Merlin: Making ML Model Deployments Magical
Kubernetes-friendly ML model management, deployment, and serving.

By Yu-Xi Lim
Continuing our series on Gojek’s Machine Learning Platform, we tackle the problem of model deployment and serving in this article.
“I have trained my ML model. What’s next?”
A data scientist’s job does not end when they have trained their model. The next steps are typically some of the most time-consuming and require expertise outside of normal data science work.
The first thing a data scientist would encounter when trying to deploy and serve their model is the myriad tools and workflows. Most data scientists use Python or R, dozens of ML libraries (Tensorflow, xgboost, gbm, H2O), and are familiar with Jupyter notebooks or their favorite IDE. However, model deployment and serving introduces a whole new universe of technologies: Docker, Kubernetes, Jenkins, nginx, REST, protobuf, ELK, Grafana, are just some of the many unfamiliar names that a data scientist might encounter when they try to get their work into production.
In order to get them through this jungle, data scientists typically partner with a software or infrastructure engineer to guide them. They will work together to set up build and deployment pipelines, monitoring and alerting systems, microservice wrappers, and other critical automation and infrastructure.
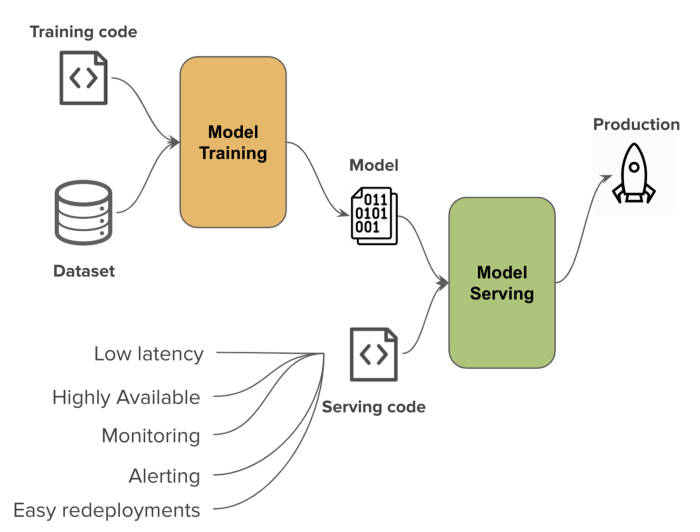
There are usually a lot of engineering concerns that go into designing and building a production system. We want low latency, high availability, and cost-efficiency as part of the service level objectives. These are enforced through robust monitoring and alerting. Finally, we expect that the model we are deploying is but the first of many, so we will need to support easy and safe redeployments through canaries, blue-green deploys, and other standard practices, allowing us to iterate and refine the models.
All these result in longer time-to-market and longer development cycles. Data scientists are frustrated at not being able to see the fruits of their labor. Business and product managers wonder what is causing the delays. Engineers are being interrupted to help with the tedious task of walking the data scientists through the technology and processes…
Merlin makes model deployments magical
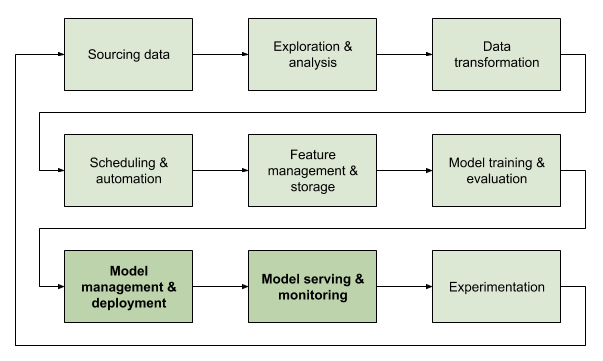
Merlin is a new addition to the Gojek ML Platform. It comes in towards the end of the ML life cycle, addressing the deployment and serving needs of data scientists.
With Merlin, we aim to make ML model deployment and serving:
- Self-serve: First-class support for Python and a Jupyter notebook-first experience.
- Fast: Less than 10 minutes from a pre-trained model to a web service endpoint, allowing for fast iterations.
- Scalable: Low overhead, high throughput, able to handle huge traffic loads.
- Cost-efficient: Idle services are automatically scaled down.
Merlin brings several best-in-class features to the table:
- Support for widely used model types such as xgboost, sklearn, Tensorflow, PyTorch.
- Support for user-defined models via arbitrary Python code.
- Traffic management allows canary, blue-green, and shadow deployments.
- Out-of-the-box monitoring for common key metrics.
With Merlin, we aim to do for ML models what Heroku did for Web applications, with dead-simple deployments, wide support for existing technologies, and easy scalability and extensibility.
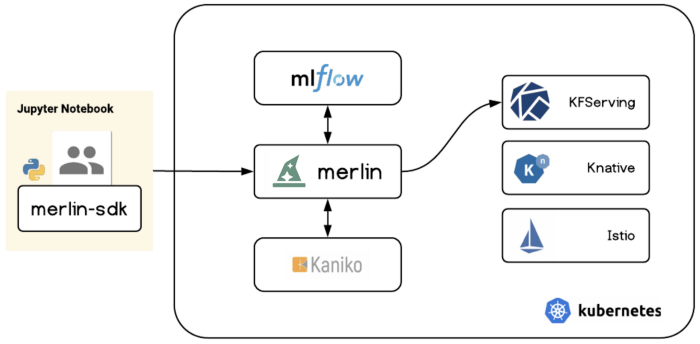
Under the hood, Merlin brings together some of the latest open source technologies. We use Kubernetes for our production services, and leverage KFServing, Knative, and Istio there. Model artifacts are managed using MLflow while Docker images are built on Kaniko.
Workflow walkthrough
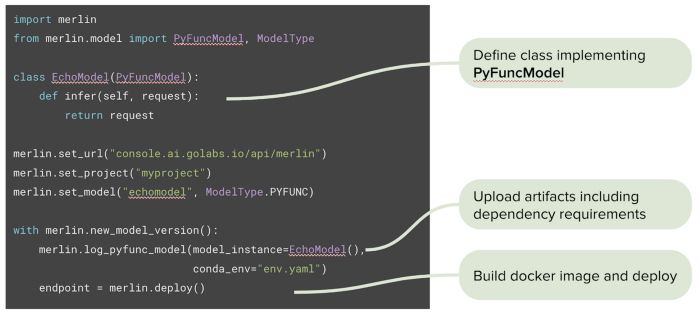
The data scientist starts in the familiar Jupyter notebook, importing the Merlin SDK. From there, they can either deploy one of the standard models we support:
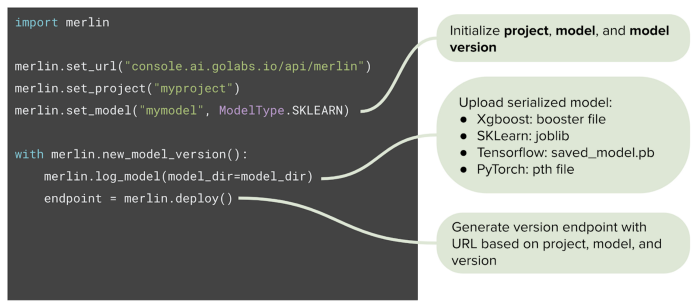
Or implement their own user-defined model:
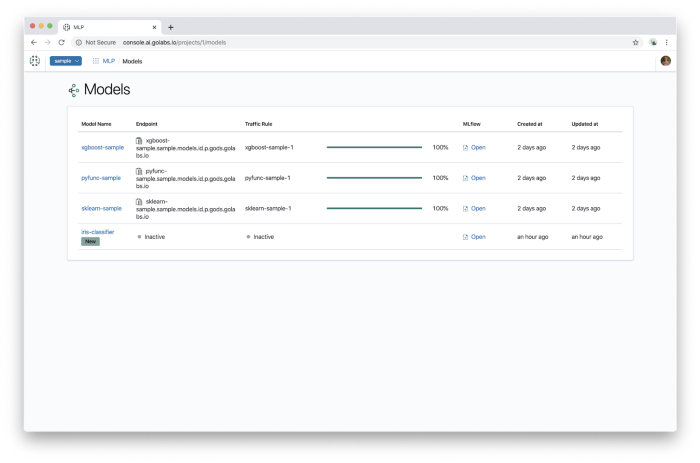
The deployment process takes a few minutes and can be monitored through the Web UI of our ML Platform console:
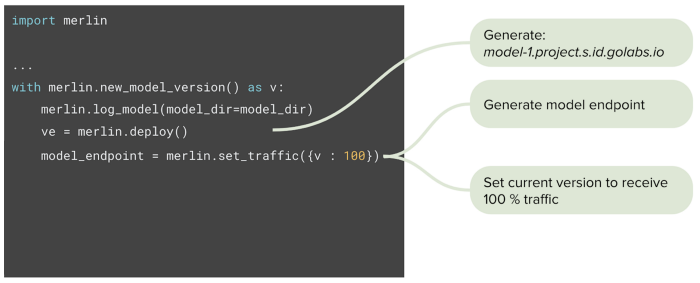
When the model serving endpoint is ready, the data scientist can also control the traffic routing to the new model and other models:
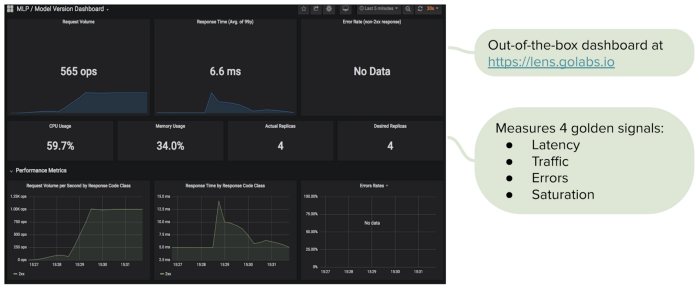
The data scientist can also monitor the health of the new model service on Gojek’s internal monitoring platform:
What’s next?
Despite being a relatively new project, Merlin has received very favourable responses from Gojek’s data scientists and we are gradually rolling it out to more production systems.
At the same time, we are developing many new features such as stream-to-stream inference, gRPC support, and more user-friendly log management. Model serving is also closely related to experimentation, which we will cover in a future article. 👌
If you are excited by the idea of developing such tools for data scientists, please consider joining Gojek’s Data Science Platform team.
Contributions from:
Arief Rahmansyah, Pradithya Aria Pura, Roman Wozniak
