Introducing Meteor, Our Open Source Metadata Collection Framework
Meteor is an easy-to-use, plugin-driven framework to extract data from different sources and sink to any data catalog.

By Muhammad Abduh
We process more than petabytes of data every day at Gojek. This data could come from various sources like data stores, services, message queues, etc. It could have different properties and types such as transactional, analytics, time-sensitive, which could also be wandering through multiple systems. The abundance of data are roaming around with their own format, e.g. JSON, Protobuf, Avro, etc., and also have their own schema and metadata.
What is Metadata?
Metadata is the information describing one or more aspects of a specific data. Various systems, database Systems, message queues, have their own contextual data definition and structure. For example, table is part of Database Systems that group data. In message queuing system like Kafka, this is similar with topic. A single table is also usually explains a single context of information, e.g. entity information, relation information, etc. The Metadata could have information like what tables that a system has, what columns does each table has, who is the owner of that table, who has an access to that table, etc. These metadata information are useful to understand the data better.
In Gojek, we always try to ship better product by improving our features, user experience, and solutions. When dealing with the data within that scale, the possibility to have ever-changing metadata is also higher. Since we are treating the data as a first-class-citizen in our day-to-day work, the need to better understand the data and know what data that is available is also demanding. We need to figure out a way to manage the metadata so each of us could keep up-to-date with the changing context of the data. By doing so, it would also help to adapt the changes of metadata in all system dependencies that becomes more challenging.
Introducing Meteor
One of several challenges that we need to address is about how do we collect metadata effectively. We need a tool that is easy to use, reusable, portable, and flexible enough to be modified to meet generic use cases.
Here comes Meteor, a plugin driven agent for collecting metadata. Meteor’s job is to extract metadata from a variety of data sources and sink the metadata to variety of third party APIs. The agent would create a periodic job defined by a contract called recipe written in a yaml file. It is written in Golang and has zero dependency, which means it will have small memory footprint and portable enough to run it.
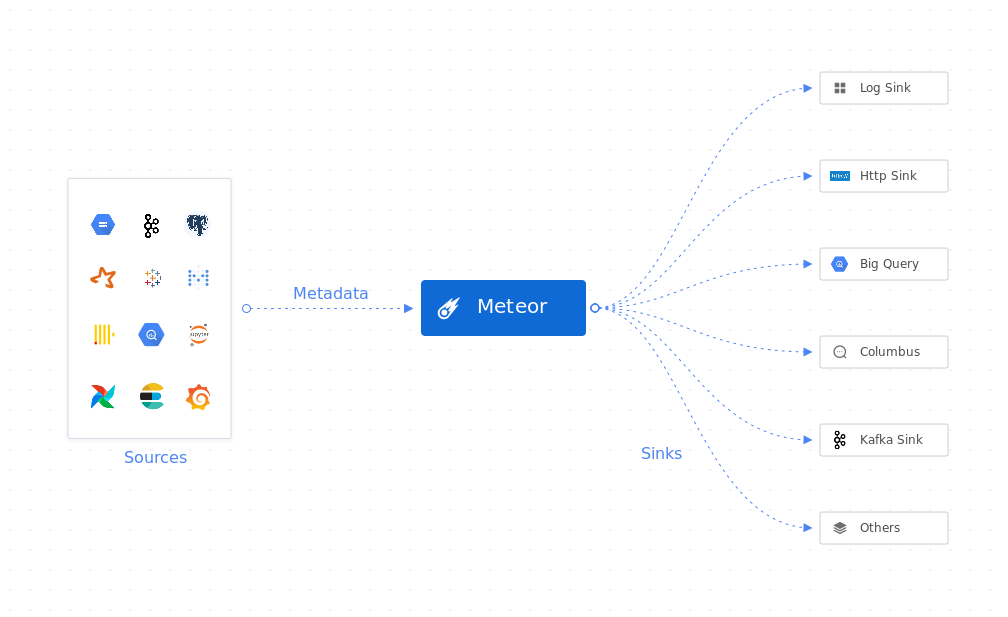
There are three stage of process defined in Meteor: Extraction, Processing, and Sink. Extraction is the process of extracting data from a source and transforming it into a format that can be consumed by the agent. Processing is the process of transforming the extracted data into a format that can be consumed by the agent. Sink is the process of sending the processed data to a single or multiple destinations as defined in recipes.
Meteor Plugins
Meteor is developed with plugin-driven system where each stage of processing could be done by its own plugin. Therefore, there are three types of plugins in Meteor. Extractors are the type of plugins that extract the source of metadata. There are currently multiple plugins supported to extract metadata from various sources including databases, dashboards, topics, etc. Processors are the set of plugins that work for processing stage to perform the enrichment or data processing for the metadata after extraction. The last type is Sinks that are the set of plugins that act as the destination of our metadata after extraction and processing is done by agent.
Here are the sample of recipe written in yaml that describe the job. The recipe list down the plugins for each stage, sourceplugin, processors plugin, sinks plugin. Each plugin in meteor supports configs so it is customizable and tailored to any use cases.
name: main-kafka-production # unique recipe name as an ID
version: v1beta1 #recipe version
source: # required - for fetching input from sources
name: kafka # required - collector to use (e.g. bigquery, kafka)
config:
broker: "localhost:9092"
sinks: # required - at least 1 sink defined
- name: http
config:
method: POST
url: "https://example.com/metadata"
- name: console
processors: # optional - metadata processors
- name: metadata
config:
foo: bar
bar: fooMeteor’s plugin system allows new plugins to be easily added. With 50+ plugins and many more coming soon to extract and sink metadata, it is easy to start collecting metadata from various sources and sink to any data catalog or store.
Try Meteor — it’s open source!
Meteor has a rich features of CLI that would help user interact with meteor better. User could do several actions from listing all supported plugins to generate a recipe. For mac users, it provides brewed formula so installing it would be as easy as running:
brew install odpf/taps/meteorWe also provide helm chart for it to run Meteor as kubernetes cron job so deploying it would not be a hassle.
Take a look at meteor documentation here or another project of us in odpf github repository to explore more.
Excited with the work that we do with odpf? Check out open positions here:


To read more stories from our vault, click here.