How to Unlock the Full Potential of Kafka Producers
Explaining Producer configs that improve performance in Kafka pipelines.

By Mohak Puri
At Gojek, we use Kafka to solve problems at scale. So, every bit of optimisation is important to us. Producers in Kafka come with many configurations, and knowing when to use them can improve the performance of your Kafka pipeline.
In this post, let’s analyse some of these configurations that you might not be using, but should.
Producer Configurations
1. Acks
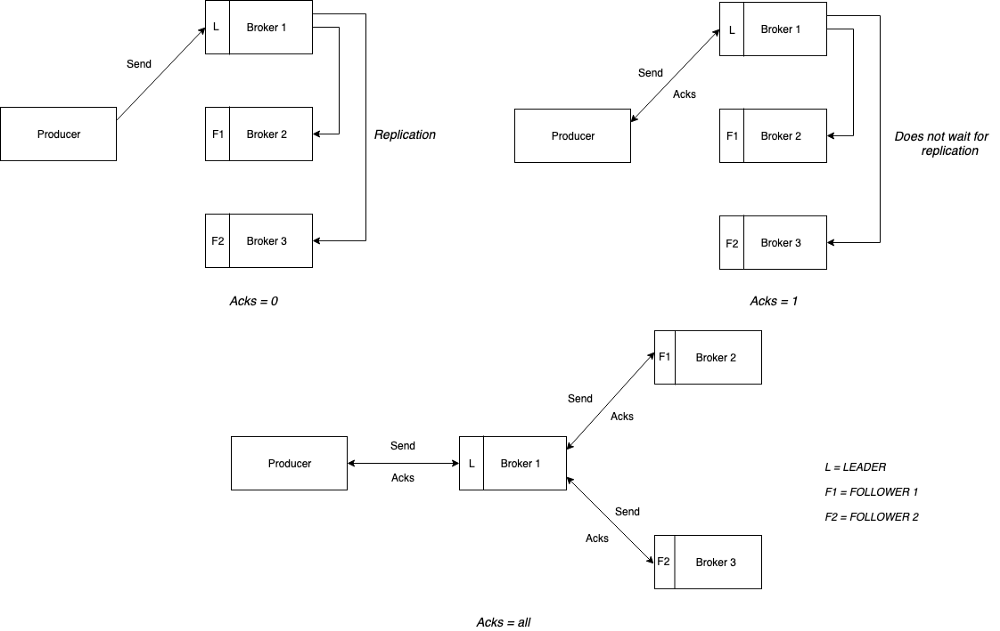
- acks = 0 → The producer does not wait for any kind of acknowledgment. In this case, no guarantee can be made that the record was received by the broker.
retriesconfig does not take effect as there is no way to know if any failure occurred. - acks = 1 → The broker gives an acknowledgment once the record is written by it. However, it does not wait for the replication to finish. This means that in case the leader goes down before the replication is complete, the record is lost.
- acks = all or -1 → The broker gives an acknowledgment once the record is written by it and also synced in all the followers. This mode, when used in conjunction with config
min.insync.replicasoffers high durability. It defines the minimum number of replicas that must acknowledge a write for the write to be considered successful.
Consider the following case
Number of brokers = 3
Replication factor = 3
min.insync.replicas = 2 (This includes the leader)
acks = all
You can tolerate only one broker going down. In case more than one broker goes down then either NotEnoughReplicas or NotEnoughReplicasAfterAppend exception is thrown- Retries and Timeouts → In case the producer does not receive any acknowledgment, it waits for a time equal to
request.timeout.msand the request is retried. However, one issue during retry is that the order of request may change.
Key: Req, Message: 1 -> Done
Key: Req, Message: 2 -> Done
Key: Req, Message: 3 -> Failed
Key: Req, Message: 4 -> Done
Key: Req, Message: 5-> Done
(Retry request)Key: Req, Message: 3-> Done
Expected Order -> 1,2,3,4,5
Actual Order -> 1,2,4,5,3If you don’t care about the ordering of your messages then you are good to go. Otherwise, this issue can be resolved by setting a correct value for max.in.flight.requests.per.connection. This config determines the max number of unacknowledged request that can be sent on a connection before blocking. Setting this value to 1 means that only request will be sent at a time thus preserving ordering.

Adding acks to your producer configs can increase latency, since the producer needs to wait for the acknowledgment
2. Idempotency
Consider the following situation:
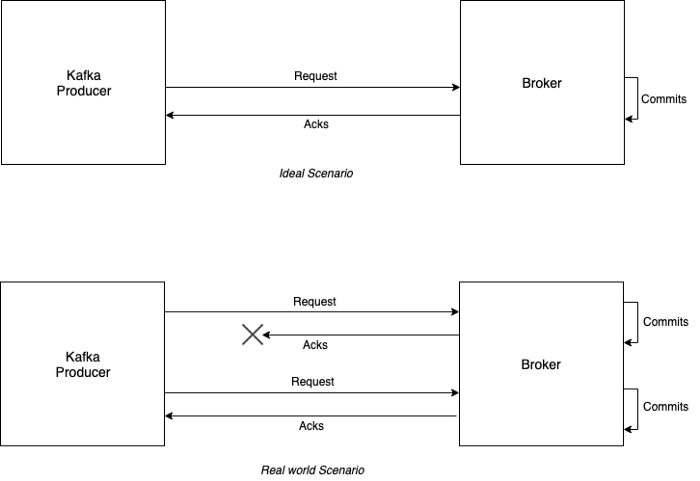
In a real-world scenario, there is a good chance that your Kafka producer does not receive an acknowledgment (maybe due to network failure) and retries the request even though the data was committed on the broker. In such a case, there is a duplication of data. To tackle this situation, you need to make your producer idempotent.
Making your producers idempotent is as simple as setting the config enable.idempotence = true.
But how does this work?
Each producer gets assigned a Producer Id (PID) and it includes its PID every time it sends messages to the broker. Also, each message gets an increasing sequence number(SqNo). There is another sequence for each topic partition on the broker side. The broker keeps track of the largest PID-SqNo combination on a per partition basis. When a lower sequence number is received, it is discarded.
Idempotency comes with the following configurations:
acks = allretries = Integer.MAXmax.in.flight.requests.per.connection = 1 (0.11 >= Kafka < 1.1) OR 5 (Kafka >= 1.1)
You cannot have conflicting values ofacksandmax.in.flight.requests.per.connectionwhen using idempotency.
For example — You cannot set idempotency = true and acks = none for your producer since idempotenct expects acks = all
3. Batching
By default, Kafka tries to send records as soon as possible. However, this behavior can be changed by using two properties linger.ms and batch.size. The first property defines how long the producer waits before sending the records to Kafka, whereas the second one defines the maximum size of a batch that can be sent at a time. So, instead of sending a record as soon as possible, the producer will wait for linger.ms before sending the record.
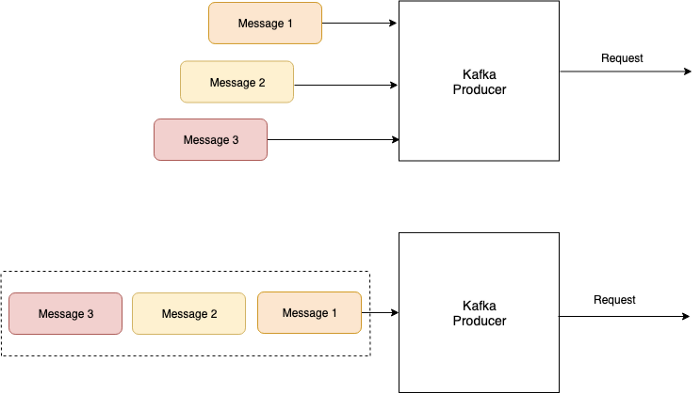
Ifbatch.sizeis exceeded beforelinger.msthe producer will send the batch of records.
4. Compression
Before getting into compression, let’s discuss why you should consider it:
- One of the reasons is the reduced disk footprint.
- Not only will you be saving a significant amount of disk space, but latency will also decrease due to the smaller size of the messages.
Note: Compression leads to increased CPU cycles.
By default, messages are sent uncompressed. The parameter compression.type can be set to snappy, gzip, or lz4 to compress data before sending it to the brokers.
- Snappy compression was invented by Google and aims for very high speed and reasonable compression. It does not aim for maximum compression so the decrease in size might not be that significant. If you are looking for a fast compression algorithm, Snappy might work for you.
- Gzip compression will typically use more CPU and time but results in better compression ratios, so it recommended in cases where network bandwidth is more restricted.
It is highly recommended that you properly test these configs for your use case before using them in production environment.
Stéphane Maarekhas some really cool blogs/courses on Kafka which I would highly recommend :)
That’s about it! Thank you for reading, and I hope you enjoyed the article.
You can also follow me on Medium and Github. 🙂
Want our latest posts beamed straight to your inbox? Sign up for our newsletter!

