How we built ‘BARITO’ to enhance logging
Building a logging infrastructure commensurate to GO-JEK’s scale

By Tara Baskara
Imagine coming home from a tiring day of work and your white-fenced house is suddenly pink. You’d have questions. Many of them. Did I arrive at the correct house? Who did this? When did this happen? For what? And why pink?!?! You’d look around frantically for clues. Did any of your neighbours see anything? You’d want answers. So imagine how glad you’d be once you realized you’ve installed security cameras in front of your house not long ago. All you have to do now is take a look at the log and get all the answers.
Now, what about complex applications and infrastructures systems? That’s thousands of white fences turning into every colour imaginable. How can you ensure security cams record everything? At this point you’d agree that logging is one of the most critical parts of any system. It gives us the visibility on how a system is doing and the ability to identify what went wrong when something goes haywire.
What about GO-JEK? Well, the absence of logging infrastructure brings us nothing but havoc. We’ve been through more than our fair and we critically need to improve in some areas:
Mean Time To Respond (MTTR)
At GO-JEK, we need to improve our MTTR. We have millions of bookings each day. If our MTTR is high, can you imagine the number of drivers missing potential orders? The number of people who may now be late for their appointments with each additional minute we take to solve an issue? Without proper logging, it’s akin to finding a needle in a haystack — because you have to check across thousands of machines in the faint hope that you might just stumble across the problem.
ELK scale
At GO-JEK’s scale, the conventional ELK stack (without sharding) we used did not scale for the quantity of logs. Each team has their own ELK cluster, but maintaining ELK clusters while everyone in the team has other pressing responsibilities is becoming a luxury we can’t afford. Another problem is that some of the teams grow too fast and the ELK became inadequate and overwhelming to support enormous amount of logs.
Access
Most times we can’t rely on our ELK cluster during a production issue. This is because the ELK was probably down, or maybe it didn’t give any insightful information. When these things happen, accessing the box directly is the only thing that you can do to see the logs. We don’t want that. We want to ensure only those with related responsibilities have direct access (SSH) to the box. And let’s not forget that our logs may contain sensitive information that we should really keep in-house.
Cost
Why don’t we use a third party application? When we talk of scale — 120 millions API call per second — it means only one thing: it will be very costly — the kind of capital that can better be spent elsewhere.
Recognising the scale and urgency of observability, we brainstormed and came up with Barito, an open source centralized logging infrastructure that produces fast, effective, and reliable logging infrastructure.
Why the name Barito you ask? Barito is a name of a river located in South Kalimantan, Indonesia. It is inspired by timber rafting — a log transportation method in which logs are tied together into rafts or pulled across a water body, or down a river.
Used correctly, we believe Barito will solve observability issues that GO-JEK has been struggling with.
Odyssey of The Logs
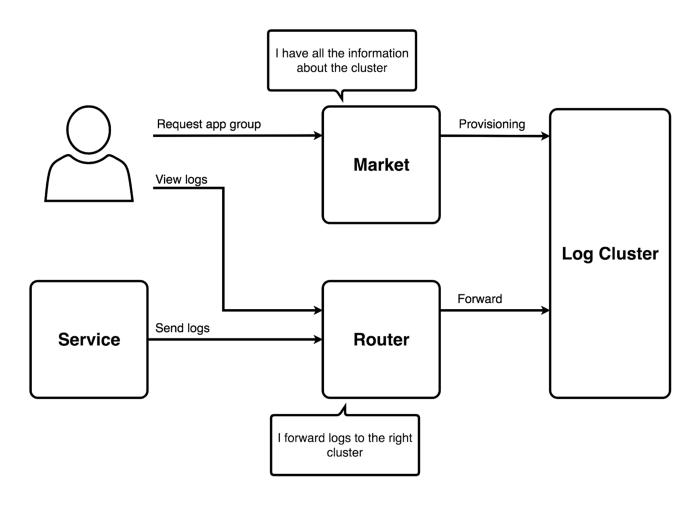
Barito Market
Users will interact with Barito through what we call Barito Market. In the market, users can request what application group they want to get Barito installed, then Barito will automatically provision a cluster for that application group. All of the infrastructure components are provisioned as LXC containers. We have another open source project that helps us provision these containers, called Pathfinder.
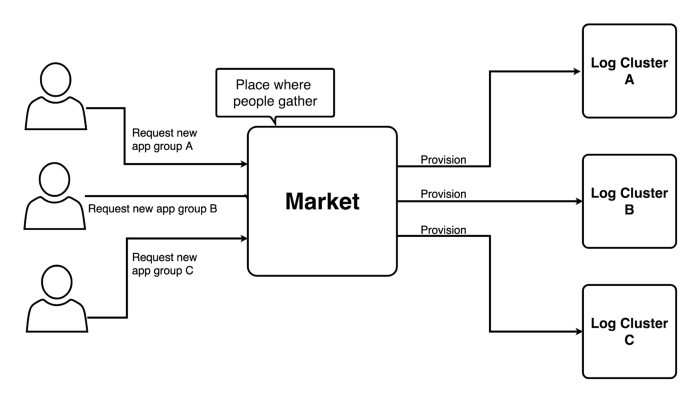
Log Cluster
Within a cluster, Barito has several components. The first one is Consul. We use Consul for service discovery inside a cluster. A Barito Router will query Consul to get the address of appropriate services. The next component is Producer whose main responsibility is to create a new topic on Kafka and send the logs to Kafka. We use Kafka as a message queue. In Barito, we have a component called Consumer that has several things to do: to subscribe logs from Kafka, create an ElasticSearch index and send the logs to the ElasticSearch. We use ElasticSearch as a log storage and search engine. The last one is Kibana — we use it to visualize the logs.
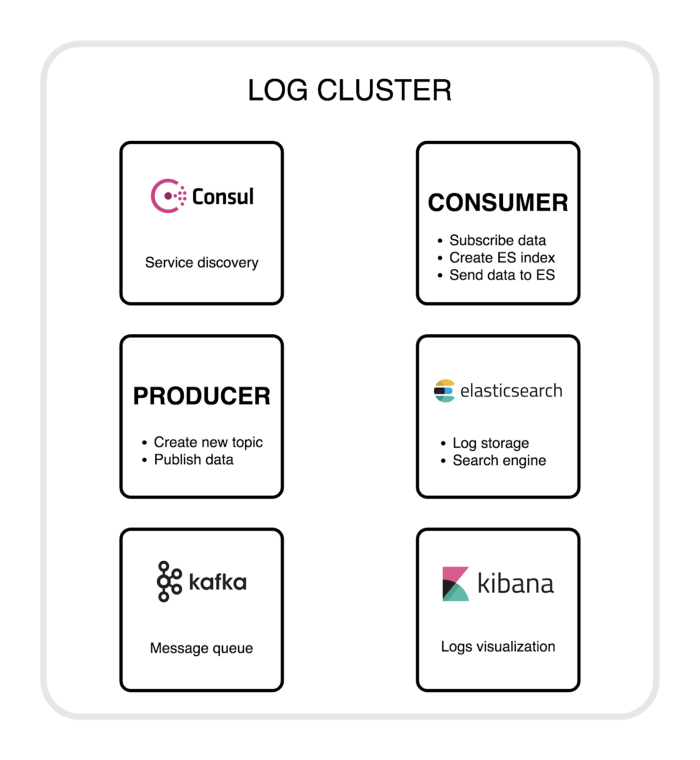
Barito Router
The journey of the logs begins when the agent on each service starts collecting the application logs. Before the logs sail away, the agent — we are customizing from fluentd — embed application secrets to the logs, then the logs flow to the component called Barito Router. This is the beating heart of Barito. Barito Router handles incoming logs and then forwards them to the appropriate cluster. This is done by communicating to Barito Market, to get the correct cluster, thanks to the application secrets. Barito Router also has the ability to authorize whether the users can see the logs.
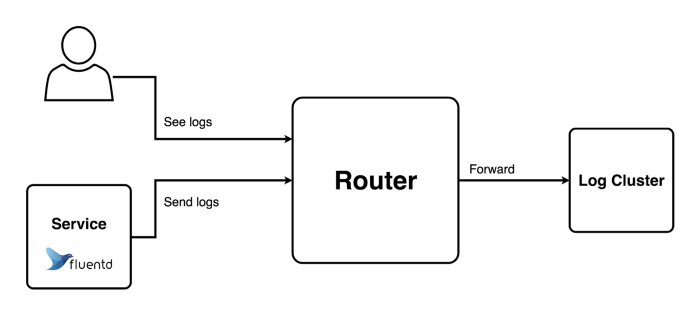
After flowing in the Barito river, the journey of the logs ends at the end of river we call Barito endpoint (we are using Kibana for now). From this endpoint users can see their logs that can help them find the root cause of the problem if something goes wrong. Is that the choir song I hear? Yes!! We finally have visibility on how our system and applications are doing!
Barito is a great example of efforts in GO-JEK to maximise efficiency of our engineering team. This enables relatively small numbers of engineers to handle ginormous scale and multitude of products. If you face the same problems like we did, you can also benefit from Barito because we Open Sourced it! Head to https://github.com/BaritoLog for more!


Sounds fun? Interesting? Would love to hear more? And… At the risk of sounding like a never ending record — PLEASE JOIN US! GRAB this chance to work with Southeast Asia’s fastest growing startup. We have just over 250 engineers doing more than a 100 million orders expanding to Singapore, Phillipines, Thailand and Malaysia. Check out gojek.jobs and here’s a chance to build beautiful products!