How we built ‘Global Search’ to improve discovery
The methods we use to help our customers find what they want in the GOJEK app.

By Aayush Sharda
Search has always been an interesting (and hard) problem to solve. This becomes even more of a challenge when you have a large and heterogeneous search space. As a Super App, GOJEK has myriad services to offer, which makes discovery a challenge for the user.
This is why Global Search is important.
Let me brief you about the problem that Global Search aims to solve:
There are two types of behaviours we broadly expect a user to exhibit:
1. Users have some idea what they want to order or search for.
2. Users don’t know what they want and are just browsing different products in the app.
Out of the two behaviours mentioned above, Global Search currently aims to solve the first one.
To give you an idea about the search space in GOJEK, users can search for:
- Location (GO-RIDE/GO-CAR)
- Food — Dishes/Restaurants/Cuisines (GO-FOOD)
- Events — Movies/Theatres (GO-TIX)
- E-commerce Products (GO-MART)
This post takes a dive into how we went about implementing a search system that could search across domains.
Implementation
We use Elasticsearch (ES) as the backbone of our search system.
The easiest approach to search would be searching across all the domains with the user query. However, this would put unnecessary load on our systems and also lead to inefficient ranking because Elasticsearch has to rank across domains (more data).
To tackle this issue, before a query is sent to Elasticsearch, it is augmented so as to find the right domain to search in.
The following steps are taken to augment the user query.
1. Intent Classification
One of the most important ingredients in Global Search is determining the user’s intention. If we are able to precisely determine which domain the user is referring to, we can efficiently search only that domain and serve relevant results to the user.
We use a supervised classification model (trained using fastText) on catalog data. This results in a theoretical precision of 95%. The model is trained to classify the intent into domains like location, restaurant, dish, e-commerce product, events etc.
Sample Response from Intent Service

Once the probability scores are determined, we search in the predicted domains and rank accordingly.
Although this model works pretty accurately for correct spellings, it is not that reliable when the user inputs a misspelt query.

To work around this problem we implemented spell correction for the query before the query is sent for intent classification.
2. Spell Correction
Why do we need spell correction if we already route the user requests to Elasticsearch, which can do a fuzzy match?
- One of the reasons to do spell correction is, as mentioned above, we do query classification into domains before we actually send the request to ES.
- Users tend to type incorrect spellings and if our query supports fuzziness, ES tries to find fuzzy matching documents and rank them. This method can cause a hit on the performance at scale.
Our aim is to build spell correction so accurate that we can completely remove fuzzy matching in ES.
First, we built a dictionary using our catalog data. As we went about correcting spellings (in the cases where they did not match with the dictionary), we encountered another issue.
Let’s assume a user is looking forratatouille, but he/she just writesratatoand expects the results to haveratatouille.In this case, the user might have a disappointing experience as spell correction would convertratatotopotatoand display the results.
So we took a pessimistic approach in correcting a spelling. If the individual words in the entered query match with the prefix of any of the words in our dictionary, we don’t perform spell correction. Otherwise, we try to correct the word with a max edit distance of 2. We use the SymSpell library for spell correction which outputs the best match for a query.
Some instances: Burgir Kimg → Burger King
Response from Intent Service after Spell Correction


Searching
Once the user query is augmented and classified, the request is forwarded to Elasticsearch. ES analyses the query and takes into account various ranking parameters to give satisfactory results.
Some examples of ranking parameters are:
- Matching across the right fields (movie name, theatre name, place of interest etc.)
- De-ranking unserviceable entities (e.g: closed restaurants/out of stock items, etc.)
- Attributing a higher score to the nearest located restaurant chain or theatre with searched dish or movie respectively.
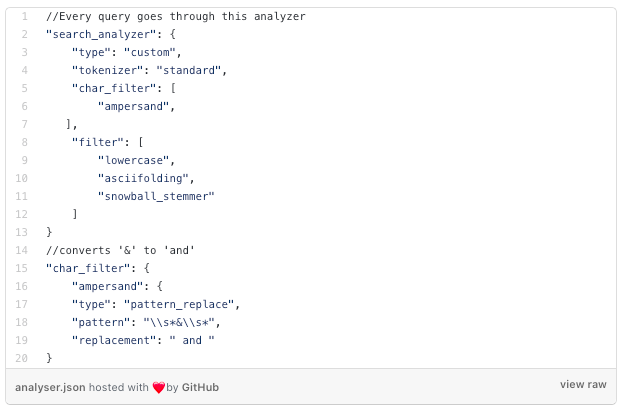
As mentioned earlier, ES performs query analysis before actual search is performed. The analyzer tokenises the query, performs stemming, and changes a few characters to match the documents in ES.
All the documents in our ES have an exhaustive list of fields that the document could be searched on. For example, a dish document also has some details about the restaurant to which the dish belongs to, in case the dish is searched with <dish_name> <restaurant_name>. This allows us to do multiple matches on different fields in a document, which promises better results than a simple field match. A dish query for multi-match looks like this:
Another improvement we made was for aggregating similar types of results: When a user searches for a restaurant chain like Starbucksthere might be multiple chains nearby, but instead of showing all those results we aggregate by brand and show the nearest restaurant.
Further Optimisations
At GOJEK, we never stop optimising the user experience. As we kept digging for methods to enable better and easier discovery, a thought kept coming up.
Is a keyword-based search always the most efficient way of discovering content?
Category-based queries
What if a user searches for a category of items instead of an item that is an exact match? Say a user searches for action movie, corresponding to which we don’t have any movie with text action. But, what we do have is a genre which matches the text. How do we address this problem?
We can try to convert these types of queries from a simple text match to a smart lookup query.
Example:
Query entered: “Action movies”
Query generated:

ES query: movie/_search?q=genre:ACTION
Conversational Queries
Another optimisation could be handling conversational queries using Named-Entity Recognition and then forming the query accordingly.
Example:
Query entered: Find best open restaurants near me
Query generated

In all the search scenarios, we default the results to prioritise entities which are nearby and operational at the time of search. This, in turn, covers the case of near meand open.
We are still in the process of planning out solutions for the cases mentioned above, watch this space for more developments.
We’re all about building intuitive, scalable solutions at GOJEK. That’s what happens when you’ve scaled 6600x in three years. That road led us to innovate solutions to problems we didn’t know could be solved. Which ties in nicely to something our CEO Nadiem Makarim once said: “If it’s not impossible, why do it?” Want to take a shot at the ‘impossible’? Head to gojek.jobs and come help us solve problems worth solving 🖖