How to Use Declarative Pipelines in Kotlin
Working on long, memory-intensive operations is stressful. Fret not, declarative pipelines are your friend.

By Smital Desai
“How can we do this better?”
This is a question we continuously ask ourselves at GOJEK. We’re always looking to hack faster, better solutions for the tasks we do. In this post, we explain how to construct declarative pipelines designed to deal with problems in parts.
This pattern is not new, and if you want more information, check out this article by Martin Fowler.
Collection Pipeline
The collection pipeline is one of the most common, and pleasing, patterns in software. It’s something that’s present on…
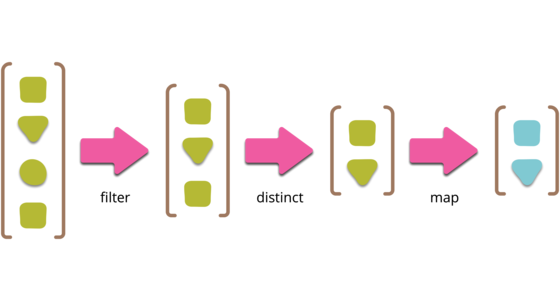
Collection pipelines are a programming pattern where you organise some computation as a sequence of operations which compose by taking a collection as output of one operation and feeding it into the next. (Common operations are filter, map, and reduce.) This pattern is common in functional programming, and also in object-oriented languages which have lambdas.
Now that you are up to speed, back to the story.
If you have done any web development, you must be familiar with access logs on a server. If not, here is a snapshot of an access log file:
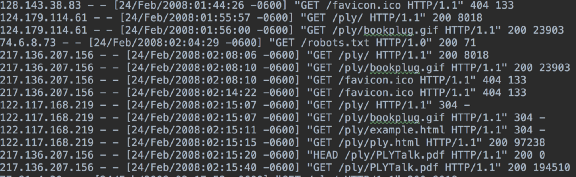
Each line in the file has the below format:
IP address : date: time: HTTP method : End point : Response : Bytes Transferred.
Let’s say our task is to find the total number of bytes transferred during all the hits to all end points. This is a problem where declarative pipelines can be applied. We must remember that these access log files can be really large. Reading an entire file in memory to read bytes and aggregate them can put too much burden on RAM.
In this case, we are using declarative pipelines in Kotlin to create memory-efficient, consumer-driven methods to process access log files.
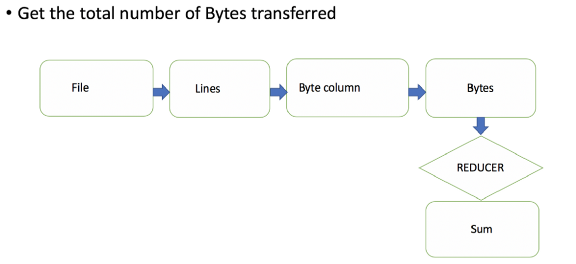
Let’s see how we can build a pipeline which aids memory-efficient processing of this file. I highly recommend listening to this episode of the Fragmented podcast to learn more about sequences, which form the foundation of the pipeline. I am also attaching Kaushik Gopal’s notes from this podcast episode which do a great job of explaining the concepts.



Here are the important takeaways:
1. Sequences are evaluated lazily
2. Sequences are not useful without a terminating operation. Examples include sum / min / max.
3. Intermediate operations on sequences won’t result in temporary lists being created [This is where the memory saving happens]
Based on these takeaways, a pipeline just needs two or more sequences to be chained together. To be more specific, we build a sequence from the first function and feed it as an input to the next function, resulting in an efficient data processing pipeline.
Let’s look at individual functions forming a stage in the pipeline:
getLines() : This function doesn’t read the entire file. It just returns a sequence using file.bufferedReader().lineSequence(). We use yield(line) to feed that line to the next stage.
getBytesColumn() : This function reads a single line at a time from getLines() function and gets only the last column [This is a sequence and not an intermediate list. So it’s cheap on memory].
getBytes(): If you look at the last three lines in the screenshot below, some log lines don’t have bytes at the last column. We skip those lines while getting bytes. [Still cheap on memory].

We are at the last stage of the pipeline and have the sequence of bytes. All that remains now is to compute the sum, ie the terminating operation.
This is the operation that drives even the first line that is read from the access log. Till this operation is invoked, not a single line is read from the log file.
The entire pipeline is consumer-driven.
No matter how big the access log file is, you now have a way to deal with it in a memory efficient way. I could have used Fluent API to do all of this in a chain operation. However, a declarative format better communicates what we are trying to achieve at each stage. It also makes it easier to debug, especially if there are many stages involved in the pipeline.
I hope you enjoyed this post. We will dive deeper into sequences and generators in Kotlin in later posts. Until then, happy coding!
You don’t scale like GOJEK has (we process over 3 million orders a day! 🤯) without being innovative. As we grow into new markets in Southeast Asia, we’re on the lookout for sharp minds. If you fit the bill, visit gojek.jobs and help us do better.
