It's Time To Find And Kill Bugs
Here's how to create and maintain a great test suite that minimizes the time to eliminate bugs.

By Prathik Rajendran M
Most of us might have come across a situation where a test suite has been created with great vigor and good intention at the start of a project, but with time it gets degraded to a point that running the tests every time is costlier than the positive impact it gives. This is a very common problem and generally, test suites do not get the same tender love and care that product code does.
In most situations, what happens is that the test suite degrades, then slowly the confidence to make changes to the service goes down. It tends to get slower and slower to build features and make changes to the service and finally some one deems the service as legacy. Post this, there is a proposal for re-architecture, the team is again in full vigor creating test suites and the cycle continues.
We need to break this vicious cycle. While re-architecture is fun and exciting, it’s also a waste of human time. Building a system that does the same thing again because the previous system is hard to maintain is just sad. Why not save all that time by just putting just a little effort continuously to ensure the existing system is maintainable?
Writing good tests is a key lever to break this vicious cycle. But what do we even mean by a good test suite?
The main thing a test suite needs to do is minimize the time to find and kill bugs.
That simple principle is the guide to creating and maintaining a great test suite. Now let’s look at the implications of this principle, or how do we apply this principle in practice? What do I need to do to ensure that a test suite adheres to the principle above?
Ensure that most of the bugs get caught in the fastest tests
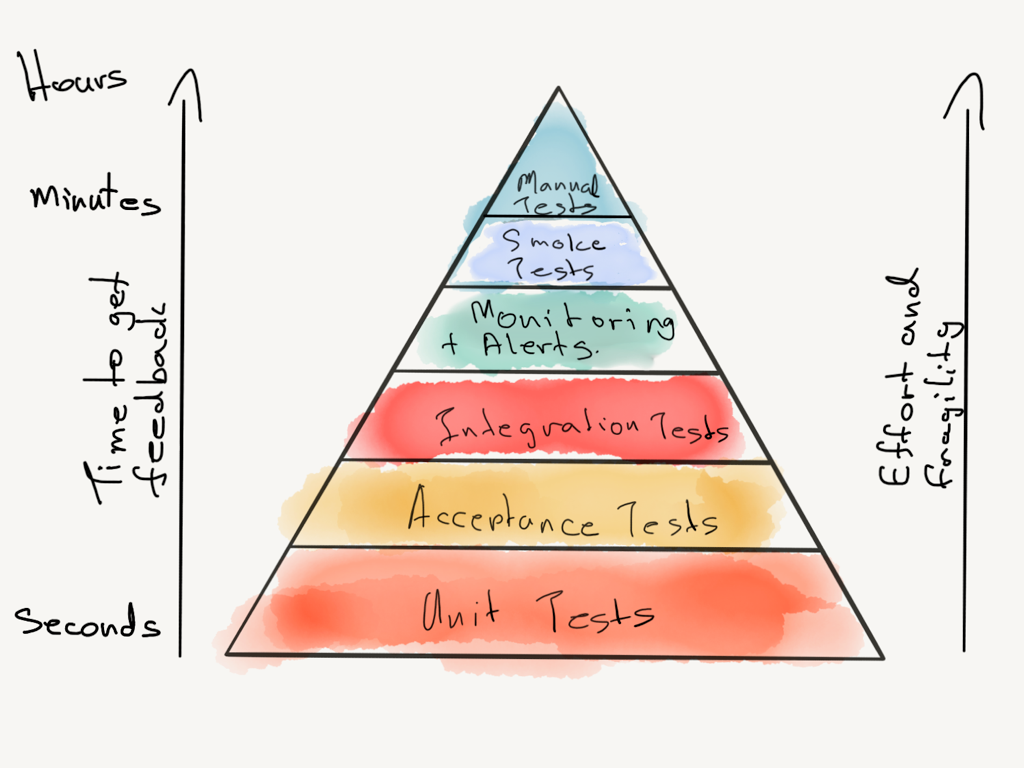
This practice essentially means follow the testing pyramid, don’t invert it.
One observation I have made over the years, especially when you have a culture where quality is owned by the QA team, is that the E2E test suite gets bloated. Any bug in the system is added to the E2E test suite that makes the E2E suite itself slower and second leads to a lot of false positives in the E2E suite. While it’s important to have an E2E suite that captures key business flows, too much of it is a recipe for disaster.
This is a qualitative or subjective practice but what you need to look for is how many bugs are my unit tests surfacing vs the other test suites.
Questions to ask:
- Do we have unit tests, component tests (mocked externals), integration tests (database, file system), e2e tests with actual dependent services in a staging environment at varying degrees of execution speed or do we just have one set of unit tests and another set of E2E tests?
- Do most of our bugs get caught in the local dev environment or does it have to go to the integration environment?
- Are our tests for domain model and business logic separate from our tests to make over the wire calls (database, other service)?
Remove / Reduce the Man-In-The-Middle
In other words, reduce the need for manual QA in-order to go to production. Manual testing is slow and always subject to human error. It’s a waste of human time to be spending doing the same thing over and over again to check if something is working fine, this needs to be automated both from a speed and correctness standpoint. In some cases we have to be pragmatic and rely on manual testing but if this is not an exception but the rule then you are doing it wrong.
Every new bug caught is added to the test suite

Look, bugs happen and don’t get caught in our QA suite, it’s a fact of life, but failure without learning is bad. How can we ensure that a failure that happens once, never happens again? We do this by checking if that bug is present very often, in fact check it daily / hourly. How do you do that? Automate detection of that issue.
Start with identifying the state and the input to the module that led to the bug and nail it down to the most minimal number of components needed to reproduce the state and the input. This step ensures that the tests written adheres to the first practice.
Once you have identified the components and state, reproduce the issue in your automation suite and you should be able to see the error via an automated test failure. This ensures that the bug is caught in the test suite.
Finally fix the issue and take the fix to production. Generally teams tend to panic and do a hot-fix and push the tests later, that is fine if your time to write tests is long, but if this is happening too often optimize the cycle time here as well by having better component abstractions, ability to mock and so on. In general the need to push hot-fix without a test is a red flag but at times exceptions can be made to the rule, but as mentioned above it should not be the rule.
These steps seem eerily similar to TDD, because they are, so that brings us to the next practice.
Practice test driven development / test first development
We need to ensure that tests catch bugs but how do we do that? It’s really simple, imagine that the feature was present in the code base but not working properly, that is it is a bug, given that it’s a bug, write a test to catch it, this test will fail obviously because we are imagining that the feature exists, it’s all a dream! Now we know that if the feature was indeed present and failed it would get caught by the test suite, now write a fix for it and see the test pass, there you go, proof that the tests work and the imaginary feature becomes real, can it get any better than this?
The practice (my variant) in simple terms
- Imagine that the feature exists
- Write a test for that feature, this test will fail
- Now come to reality and write just production enough code to make the failing test pass
- Go to step 1
The other advantage is that TDD acts as a forcing function to ensure that the tests are fast. How does it do that? TDD encourages you to run tests often, when tests are slow it becomes a pain to run often and thus to avoid this pain developers will ensure that the tests are easy and fast to run.
Have low false positives in your test suites
As the key principle goes you need to optimize the time to find and kill bugs. If you have a false positive (test tells that there is a bug when in reality there isn’t any) among many other actual bugs then time is wasted by your test suite in hunting down an imaginary bug.
It also hampers overall effectiveness of the test suite because people will start to ignore test failures. This is especially true for E2E test suites, generally they have lots of false positives. People ignore or stop doing work that does not add value, tests that make people go after non-existent bugs are actually not adding value, therefore people will stop going after / solving the bugs shown by the test suite.
Root cause of test failure should be easy to catch
As pointed above tests are written to catch bugs, the more we can isolate a bug, the easier it becomes to catch the issue. It’s ideal to keep each test to focus on catching one bug, so start thinking about the bug you want to catch and then think of the minimal reproducible example using your code base to reproduce this bug. This ensures that when a test issue does happen it’s easy to fix it thus optimizing the time to find and kill bugs.
Another common notion is to have one assert per test but this isn’t practical all the time, however what you should do is to have a descriptive message on an assert failure and also give pointers to where the issue could be in the messaging.
In conclusion
All said and done, writing good tests is just as much an art as it is to write production code and as with any art, practice makes perfect. The above principle and practices serve as the right direction you need to follow while writing tests and doing it more often makes you get better and better at it, thus don’t just stop with reading this article but learn by doing it and evangelize these practices and benefits within your teams.

Check out more blogs from our vault here.
Oh, if you’d like to join us, check out open job positions:
