On Concurrency Control in Databases
A guide to how concurrency works in databases, and why it is important.
By Mohak Puri
What is concurrency control?
Applications nowadays handle a tremendous amount of requests. We deploy multiple instances of the same applications, fronting them with load balancers. Every request that comes in usually does something with a database. It either reads or updates the state of the database. If the databases we use handle only one request at a time (read/write), we would never be able to serve our users. Concurrency solves this by handling multiple requests at the same time.
This post deals with the need for concurrency control, and how to go about it.
Why do we need concurrency control
Before diving into how databases handle concurrency, let us first see why we need concurrency control in databases.
1. Dirty Reads
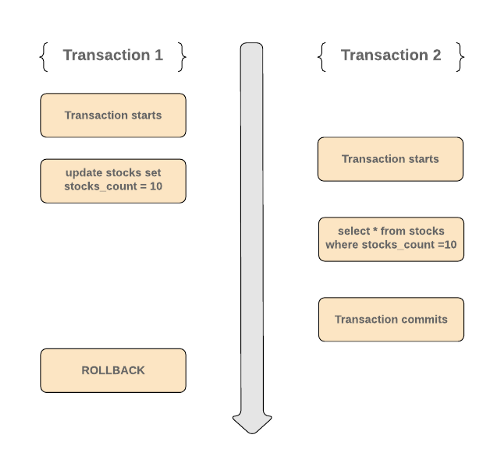
Consider the following scenario
- Transaction 1 starts and updates all
stocks_countto 10. During the same time, Transaction 2 also starts and reads all stocks withstocks_count=10. - Transaction 2 commits, but Transaction 1 still hasn’t committed. Maybe it is more than just updating.
- Transaction 1 fails at some point and the database rollbacks to the previous state.
- This means that the value read by Transaction 2 is wrong since all the updates made by Transaction 1 have been rolled back.
2. Non-repeatable Read
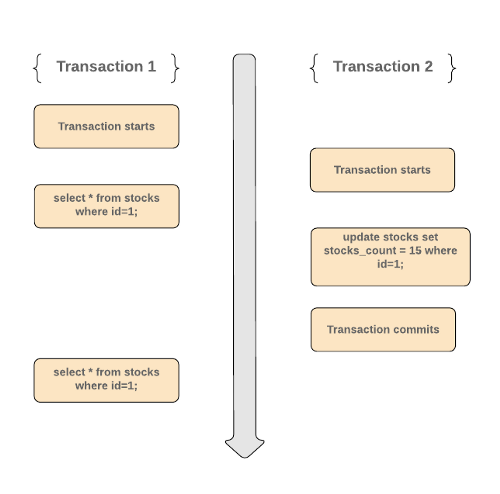
Consider the following scenario:
- Transaction 1 starts and reads a row having
id=1. Let’s say that it read the following data -
| id | stock_name | stocks_count | created_at | updated_at
| 1 | APPLE | 100 | 2019-06-01 | 2019-06-02- During the same time, another transaction starts and updates the record having id=1. It also commits after updating the record. Let’s say the updated record looks like this -
| id | stock_name | stocks_count | created_at | updated_at
| 1 | APPLE | 15 | 2019-06-01 | 2019-06-02- Now if Transaction 1 (which is still running) reruns the same query again it gets a different value as compared to the previous run. The values within the row differ between reads.
3. Phantom Read
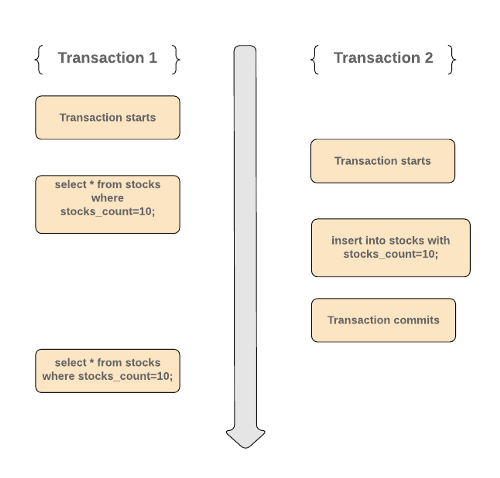
Consider the following scenario
- Transaction 1 starts and reads all stocks having
stocks_count = 10. Let’s say it read 15 such records. - During the same time, another transaction starts and insert another record with
stocks_count=10and commits. - Now when Transaction 1 reruns the same query again, it will get a different result. Now it will read 16 records since Transaction 2 has already committed its changes.
4. Serialization Anomaly
The Postgres documentation defines serialization anomaly as —
The result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.
So that means if there are two transactions T1 and T2, then there exists no way of committing them that is consistent with
- Committing T1 then T2 OR
- Committing T2 then T1
There are many ways databases can handle concurrency. We will go through the most popular ones.
How do databases handle concurrency
1. Two Phase Locking (2PL)

2PL divides the execution phase of a transaction into three different parts.
- In the first phase, when the transaction begins to execute, it asks for permission for all the locks it needs.
- In the second phase, the transaction obtains all the locks. As soon as a transaction releases its first lock, the third phase starts.
- In this third phase, the transaction releases the acquired locks. No new locks can be acquired in this phase.
Shared and Exclusive Locks
- Shared Lock (S):
A shared lock is also called a Read-only lock. With the shared lock, the data can be shared between transactions. For example, if there are two transactions that want to read some information about a particular stock the database will let them read by placing a shared lock. However, if another transaction wants to update that stock, the shared lock prevents it until the reading process is over.
2. Exclusive Lock (X):
With the Exclusive Lock, data can be read as well as written. As the name suggests, this is exclusive and can’t be held concurrently on the same data. For example, if a transaction wants to update some information about a particular stock the database will let them read by placing an exclusive lock. Therefore, when the second transaction wants to read or write, the exclusive lock prevents this operation.
Note: Different databases have different implementations of the same protocols. In this post, I will be focusing on Postgres.
2. Multi-Version Concurrency Control (MVCC)
As we saw in Two-Phase Locking
- Readers block Writers.
- Writers block Readers.
However, locking incurs contention, and contention affects scalability. The Universal Scalability Law demonstrates how contention can affect scalability.
Postgres and many other databases like Oracle maintain data consistency by using Multiversion Concurrency Control. This means that each SQL statement sees a snapshot of data (a database version) as it was some time ago, irrespective of the current state of data. This prevents statements from viewing inconsistent data produced by concurrent transactions.
The main advantage of using the MVCC model of concurrency control rather than locking is that
- Writers don’t block Readers
- Readers don’t block Writers
If you remember the ACID properties of a database, then hopefully you also remember the Isolation property of a database.
One of the goals of isolation is to allow multiple transactions to occur at the same time without impacting the execution of each.
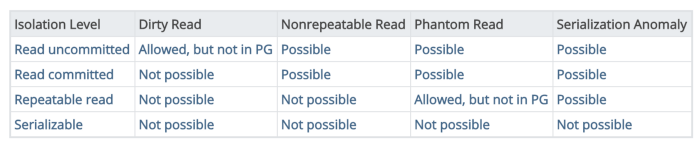
There are 4 different isolation levels with each of them solving some issues that can occur when concurrent transactions are running.
Isolation levels
1. Read Committed
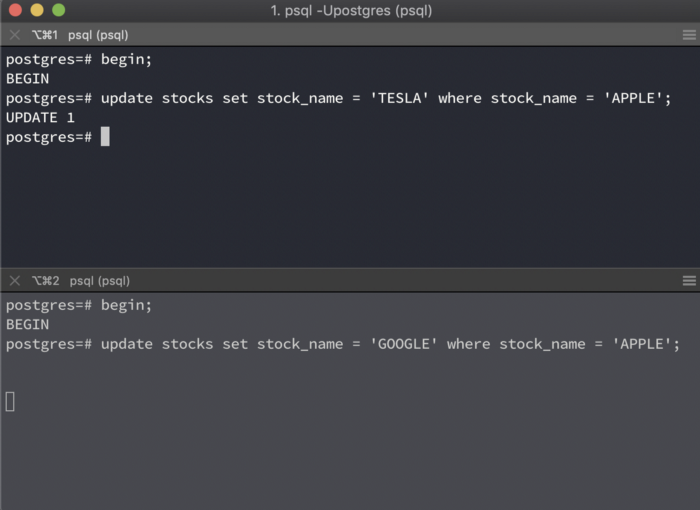
This is the default isolation level in Postgres. When using this isolation level, a SELECT query only sees data that was committed before the query began. It does not see any uncommitted data and data committed after the query began its execution. However, a SELECT query does see uncommitted changes made before it that are within its own transaction.
Consider the following example
// STATE OF DATABASE
| id | stock_name | stocks_count | created_at | updated_at
| 1 | APPLE | 100 | 2019-06-01 | 2019-06-02
// CASE 1:
BEGIN;
UPDATE STOCKS SET stocks_count = 10 where stock = 'APPLE';
SELECT * from STOCKS where stocks_count = 10; and stock = 'APPLE';
COMMIT;
// CASE 2:
BEGIN;
SELECT * from STOCKS where stocks_count = 10; and stock = 'APPLE';
COMMIT;
BEGIN
UPDATE STOCKS SET stocks_count = 10 where stock = 'APPLE';
COMMITIn the first case, the SELECT query will fetch the record with stocks_name APPLE and stocks_count =10 since the UPDATE (although uncommitted) was within its own transaction.
In the second case, if the UPDATE transaction commits before the SELECT transactions, then the SELECT query will fetch the record with stocks_nameAPPLE and stocks_count =10. If the opposite happens, then SELECT will return an empty list.
UPDATE, DELETE will only find target rows that were committed before the execution began. However, there is a chance that such a row might have already been updated (or deleted) by another concurrent transaction. In this case, the transaction will wait for the previous updating transaction to either commit or rollback (if it is still in progress).
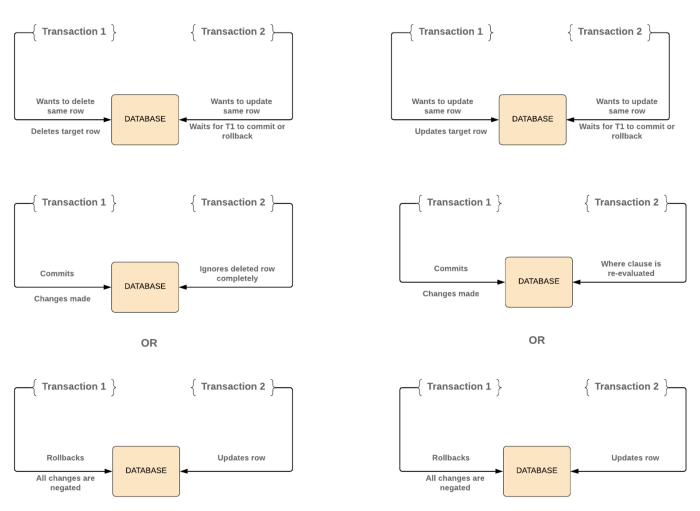
where’ clause.PostgreSQL’s Read Uncommitted mode behaves like Read Committed
2. Repeatable Read
This is a stronger isolation level as compared to Read Committed. Transactions can only see data that was committed before the transaction began (This isolation level is on transaction level, not query level). This means multiple SELECT statements within a transaction won't read different data since they can only see data that was committed before the transaction began. However, they will still see uncommitted changes made within their own transaction.
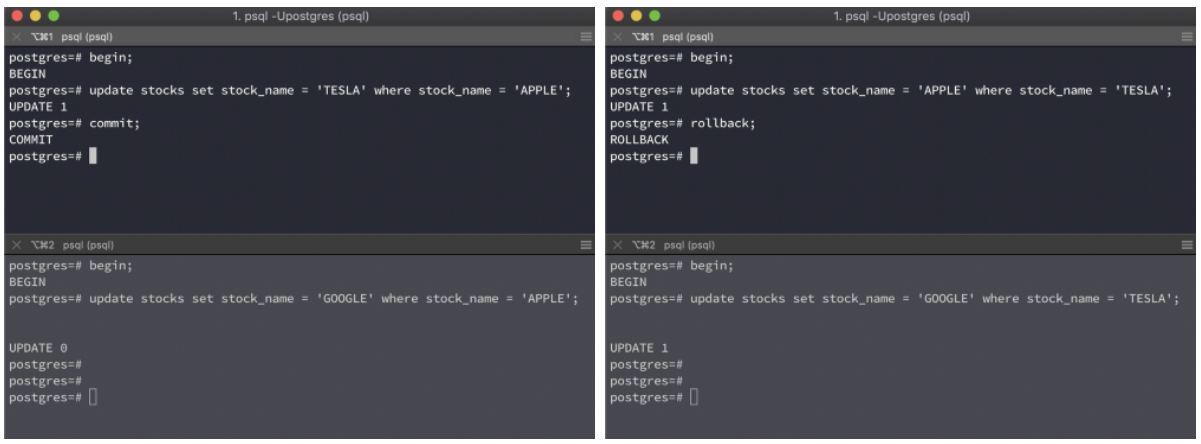
UPDATE, DELETE work similarly. The only difference is that if the 1st transaction commits, then the 2nd one will be rolled back with the following error:
ERROR: could not serialize access due to concurrent update.
This is because a repeatable read transaction cannot modify rows changed by other transactions after it has begun execution. In such a case, you need to abort the failing transaction and re-run it. Since this time the update will be in the ‘snapshot’ of the new transaction, there won’t be any conflicts.
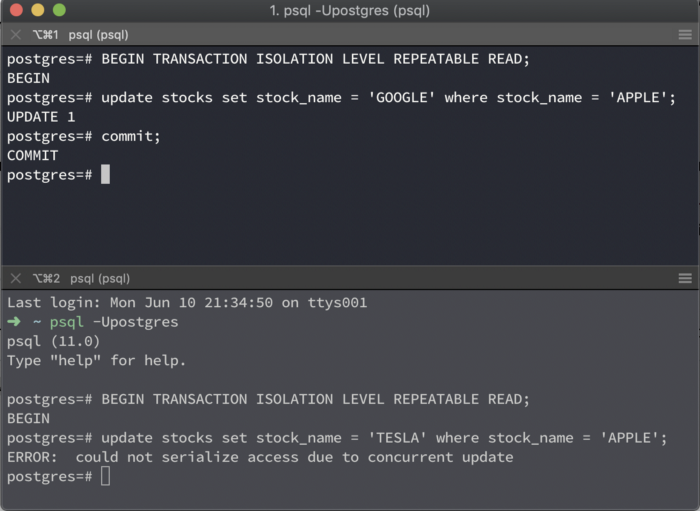
Postgres uses MVCC for handling concurrency but that does not mean it doesn’t use locks. MVCC minimises the use of locks.
3. Serializable
This is the strictest isolation level among all. In this isolation level transactions are committed as if they were running serially one after another and not concurrently. However, this transaction level can result in:
ERROR: could not serialize access due to read/write dependencies among transactions.
This error occurs when the database is inconsistent for all possible serial ordering of transactions that are trying to commit.
That’s about it! Thank you for reading, and I hope you enjoyed the article.
You can also follow me on Medium and Github. 🙂

You know what they say about learning on the job. When you’re building a Super App with 19+ products, tough challenges and learning opportunities are aplenty. Did we mention that we’re hiring? Check out gojek.jobs, it might just be your best learning experience yet. 🖖
