Modularizing Our Driver App For Android: Benefits & way ahead (Part-3)
Here's Part-3 of this series, where we detail the benefits of modularizing the driver-app at Gojek.

By Ashish Pathak
In the first two parts of this blog, we wrote about why we needed to modularize our driver app and the process behind it. Check them out below:
 Gojek
Gojek Gojek
Gojek
Before we delve into the benefits we reaped from modularization, here’s a TL;DR on why we felt the need to do so in the first place:
- Faster builds
- Faster feedback loop on IDE
- Enforced separation of concerns by design.
- Team wise productivity metrics
Now that we had extracted out quite a number of modules, it was time to analyze how we were doing on those parameters. Here is what we noticed:
Fast builds ⏩
As we started removing the code from the app module, we started noticing that a few builds would be slow. But after those builds, the cache would be populated and that benefited us in subsequent builds. Eventually, our CI build times reduced from about 30 minutes, to little over 20 minutes.
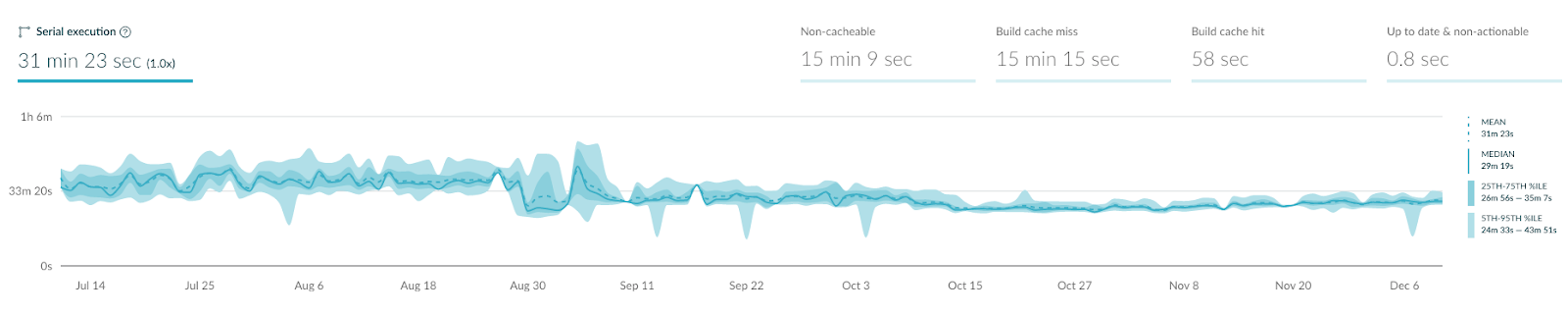
Faster feedback loop on IDE 🔄
When we had started modularizing the driver app, we had 78% classes in the app module. After our exercise where we extracted out the core modules, utility modules and a few feature modules, we now have reduced 10% of the classes from the app module and distributed those across appropriate modules. So, now a total of 68% classes are still there in the app module. As we progress more and extract out some more features, this number will reduce even further. Naturally, when the number of classes goes down, the compilation time also goes up. This improves the build speeds. With modularization done, we now write our unit tests and instrumentation tests(with some custom setup) in the feature modules only. This makes our feedback cycle pretty fast because it doesn’t have to process the whole project.
Enforced separation of concerns by design ✍️
Because our features now reside in the feature modules, we need to be very explicit about what we accept as input from other features and what we provide to the other features. This makes our interfaces design pretty clean from the first time itself. As a side effect, the entanglement we had in our code is getting addressed automatically. Not only that, with clear interfaces as the requirement, even for relatively new programmers on the team, it is hard to mess up. The APIs and implementations are now decoupled which also results in less area being impacted by any change.
Team wise productivity metrics 📊
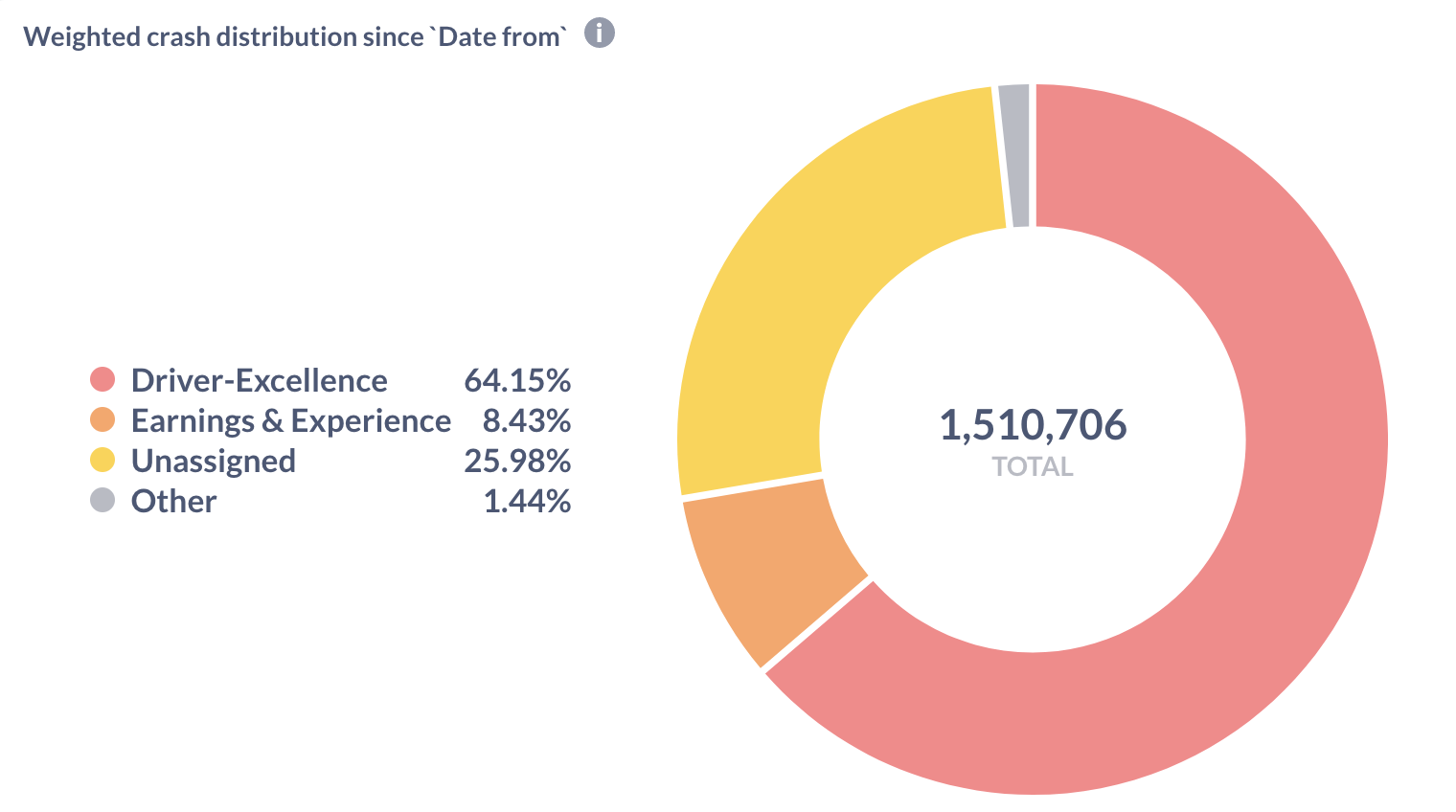
Remember our management wanting to know about team-wise productivity metrics in order to decide where to optimize and what to optimize? With modularization in place, we could define code and feature ownership very easily and succinctly. This enabled us to add monitoring and alerting for things like:
- Test coverage
- Binary size added per feature
- Crashes per feature
- Feature ownership
- Impacted area only test runs
Recap
- Modularising the application is not easy
It is especially difficult to modularize existing monolith apps than to write modularized apps from the beginning. Also, it is a time consuming process. It takes careful planning and execution to do effectively. - Identify core business requirements and data flow before proceeding
To make a modularization project successful, we need to carefully identify core business requirements and the data flow. These requirements become part of the core modules. Identify tech requirements and reusable components and these become the utility modules. - Put automated checks(guardrails) in place
We need to put enough guardrails in place to make sure that the core and utility modules are not abused and they do not become the dump ground for common logic. Just because it is used at many places does not make it a candidate for core or utility modules. Careful thought must be given to ensure how some common logic needs to be shared across the project. Once the core and utility modules are identified and extracted out, we can move to extracting out the features.
- Not everything can be automated
We still need to rely a bit on manual code reviews to keep the code clean and protect common modules becoming a dumpground for any common logic. What helps is to assign reviewers automatically when certain part of the code changes. Remember, we now can more clearly define the code owners. - Identify the inputs and outputs for each feature
For feature modules, it is essential to figure out what are the inputs to the feature and what are the things the feature shares. Based on this information, we should define the API and the implementation modules. This would have two major benefits:
- The interfaces to and from the feature will be crystal clear. It will be easy to figure out what the feature expects and what it provides.
- Since the API and implementation are now separate, we can experiment with different approaches, UI and architectures inside the feature. Even each feature can have its own approach, architecture, and way of working.
When the features are structured this way, we get a lot of freedom to experiment with different architectures, design patterns, and ways of working in smaller areas of the apps.
Modularizing our driver app has tremendously helped us in experimenting with different architectures and design patters. It has also enabled us to clearly define code ownership and engineering metrics to track.

To read more such stories from our vault, check out our blogs.
Check out open job positions here.