How We Upgrade Kubernetes on GKE
Notes, insights, and tips to effortlessly upgrade GKE K8s clusters followed by our Engineering Platform team.

By Tasdik Rahman
If you’re running Kubernetes on GKE, chances are there’s already some form of upgrades for the Kubernetes clusters in place. Given that their release cycle is quarterly, you would have a minor version bump every quarter in the upstream. This is certainly a high velocity for version releases.
The focus of this blog is how one can attempt to keep up with this release cycle.
Although quite a few things are GKE specific, there are a lot of elements which apply to any kubernetes cluster in general, irrespective of it being self-hosted or managed.
Let’s quickly set context on what exactly a Kubernetes cluster is.
Components of a Kubernetes cluster
Any Kubernetes cluster would consist of master and worker nodes. These two sets of nodes are for different kind of workloads that run.
The master nodes in GKE are managed by Google Cloud itself. So, what does it entail?
Components like api-server, controller-manager, Etcd, scheduler, etc., needn’t be managed by you in this case. The operational burden just got smaller!
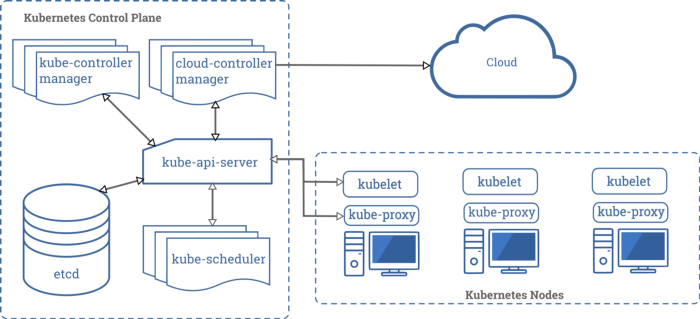
Here’s a quick summary of the above image:
Scheduler: Schedules your pods to nodes
Controller manager: Consists of a set of controllers used to control the existing state of the cluster and reconcile it with the state stored in Etcd
Api-server: The entry point to the cluster, and here’s where each component comes to interact with other components.
How we create a cluster
We use Terraform along with Gitops to manage the state of everything related to GCP. I’ve also heard good things about Pulumi, which could be a feasible choice. But, always remember:
Having the power of being able to declaratively configure the state of your infrastructure cannot be understated.
We have a bunch of cluster creation modules inside our private Terraform repository. This makes the creation of our GKE cluster so simple that it’s literally just a call to the module, along with some defaults and custom arguments. These custom arguments vary along with the cluster, or a git commit and push. The next thing one sees is the terraform plan, right in the comfort of the CI. If everything looks good, the following step would be to do a terraform apply in the same pipeline stage.
With a few contextual things about how we are managing the terraform state of the cluster, let’s move on to a few defaults which we’ve set.
By default, one should always choose regional clusters. The advantage of this is that the GKE will maintain replicas of the control plane across zones, which makes the control plane resilient to zonal failures. Since the api-server is the entry to all the communication and interaction, when this goes down, it’s nothing but losing control/access to the cluster. That said, the workload will continue to run unaffected (if they don’t depend on the api-server or k8s control plane.)
Components like Istio, Prometheus operator, or a good old Kubectl which depend on the api-server, may not function momentarily as the control-plane would be getting upgraded in case your cluster is not a regional cluster.
Although, in the case of regional clusters, I haven’t personally seen any service degradation/downtime/latency increase while the master upgrades itself.
Master upgrades come before upgrading anything
This is because the control plane needs to be upgraded first and then the rest of the worker nodes.
When the master nodes are being upgraded (you will not see the nodes in GKE, but it would be running somewhere as part of VMs/borg pods or whatever google is using as an abstraction), the workloads running on it like the controller-manager, scheduler, Etcd, the api-server are the components which are getting upgraded to the version of k8s you’re setting them to.
Once the master upgrades are done, we move to the worker node upgrades. The process of master node upgradation is very opaque in nature, as GKE manages the upgrade for you and not the cluster operator, which might not give you a lot of visibility on what exactly is happening. But nevertheless, if you just want to learn on what’s happening inside, you can try typhoon and try upgrading the control plane of the cluster brought up using that. I used to live upgrade the control plane of a self hosted k8s cluster. You can check out more about this here: DevOps Days 2018 India Talk.
GKE cluster master is upgraded. What next?
The next obvious thing after the GKE master node upgrade, is to upgrade the worker nodes. In the case of GKE, you would have node pools, which would in turn be having nodes being managed by the node pools.
Why different node pools, you ask?
One can use separate node pools to run different kinds of node pools, which can then be used to segregate the workloads which run on the nodes of that node pool. One node pool can be tainted to run only prometheus pods, and the prometheus deployment object can then tolerate that taint to get scheduled on that node.
What consists of the worker nodes?
This is the part of the compute infra, which is what you interact with if you are on GKE. These are node pools where your workloads will run.
The components which make up the worker nodes, (excluding your workload) would be:
- Kube-proxy
- Container-runtime (docker, for example)
- Kubelet
On a high level, kube-proxy is responsible for the translation of your service’s clusterIP to podIP, and nodePort.
Kubelet is the process, which actually listens to the api-server for incoming instructions to schedule/delete pods to the node in which it is running. This instruction is in turn translated to the api instruction set which the container runtime (e.g.: docker, podman) understands.
These 3 components are managed by GKE, and whenever the nodes are being upgraded, kube-proxy and kubelet get upgraded.
The container runtime need not receive and update while you upgrade. GKE has its own mechanism of changing the image versions of the control plane pods to do it.
We haven’t seen a downtime/service degradation happening due to these components getting upgraded on the cluster.
One interesting thing to note here is that, the worker nodes can run a few versions behind the version of the master nodes. These exact versions can be tested out on staging clusters, just to have more confidence while doing the production upgrade. I’ve made an observation that if master is on 1.13.x, the nodes run just fine even if they’re on 1.11.x. Only a 2 minor version skew is recommended.
What to check while upgrading to a certain version?
Since a major release cycle is quarterly for Kubernetes, one thing the operators have to compulsorily check is the release notes and the changelog for each version bump, as they usually entail quite a few api deletions and major changes.
What happens if the cluster is regional while upgrading it?
If the cluster is regional, the node upgrade happens zone by zone. You can control the number of nodes which can be upgraded at once using the surge configuration for the node pool. Turning off the autoscaling for the node pool is also recommended during the node upgrade upgrade.
If surge upgrade is enabled, a surge node with the upgraded version is created and it waits till the kubelet registers itself to the api-server, marking it ready after the kubelet reports the node as healthy back to the api-server. At this point, the api-server can direct the kubelet running on the surge node to schedule any workload pods.
In case of a regional cluster, another node from the same zone is picked up to be drained, after which the node is cordoned and its workload is rescheduled. At the end of this, the node gets deleted and removed from the nodepool.
Release channels
Setting a release channel is something which is highly recommended, we set it to stable for the production clusters, and the same for our integration clusters, with that being set, the nodes will always run the same version of kubernetes as the master nodes (excluding the small amount of time when the master is getting upgraded.)
There are 3 release channels, depending on how fast you want to keep up with the kubernetes versions released upstream:
- Rapid
- Regular (default)
- Stable
Setting maintenance windows will allow one to control when these upgrade operations are supposed to kick in. Once set, the cluster cannot be upgraded/downgraded manually. Hence, if one doesn’t really care about granular control, they cannot choose this option.
Since I haven’t personally downgraded a master version, I suggest you try this out on a staging cluster if you really need to. Although, if you look at the docs, downgrading master is not really recommended.
Downgrading a node pool version is not possible, but a new node pool can always be created with the said version of kubernetes and the older node pool can be deleted.
Networking gotchas while upgrading to a version 1.14.x or above
If you are running a version lesser than 1.14.x and don’t have the ip-masq-agent running and if your destination address range falls under the CIDRs 10.0.0.0/8, 172.16.0.0/12 or 192.168.0.0/16, the packets in the egress traffic will not be masqueraded, which means that the node IP will be seen in this case.
The default behaviour after 1.14.x (and on COS) is packets flowing from the pods stop getting NAT’d. This can cause disruption as you might not have whitelisted the pod address range.
One way is to add the ip-masq-agent and the config for the nonMasqueradeCIDRs list the destination CIDR’s like 10.0.0.0/8 (for example if this is where your destination component like postgres lies), in this case the packets will use the podIP as the source address when the destination (postgres) receives the traffic and not the nodeIP.
Can multiple node pools be upgraded at once?
No, you can’t. GKE doesn’t allow this.
Even when you’re upgrading one node pool, the node which gets upgraded and picked for upgraded is not something you’ll have control over.
Would there be a downtime for the services when we do an upgrade?
Let’s start with the master component. If you have a regional cluster, since the upgradation happens zone by zone, even if your service is making use of the k8s api-server to do something, it will not get affected. You could try replicating the same for the staging setup, assuming both have similar config.
How to prevent/minimise downtime for the services deployed?
For stateless applications, the simplest thing to do is to increase the replicas to reflect the number of zones in which your nodes are present. But, scheduling pods on each node across zone is not necessary. Kubernetes doesn’t handle this by default, but gives the primitives to handle this case.
If you want to distribute pods across zones, you can apply podantiaffinity in the deployment spec for your service, with the topologyKey set to http://failure-domain.beta.kubernetes.io/zone, for the scheduler to try scheduling it across zones. Here’s a more detailed blog on scheduling rules which you can specify.
Distribution across zones will make the service resilient to zonal failures.
The reason we increase the replicas to greater than 1 is because when the nodes get upgraded, the node gets drained and cordoned, and the pods get bumped out from that node.
In case the service which has only 1 replica scheduled on the node set for upgrade by GKE, while the scheduler tries finding itself a new node, there would be no other pod which is serving requests. In this case, it would cause a temporary downtime.
One thing to note here is that, if you’re using PodDisruptionBudget(PDB), and if the running replicas are the same as the minAvailable specified in the PDB rule, the upgrade will just not happen. This is because the node will not be able to drain the pod(s) as it respects the PDB budget. Hence the solutions are:
- To increase the pods such that the running pods are > minAvailable specified in the PDB
- To remove the PDB rule specified
For statefulSets, a small downtime might have to be taken while upgrading. This is because when the pods on which the stateful set is scheduled get bumped out, the pvc claim will again be made by another pod when it gets scheduled on the other node.
These steps of upgrade may seem mundane.
Agreed, they are mundane. But there’s nothing stopping anyone from having a tool do these things. As compared to eks-rolling-update, GKE is way easier, which makes fewer touch points and cases where things can go wrong:
- The pdb budget is the hurdle for the upgrade if you don’t pay attention
- Replicas are 1 or so for services
- Quite a few replicas would be in pending or crashloopbackoff
- Statefulsets are an exception and need hand holding
For most of the above, the initial step is to follow a fixed process (playbook) and run through it for each cluster during an upgrade. Even though the task is mundane, one would know which checks to follow and what to do to check the sanity of the cluster after the upgrade is done.
Setting replicas to 1 is just being plain naive. Let the deployment tool have defaults replicas of a minimum of (3 zones in 1 region assuming you have podantiaffinity and a best case effort gets logged by the scheduler).
For the pods in pending state:
- You are either trying to request CPU/memory which is not available in any node in the node pools, which means you’re not sizing your pods correctly
- Or there are a few deployments which are hogging resources
Either way, it’s a smell that you do not have enough visibility into your cluster. For statefulsets, you may not be able to prevent a downtime.
After all the upgrades are done, one can backfill the upgraded version numbers and other things back to the terraform config in the git repo.
Once you have repeated the steps above, you can start automating a few things.
What we have automated
We have automated the whole analysis of what pods are running in the cluster. We extract these information in an excel sheet:
- Replicas of the pods
- Age of the pod
- Status of the pods
- Which pods are in pending/crashloopbackoff
- Node cpu/memory utilisation
The same script handles inserting the team ownership details of the service, by querying our service registry and storing that info.
So all of the above details, at your tips, by just running the script in your command line and switching context to your clusters context.
As of now, the below operations are being done via the CLI:
- Upgrading the master nodes to a certain version
- Disabling surge upgrades/autoscaling the nodes
- Upgrading the node pool(s)
- Reenabling surge upgrades/autoscaling
- Setting maintenance window and release channel if already not set
The next step would be to automate the sequence in which these operations are done, and codify the learnings and edge cases to the tool.
Although this is a bit tedious, the laundry has to be done. There’s no running away from it. 🤷♂️
Until we reach a point where the whole/major chunk of this process is automated, our team will rotate people around doing cluster upgrades. One person gets added to the roster, while another who is already in the roster from the last week will drive the upgrade for the week, while giving context to the person who has just joined.
This helps in quick context sharing. The person who has just joined gets to upgrade the clusters by following the playbooks, thereby filling the gaps as we go forward.
The interesting part is that we always emerge out of the week with something improved, some automation implemented, or some docs added — All this while also allocating dev time for automation explicitly in the sprint.
Ending notes
GKE has a stable base which allows us to focus more on building the platform on top of it, rather than managing the underlying system. This improves the developer productivity by building out tooling on top of the primitives k8s gives you.
If you compare this to something like running your own k8s cluster on top of VMs, there is a massive overhead of managing/upgrading/replacing components/nodes of your self managed cluster which in itself requires dedicated folks to handhold the cluster at times.
So if you really have the liberty, a managed solution is the way to go. As someone who has managed prod self hosted k8s clusters, I’d say it’s definitely not easy, and if possible, it should be delegated so the focus could be on other problems.
References
- https://cloud.google.com/kubernetes-engine/docs/concepts/regional-clusters
- https://github.com/kubernetes/kubernetes/releases
- https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/
- https://cloud.google.com/kubernetes-engine/docs/concepts/release-channels
- https://cloud.google.com/container-optimized-os/docs
- https://cloud.google.com/kubernetes-engine/docs/how-to/ip-masquerade-agent
- https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#inter-pod-affinity-and-anti-affinity
- https://tasdikrahman.me/2020/05/06/specifying-scheduling-rules-for-pods-with-podaffinity-and-podantiaffinity-on-kubernetes/
- https://kubernetes.io/docs/concepts/workloads/pods/disruptions/
- https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
- https://kubernetes.io/docs/tasks/run-application/configure-pdb/
- https://cloud.google.com/kubernetes-engine/docs/how-to/upgrading-a-cluster#downgrading_limitations
Thanks to Krishna for the invaluable comments and feedback he provided for this blog.
