There’s one subset in each VirtualService and DestinationRule for the service and things are working as usual without any 5xx errors while the orchestration is being done. But there are some unanswered questions. 🤔
How does the above handle the case when there are more than 1 subsets, while doing some sort of traffic shaping, for instance?
How is a zero-downtime deployment achieved?
We didn’t have a use case with more than two subsets, as at any given point, we would only need to shape traffic to 2 versions of the service, but having more than 2 subsets is definitely possible.
Simply generating a new set of DestinationRule and VirtualService, and updating the existing one, in that order, is an approach that would work. However, this would cause timeouts for the service for a very brief period, and depending on the load, one might not see anything or encounter a 5xx error.
In a high throughput service, this definitely is a problem. More than that, the very process of a deployment causing 5xx’s feels wrong and seems like the system is not behaving the way it should. In such cases, it is the orchestration layer causing the problem.
Here’s an approach that would work:
1️⃣ orchestrateDestinationRule ⇨ 2️⃣ orchestrateVirtualService ⇨
3️⃣ cleanupDestinationRule
Step 1: Append on the newer subsets to the DestinationRule without removing the older subset. In this case, one will be appending the labels which distinguish their newer deployment object for the newer version of the service.
Step2: Update the VirtualService with the newer subset.
Step3: Clean up the subsets in the DestinationRule which are not required anymore.
Remember there’s a good chance one might hit the case of 5xx again even if the above steps have been followed, which is explained here.
Why does the 5xx arise?
A small fraction of time is required by the Envoy Proxy sidecars to get the updated DestinationRule and VirtualService config (in the case above) from pilot and synced on each proxy. Chances are, the envoy sidecar of the service pod might not have been updated yet when the requests come in. This in turn makes some of the proxy sidecars to have the correct updated config, while some still possess the old config.
How to tackle this?
A small hack would be to add a small sleep for ‘x’ amount of time while orchestrating, which would look like:
orchestrateDestinationRule ⇨ sleep(x) ⇨ OrchestrateVirtualService ⇨ sleep(x) ⇨ cleanupDestinationRule
How do we arrive at the ‘x’ duration?
The metric pilot_proxy_convergence_time exposed can be tracked, to see how long it takes on an average, over a period of time, to infer the time it takes to sync the updated configs over each proxy sidecar. If the value appears to be on the higher side, try horizontally increasing the pilot replicas and check if that number comes down.
This is a hacky solution, but currently works on 1.4, as there is no other way to do this in the istio/client-go. We watch the status of the objects like DestinationRule and VirtualService, and check if they have been propagated everywhere in each proxy before moving on to orchestrating the next set of resources.
There is an option in the CLI to do a istioctl experimental wait, which blocks until the specified resource has been distributed.
For later versions of Istio, the Istio object status would have the information if the object has been reconciled with every proxy or not, which would help someone using the client-go to poll on this and proceed only if the resource has been propagated everywhere. This would be present in 1.6 directly, which also comes with a single binary for the control plane of Istio.
There is an issue tracking for this too. Find it here.
Keeping the above discussion around orchestration in mind, the following cases would arise (accompanying the pseudocode) if you are:
- Trying to do normal deployments.
- Doing Canary deployments with one version set as primary and the other version as candidate version. Note that in this case, as an identifier, we will use a deployment ID to distinguish between the two versions.
For this example, we would assume that the service is named foo and below are two versions of DestinationRule and VirtualService spec for 2 subsets:
 262588213843476
262588213843476 262588213843476
262588213843476Note: In the pseudocode ahead in the cases, the list object inside the DestinationRuleSpec and the VirtualService would represent the subset values, instead of having the whole spec presented, for the sake of simplicity of explanation.
Case 1
When it is a normal deployment, where the deployment, DestinationRule, and VirtualService for resource don’t exist.
Existing resources:
- Deployment Object: Not present
- DestinationRule: Not present
- VirtualService: Not present
Orchestration required (in this order):
- Create Deployment: foo-123
- Create DestinationRule: [deployment-id: 123]
- Create VirtualService: [subset: foo-123, weight: 100]
Case 2
When it is a normal deployment, where the deployment, DestinationRule, and VirtualService for resource already exist.
Existing resources:
- Deployment Object: foo-123
- DestinationRule: [deployment-id:123]
- VirtualService: [subset: foo-123, weight: 100]
Orchestration required (in this order):
- Create — Deployment — foo-456
- Update — DestinationRule — [deployment-id:123, deployment-id:456]
- Update — VirtualService — [subset: 456, weight: 100]
- Update — DestinationRule — [deployment-id: 456]
- Delete — Deployment — foo-123
Case 3
When it is a Canary deployment.
Existing resources:
- Deployment Object: foo-123
- DestinationRule: [deployment-id: 123]
- VirtualService: [subset: 123, weight: 100]
Orchestration required (in this order):
- Create — Deployment — foo-456
- Update — DestinationRule — [deployment-id: 123, deployment-id: 456]
- Update — VirtualService — [{subset: 123, weight: 90}, {subset: 456, weight: 10}]
Case 4
When we are promoting a Canary deployment, with 456 being promoted.
Existing resources:
- Deployment — foo-123, foo-456
- DestinationRule: [deployment-id:123, deployment-id:456]
- VirtualService: [{subset: 123, weight: 90, subset: 456, weight: 10}]
Orchestration required (in this order):
- Update — VirtualService — [subset: 456, weight: 100}]
- Update — DestinationRule — [deployment-id: 456]
- Delete — Deployment — [foo-123]
Case 5
When we are rolling back a Canary deployment, with 456 being rolled back.
Existing resources:
- Deployment — foo-123, foo-456
- DestinationRule: [deployment-id: 123, deployment-id: 456]
- VirtualService: [{subset: 123, weight: 90, subset: 456, weight: 10}]
Orchestration required (in this order):
- Update — VirtualService — [subset: 123, weight: 100]
- Update — DestinationRule — [deployment-id:123]
- Delete — Deployment — [foo-456]
Case 6
When we are increasing the weight of Canary deployment, with 456 being rolled to a higher percentage (Example: 20%).
Existing resources:
- Deployment — foo-123, foo-456
- DestinationRule: [deployment-id:123, deployment-id: 456]
- VirtualService: [{subset: 123, weight: 90},{subset: 456, weight: 10}]
Orchestration required (in this order):
- Update: VirtualService: [{subset: 123, weight: 80}, {subset: 456, weight: 20}]
One thing to point out above is that, after the CRUD operations of DestinationRule and VirtualService, one needs to add the wait time discussed above, in case v1.4 of Istio is being run. From v1.6, the status of the resource, whether it has reconciled on each and every proxy or not, can be polled directly on the resource object. More on this is described here.
This translates to do a poll on the status.conditions[0].status directly for the VirtualService and DestinationRule resource object, till we get the value True for the type Reconcile.
That’s all for now!
References
- The workload example is borrowed from the presentation given by Shriram Rajagopalan here
- https://istio.io/docs/ops/best-practices/traffic-management/#avoid-503-errors-while-reconfiguring-service-routes
- https://github.com/istio/istio/issues/23956
- https://twitter.com/tasdikrahman/status/1267357405181968384
