How we define speed, execution and scale
A story of how we replaced a high load backend service with zero downtime in two days.

By Deepesh Naini
The Definition of Scale
The GO-FOOD Engineering team is responsible for looking after the food business of GO-JEK. With more than 100+ million completed bookings a month, the scale at which this team operates is phenomenal. (We’re the largest single market food delivery app in the world, outside of China.)
To give you a sense of proportion, we have more than 200k merchants and more than 2 million items listed on the GO-FOOD platform. Single mothers are able to deliver quality home-cooked food making GO-FOOD a one of a kind phenomenon.
GO-FOOD is not only used as a transactional platform to order food, but also as a food discovery platform. Users browse through content to identify different categories of restaurants. e.g near-by restaurants, joints open for 24-Hours, etc… Customers can also search for restaurants, dishes and cuisines and GO-FOOD provides a wide range of options. Some of these are also discounted (using the GO-FOOD promotions platform) to provide competitive prices for our customers.
For GO-FOOD to work as an efficient transactional platform and provide users a sumptuous food discovery experience, it’s important that we maintain a heavy availability of our content systems. This way, users can get the best browsing and selection experience for their taste buds.
The existing content system of GO-FOOD is a Rails application having a persistent datastore, a cache, and uses ElasticSearch to power the search of content.
Over a period, we started observing that our content system was hitting its limits during peak hours. This lead to a degraded user experience sometimes and also caused a huge infrastructure burden.
The Definition of Speed in Execution
As described above, when the content system started hitting its limits, we were left with no choice but to term it as legacy. (Yes, that is how quickly we take a decision to start deprecating an existing service).
We had to reinvent it. But this is easier said than done — to replace a service which experiences a load of 100k RPM at peak is like changing the tyres of a racing car while it’s running at a high speed.
One of the core Engineering methodologies we follow as a team is breaking the problem down into very small components and solving for those components. This way we always have the larger picture, but also the smaller components make sure we don’t get overwhelmed by the problem.
In this case we identified the API which had the highest load and thereby had the maximum user impact and decided to pull out that API into newer, smaller components. The responsibility of this API is to power the search of restaurant outlets listed on GO-FOOD.
The snapshot of existing search architecture looks like this:
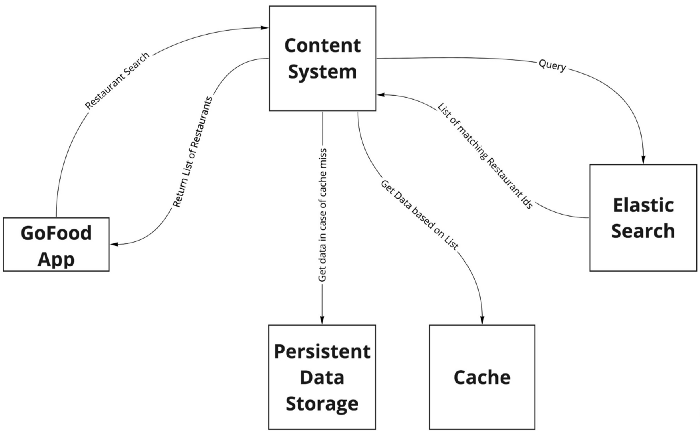
As we can see above, the content system is doing two things: it’s getting data from Elasticsearch and gathering metadata of the data from Elasticsearch by calling the datastore.
The first thing we decided was to break it down into two different systems to introduce domain responsibility. The new architecture looks like this:
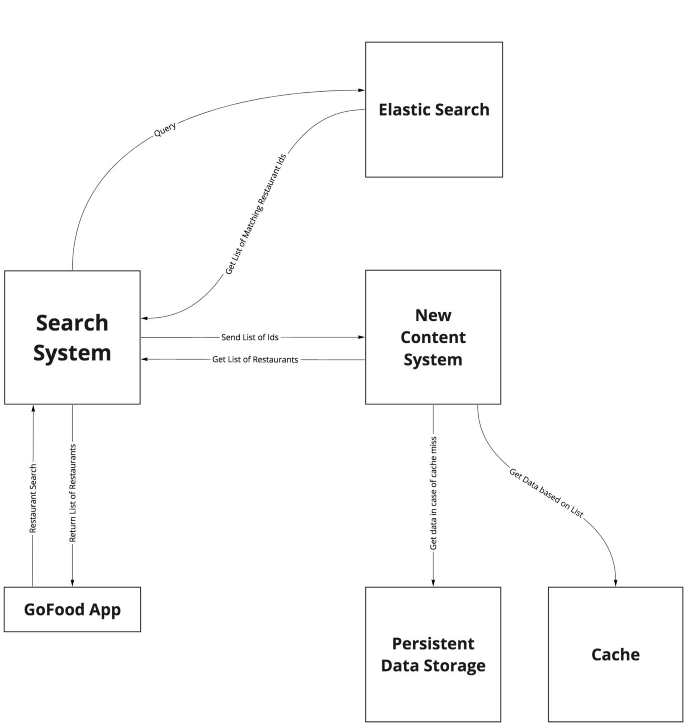
As we can see above, we introduced a new search system which will only query Elasticsearch and then talk to the new content system to add metadata to the list of restaurants. This way we were able to define separate responsibilities and SLAs of the two systems.
Now to the execution part. As discussed above, the the load on the existing system was growing at a crazy pace. Therefore, we also had to implement the new architecture quickly.
The new search system was something that the team was already working on, so our task was cut out. All we had to do was to replace an API endpoint that was serving traffic of more than 60k RPM, keeping in mind that if we goof up, people will not get their food (that’s pressure 😝).
So this is the timeline graph of what we did:
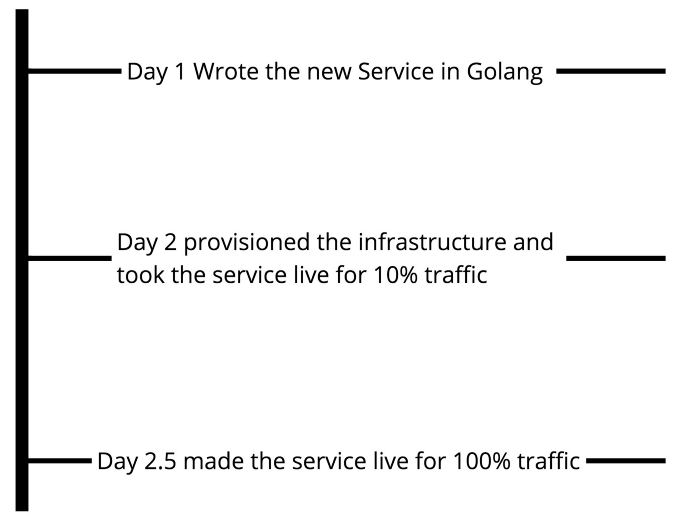
A fun fact about the above timeline is that we made the new content system live for 100% traffic at peak hours because the older system was again hitting limits.
Definition of Reliability and Performance
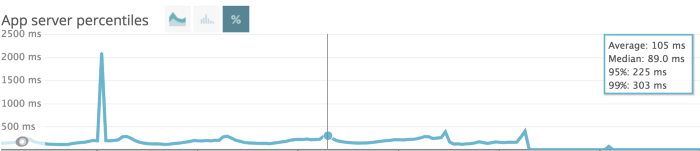
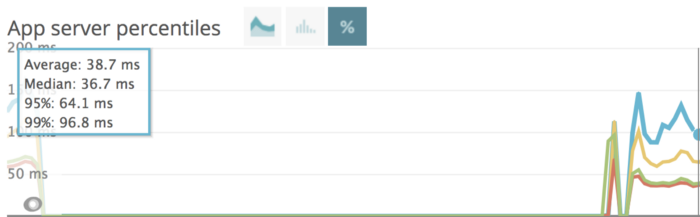
The response time of the new system we rolled out to the users was 68% faster. This meant increased availability and reliability, which ultimately lead to customer delight since everyone can now discover food faster.
Working at GO-JEK is exhilarating and you get to experiment, make mistakes and run million dollar products all alone. Grab this chance to be part of a journey filled with excitement, adventure and a crazy adrenaline rush. Head to gojek.jobs to check out for more.
