How we use Machine Learning to match Drivers & Riders
Building Jaeger: Our driver allocation system harnessing Machine Learning and real-time features to optimise multiple business objectives

By Peter Richens
The Allocation problem
GO-JEK is a marketplace with dozens of products, hundreds of thousands of drivers and merchants, and millions of customers. We decide which driver to ‘allocate’ millions of times each day, and this decision-making process is central to our business. We have huge amounts of data to optimise our decisions but we must take account of multiple and dynamic objectives to balance the needs of our drivers and customers.
This is one of the first problems the GO-JEK Data Science team took on. Our first solution was a stand-alone Machine Learning (ML) model and web service to rank drivers. This broke new ground for the company, was deployed to production within weeks and delivered large business impact.
However it soon became clear we could do better. A single ML model struggled to balance multiple business objectives. Worse still, retraining on the allocation data generated by the model itself introduced unintended feedback loops. The algorithm became biased towards solving certain problems (eg. increasing driver acceptance rates) at the expense of others (eg. lowering pickup times).
Closely monitoring market efficiency and driver fairness, we found that the model consistently de-prioritised some drivers. As GO-JEK grew we scaled to more services, cities, and countries. It became difficult to handle and A/B test different versions of the model. We were also restricted in our ability to exploit real-time features for more responsive allocation decisions.
Jaeger: a multi-objective allocation system
These challenges motivated us to build a new system for multi-objective allocation. We wanted to combine ML models and real-time features with a high degree of flexibility and manual configuration. We lovingly call it Jaeger after the humanoid mechs of Pacific Rim that interface a machine with the brain of a human pilot. It also reflects our desire to harness ML to serve our business needs.
Jaeger aggregates the outputs of different driver ranking models, using goal programming to optimise for our multiple business objectives such as improving consumer experience and ensuring fair order allocation among drivers. To be able to do that, the Data Science team have created models to optimise for different things. Currently, our models are optimised based on driver’s performance related matters, such as:
- Driver’s acceptance rate
- Driver’s completion rate
- Driver’s rating
Since we always want to allocate the best driver for the job, Jaeger does not have any filters based on type of fleet. For example, if we have bicycles and motorcycles in the 2W universe, both of these fleets will be considered the same. Same goes for regular GoCar fleets and taxi fleets in the 4W universe. The models work to provide benefits for customers and drivers — closer distance to the consumer will ensure shorter waiting times and curating drivers based on their ratings ensures better service. This process is fully automated through algorithms.
Machine learning models
From the outset, we planned to deploy multiple driver ranking models, each optimising for a specific objective. By far the most important step has been carefully framing each prediction problem. This has allowed us to minimise bias and harmful feedback effects which were detrimental to our original ML model. In some cases this was as simple as filtering some observations from the training data, but these decisions amplified our business impact by an order of magnitude.
In many cases what we predict is much more important than how well it is predicted, making it critical to iterate, test and evaluate model changes online rather than rely solely on AUC, precision-recall or other offline validation metrics.
We have experimented with various models including gradient-boosted decision trees and neural networks. But for a given set of features, performance differences across models have been minimal. We therefore focus most effort on feature engineering. Relatively simple aggregated features for drivers, customers, geographic areas and merchants have had the largest impact, particularly as these features can easily be ingested into our centralised feature store and reused across models. Stacking models is another promising strategy. For example, we use an Autoencoder to generate driver-level anomaly scores which can then feed into other models.
Training and deploying so many models to serve different objectives, service types and cities was a daunting challenge. More so as the stationarity period of our training is relatively short, making it important to refresh the models often. We perform all our batch ETL and model training using an in-house scheduling platform called Clockwork, an extension of airflow that runs on Kubernetes. We use mlflow to keep track of different model versions, hyperparameters and performance metrics. After training and validation, we automatically trigger the deployment of updated models.
System design
Jaeger is a system of modular and easily extendible components. We benefited from the awesome work of our Data Science Platform team, who built many of the foundational blocks. We have plans to open source several of these projects soon. Some of our Open Source projects.
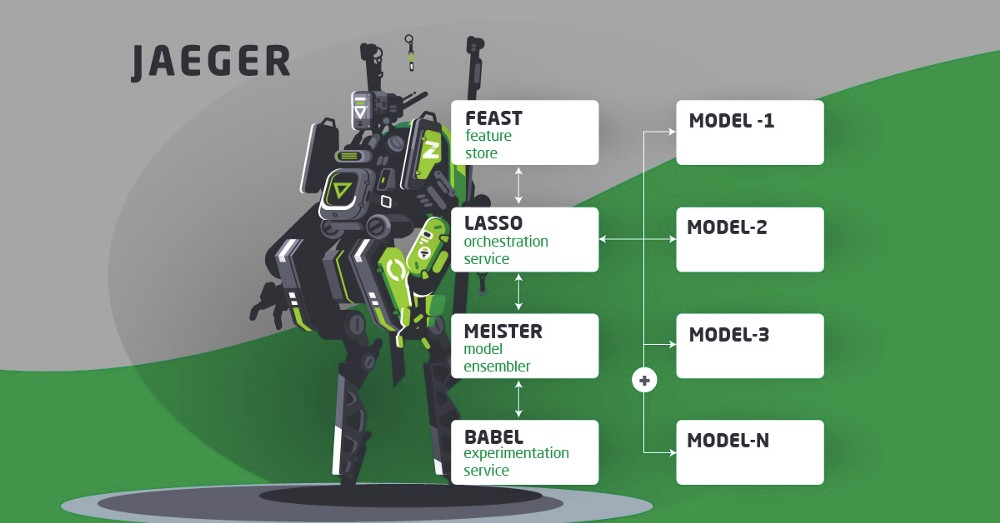
Lasso
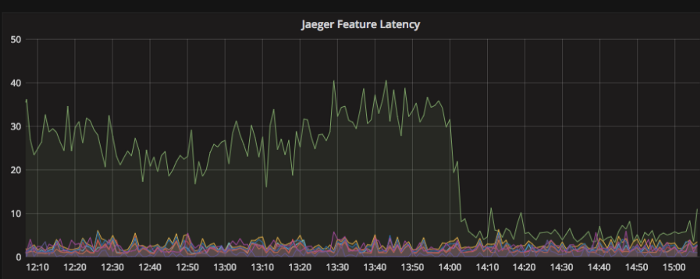
This service acts as the orchestrator for each driver ranking request. Lasso makes HTTP calls to multiple microservices that fetch features or wrap the models responsible for the actual allocation logic, which we can implement in the most suitable language for the task (currently we use Go and Java). Lasso’s workflow and defaults in case of failure are defined using yaml and Go templates. This makes it easy to add additional models as new business objectives emerge. Lasso also handles the logging of each request and response critical for evaluating and debugging model performance.

Feast
Our Feature Store, or in-house platform to ingest, store and retrieve ML features, for both training and serving. Feast allows us to fetch features for multiple models simultaneously and solved a number of technical problems we faced with previous ML deployments. It serves 1000s of lookup requests per second at low latency while ensuring consistency with our training data. We will give more details in a future blog post.
Meister
Jaeger’s meister or master (any resemblance to the liquor is purely coincidental 😉) is the final microservice called by Lasso. It aggregates the outputs of the different driver ranking models, using goal programming to optimise for our multiple business objectives. Jaeger-meister also manages our A/B testing framework and provides flexibility in configuring which models to apply in given locations, at different times, and even for different customer segments. If need be we can, for example, trade-off market efficiency and driver fairness with a simple config change.
Babel
We have abstracted various Bayesian A/B testing techniques as a Python library, which we use in a custom web UI to evaluate Jaeger’s impact on a range of business metrics.
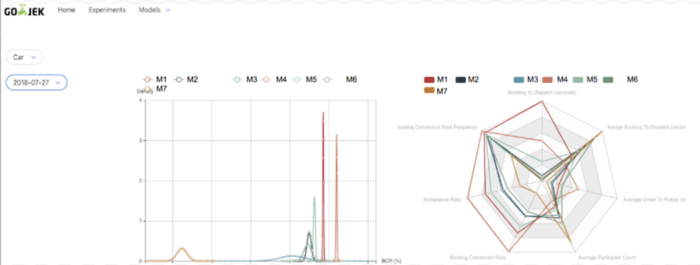
Order Allocation Simulation
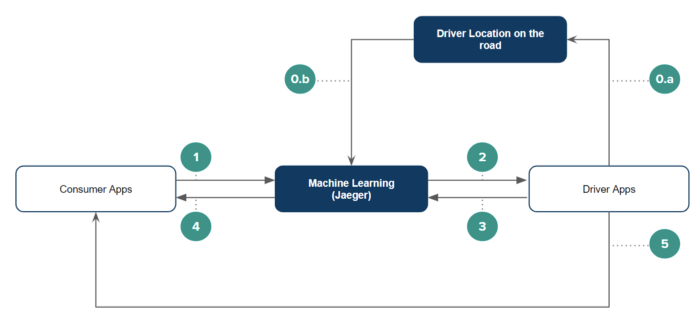
0. Data Gather
a. Every 10-20seconds, active drivers apps send data on their allocation to Driver Location on the Road (“DLOR”); and
b. DLOR sends the driver location data to the order allocation system.
1. Customer makes an order via customer’s application and our system validates the following information: (a) pick up location; (b) destination location; (c) discount voucher (if any); and (d) payment option
2. The order allocation system notifies a qualified driver partner who is nearby. A ‘qualified driver partner’ is one who is listed based on: (a) driver’s approval history and (b) driver’s order completion history.
3. The Driver then has the right to approve the order offered. If the top driver doesn't approve the order, steps 0-2 repeat until a driver accepts.
4. Order allocation system sends notification to the customer that the order is approved by the accepting driver and sends the driver’s details to the customer.
5. The driver then communicates with the customer.
Impact and next steps
Jaeger has driven huge business impact. Smarter allocation decisions generated over 1 million additional completed trips within weeks of our launch, with significant improvements in dispatch time, cancellation rates, driver utilisation, income and more. Jaeger has succeeded by creating a level playing field. Drivers are treated fairly and rewarded for good performance, their anonymity is preserved and irrelevant factors such as fleet type do not factor into allocation decisions. A meritocratic system for drivers is critical to deliver a better customer experience.
Another valuable aspect has proven to be the flexibility with which we can configure our objectives.
“Game changing, to say the least … Jaeger is now our internal platform that can bend allocation in every direction we need it to. That flexibility is critical.” — Nadiem Makarim, GO-JEK Founder and CEO
As an example, we have used Jaeger to deploy several new allocation models to combat fraud. The flexibility provided by Lasso and Meister made this possible in a short time period with almost no additional code.
This is only the beginning for Jaeger. The Allocation Data Science team will continue to develop new and existing models, as well as smarter approaches to combine them. Stay tuned for more updates.
Leave a 👏 if you liked what you read. Ping me with suggestions, feedback. Better yet, join us. GO-JEK has tons of incredibly cool problems to solve for and grab this chance to work in the perfect candy store 😉. Check out gojek.jobs for more.
Thanks to all the amazing people who contributed to this post: Jawad Md, Yaoyee Ng, Arfiadhi Nugratama, Seah Le Yi, Leow Guo Jun, Gavin Leeper, Hardian Lawi, Maneesh Mishra.
