Our Experiments with Protobuf and PostgreSQL
How we implemented a PostgreSQL extension to help work with the Protobuf binary in the database context.

By Shan G
Recently, we were bouncing around the idea of coming up with a multidimensional driver property store, which could support slice & dice based on arbitrary driver properties in no particular order. The idea was to represent n attributes of an entity in binary format and be able to check for membership of arbitrary attributes and their values without unpacking them completely.
After exploring a couple of binary data representation formats like Protobuf, Flat-buffers, Message-pack, etc, we found the Protobuf binary format. This was easy to work with and suitable for arbitrary field membership and value check for filtering by properties and use cases that we had in mind. This also made sense as Protobuf & PostgreSQL are at the core of most of our projects at Gojek.
Proposal & Outcome
Implement a PostgreSQL extension, that would help work with Protobuf binary in the Database context.
Some context and assumptions as follows
- bytea is a generic type supported by Postgres to represent variable length binary data, and we use the same type to store Protobuf binary data. So, anywhere in this post, when we refer to bytea, it is synonymous to Protobuf binary data.
- We are only interested in the field boundaries and their wire-type, so we don’t need the Protobuf schema to really work with the data and the following functions do not make any assumptions about the Proto message type.
Implemented the following C extension functions in PostgreSQL.
 262588213843476
262588213843476
A few notes on the above functions:
pbcontains
- Checks if the second argument is a subset of the first, with the assumption that both of them are Protobuf encoded binary data
SELECT * FROM bench_data_person WHERE pbcontains(d, ‘\x0a045368616e1801’ );
pbmerge
Merge two binaries and return a new binary, with the following assumptions
- Argument
proto binariespreserves the field order - If the same field is available in both the arguments, the field value in second would have overwritten the field value in first in the returned value
pbiscanonical
- Checks if the field order is preserved in the give proto binary
pbcanonicalize
- Re-orders the proto binary in such a way it preserves the field and returns a new binary
pbunpack_int
- If the user knew a field type to be numerical ahead of time, they could unpack only that value by passing the proto binary and the field id.
Pros
- Flexible, backward compatible schema maintained in code as a Protobuf schema.
- Database just treats it as a blob
- You don’t pay space penalty for attributes that you are not using, since Protobuf strips unused or fields with default values when it encodes to binary. So, easy to add or remove attributes without much hassle
- No special query language, since the schema would be used to generate the query as well
Cons
- Loses the field attribute names since Protobuf reduces the field names to ids in the binary format
- We have not explored indexes on such binary data. Without indexes, the working set for filtering should be small enough in the lines of 100Ks for performance. Refer the ‘Benchmarks’ section of this post for initial observations
- For now, the comparison of fields happens at the root message level, have not implemented comparison of partial set of attributes in a nested struct
- Because of the nature of operations at binary level, limited to membership of a field and equality checks on the value, range queries would need unpacking of the numerical values from binary format
Examples & Benchmarks
Protobuf Schema

Database Schema
CREATE TABLE IF NOT EXISTS bench_data_person( user_id serial PRIMARY KEY, d bytea);
Benchmarking conditions
- Randomly generated 2 million messages for the above proto and inserted into a table with the above database schema.
- Generated a test query with the following Python script
262588213843476Used the above hex with pbcontains in a SELECT query as follows:
262588213843476Observations & Outcome Snapshot
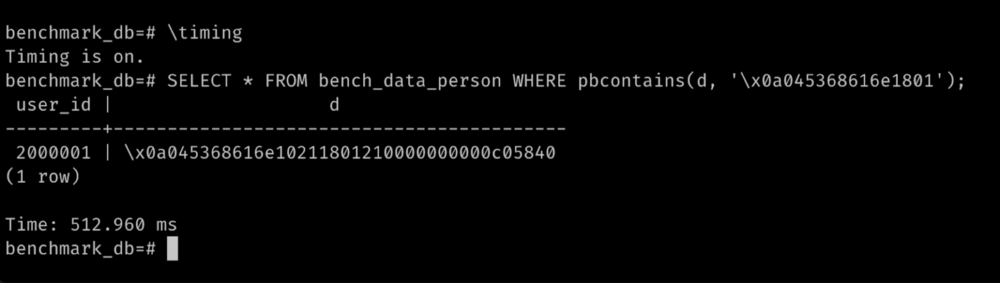
- Scanned 2 million rows and filtered them by the given membership check in 512 ms, without any indexes.
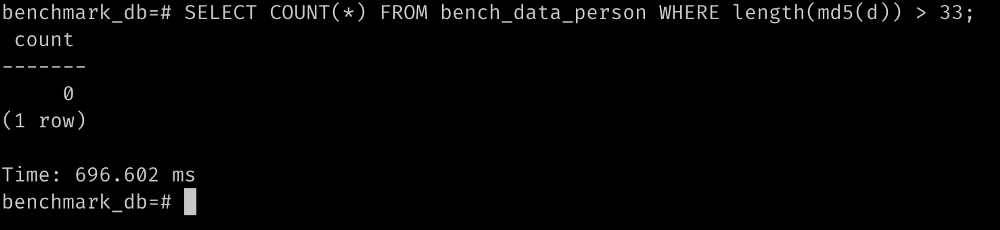
- For relative comparison sharing, here’s another query that operates on all of the rows
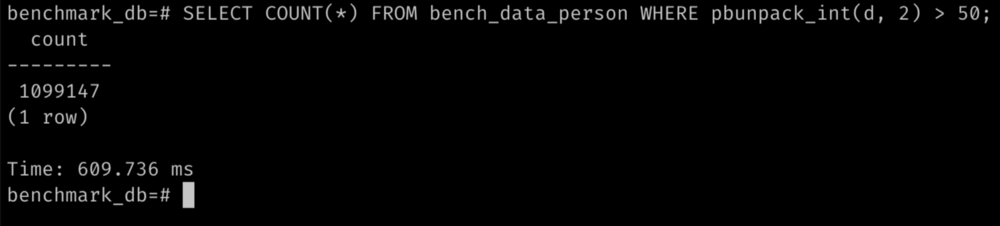
- Sample of a range query by unpacking the numerical value in the binary is as follows:
That’s the gist of our experiment with Protobuf. Hope you found it helpful. Keep watching this space for more insights!
