IndoNLU — A benchmark for Bahasa Indonesia NLP
Introducing a collection of resources for training, evaluating, and analysing natural language understanding systems in Bahasa Indonesia.

By Li Xiaohong
Back in mid-2020, we wrote about how ‘Cartography Data Science’ team developed CartoBERT, a Natural Language Processing (NLP) model. CartoBERT presents customers using GoRide and GoCar with more convenient and clearly named pickup points for a frictionless experience. The project was successful and generated many new pickup points for us.
Read more, here:
Inspired by the success, we went on to collaborate with a team of data scientists and researchers to develop various benchmark datasets and state-of-the-art deep learning NLP models for Bahasa Indonesia (Indonesian). Our first project in this collaboration is ‘Indonesian Natural Language Understanding’ (IndoNLU), to benchmark tasks and models.
The IndoNLU
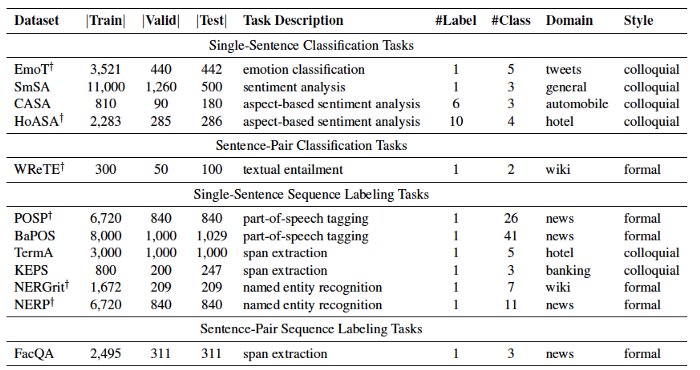
IndoNLU benchmark is a collection of resources for training, evaluating, and analysing natural language understanding systems for Bahasa Indonesia. It includes twelve tasks which can be categorised into four types based on the input and object:
- Single-sentence classification
- Single-sentence sequence-tagging
- Sentence-pair classification
- Sentence-pair sequence labelling

The benchmark tasks are designed to cater to a range of styles in both formal and colloquial Indonesian.
They’re highly diverse and include emotion classification, sentiment analysis, entailment analysis, pos tagging, key phrase extraction, named entity recognition, extractive question answering, etc.
The Indo4B
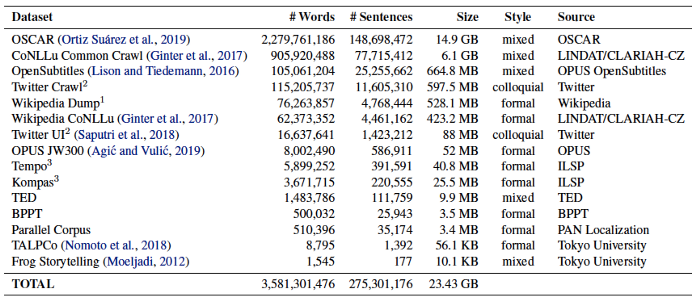
Furthermore, we collected a large-scale clean Indonesian corpus from online news, articles, social media, Wikipedia, subtitles from video recordings, and parallel datasets and named it Indo4B.

Fun fact: The name Indo4B came to be, because it contains around 4 billion words and 250 million sentences! 😄
The IndoBERT
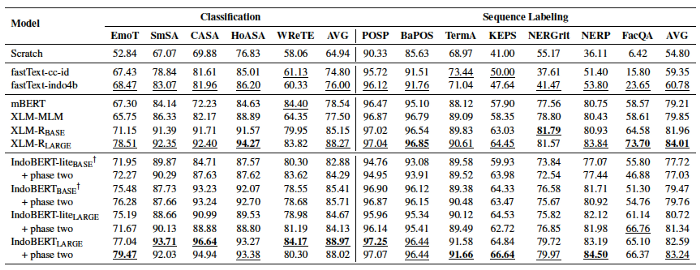
We pre-trained 2 families of deep learning models:
IndoBERT (based on BERT) and IndoBERT-lite (based on ALBERT), on Indo4B datasets.
We also extensively compared our IndoBERT models to baseline from non-pre-trained models (from scratch), different pre-trained word embeddings, and existing multilingual pre-trained models, such as Multilingual BERT (mBERT) and XLM-R. This was done to measure the effectiveness of our IndoBERT models. Our pre-trained models outperformed the existing pre-trained models on most of the tasks! 🥳
We’re happy to announce that our paper has been accepted at AACL-ICJNLP 2020. We also released the pre-trained models on huggingface. In order to promote community engagement and benchmark transparency, we’ve set up a leaderboard website for the NLP community.
If you’re curious about the dataset and code, you can find them here.
Thanks to all the amazing people who contributed to this the paper and project:
Bryan Wilie (Center of AI ITB), Karissa Vincentio (Universitas Multimedia Nusantara), Genta Indra Winata (The Hong Kong University of Science and Technology), Samuel Cahyawijaya (The Hong Kong University of Science and Technology), Zhi Yuan Lim (Gojek), Sidik Soleman (Prosa.ai), Rahmad Mahendra (Universitas Indonesia), Pascale Fung (The Hong Kong University of Science and Technology), Syafri Bahar (Gojek), Ayu Purwarianti (Institut Teknologi Bandung and Prosa.ai), Pallavi Anil Shinde (Gojek).

Want to read more stories from the vault? Check out our blogs!