How to build Resilience in large scale Distributed Systems
Lessons learnt in building Resilience for large scale Distributed Applications

By Rajeev Bharshetty
This is Part 2 of a series on ‘Resiliency in Distributed systems’. If you have not read Part 1 of this blog series, highly recommend doing so by clicking here. Part 1 gives you a precursor and much needed context.
In this article, we will continue to discuss more patterns in bringing resiliency/stability in complex distributed systems.
Pattern[6] = Rate-limiting and Throttling
Rate-limiting/Throttling is only processing a certain number of requests in a fixed period of time and gracefully handling others
Rate-limiting can be applied to requests which are coming into your system (rate-limiting access to your APIs), or for the requests which are leaving your system (when making calls to external party services)
We use a Leaky Bucket algorithm at most places for rate-limiting/throttling requests.
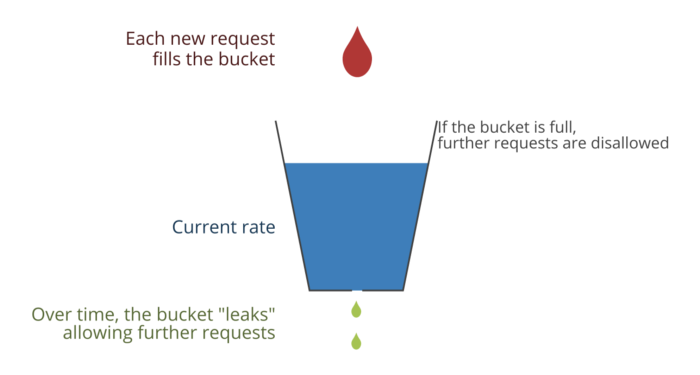
Rate-limiting/Throttling can help protect systems in many scenarios:
1) Scripted attacks to your system
2) Sudden bursts in traffic
3) Protecting your integration with third party external services
Usually when a rate-limit kicks in, requests exceeding a threshold are dropped and sent back a standard 429 (Too many requests) response.
At GO-JEK, this pattern is used at multiple places and for varied reasons. Let’s discuss few:
Rate-limiting incoming requests
Case 1: OTP Login
We rate-limit requests to OTP (One time password) login from our mobile application. This rate-limit is per-user.
Users only get a fixed number of chances to log in for a fixed time window.
This helps prevent a scripted attacker/a malicious user retrying logins more than necessary.
This approach helps in the following ways:
- Prevent attackers from brute-forcing the login system by continuously retrying logins with different OTP’s
- Saves cost on SMS/call
Case 2: Promotions Platform
The Promotions Platform is responsible for processing promotional codes which are sent to GO-JEK users for various services.
At times, especially during promotions, we see a sudden burst in traffic. This sudden burst could crash services or prevent them from performing at their peak.
Rate-limiting requests, dropping excess ones or queuing them, can help promotions service as well as the dependent services to work normally. Thus protecting critical flows from failure.
Throttling outgoing requests
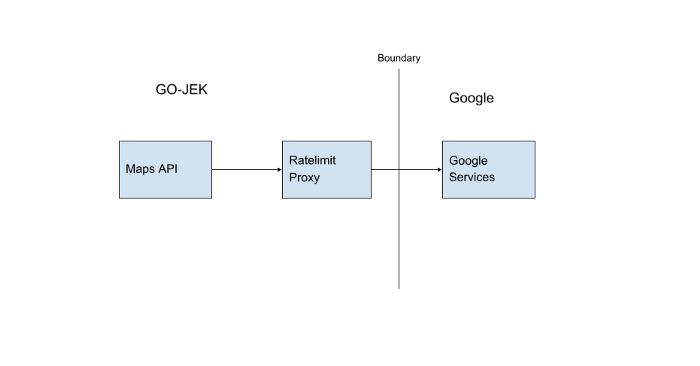
Case 1: Maps Service
We use Google maps API for estimating the distance between rider and driver, estimating price, mapping a route between driver and rider etc.
We have a certain limit(Quota) on the number of requests (QPS —Queries per second) which are allowed to be made to Google in a fixed period of time. It is important we adhere to this limit to not get blocked by Google.
At GO-JEK, all the calls to Google go through a proxy service which makes sure we do not exceed the limit set by throttling requests that fall outside the limit.
It looks something like this:
Pattern[7] = Bulk-heading
Bulk-heading is isolating elements into pools so failure of one does not affect another
The name `Bulkhead` comes from the sectioned partitions in a ship, wherein, if a partition is damaged/compromised, only the damaged region fills with water and prevents the whole ship from sinking.
Similarly, you can prevent failure in one part of your distributed system from affecting and bringing down other parts.
The Bulkhead pattern can be applied at multiple ways in a system.
Case 1: Physical redundancies
Bulk-heading here is about keeping components of the system physically separated. This could mean running on separate hardware or different VM’s etc.
For example: At GO-JEK, We have driver and customer API’s physically separated on different clusters.
Bulk-heading done like this prevents failures in customer APIs causing problems on the driver side.
Case 2: Categorized Resource Allocation (CRA)
CRA is about splitting resources of a system into various buckets, instead of a common pool
At GO-JEK, we limit the number of outgoing HTTP connections which a server can make. The number of allowed connections is considered a connection pool.
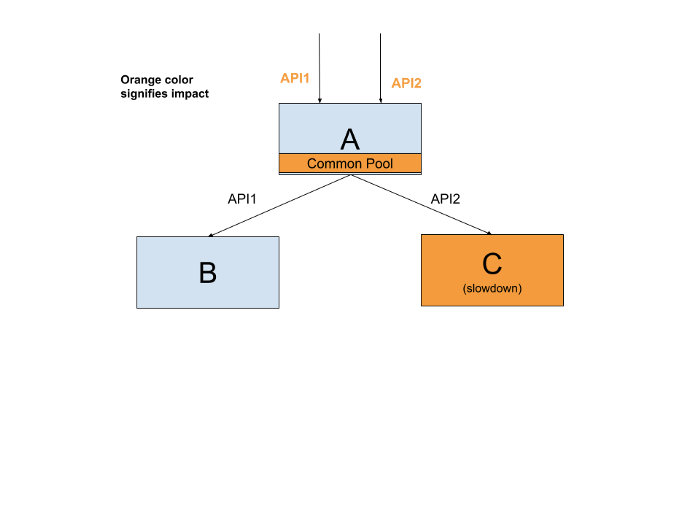
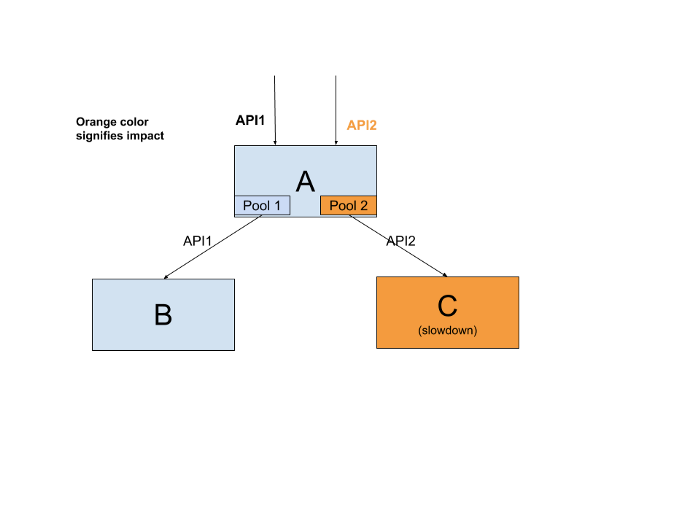
Consider ‘A’ supports 2 API’s API1 and API2. API1 requires a request to ‘B’ and API2 requires a request to ‘C’. Consider having a common connection pool, problems in ‘C’ can cause request handling threads to be blocked on ‘A’. It utilizes all the resources of ‘A’, preventing requests meant for ‘B’ to be served/fulfilled. This means failures on API1 causes API2 to also fail. Creating separate connection pools to ‘B’ and ‘C’ can help prevent this. This is an example of categorised resource allocation:
Hystrix provides max concurrent requests setting per backend. If we have 25 request handling threads, we can limit 10 connections to ‘C’, which means at most 10 connections can hang when ‘C’ has a slowdown/failure. The other 15 can still be used to process requests for ‘B’. Check out this library:
 gojek
gojek
Bulk-heading thus provides failure isolation across your services, hence building resiliency.
Pattern[8] = Queuing
Queuing is buffering of messages in a queue for later dispatch to consumers, allowing producers to be decoupled from consumers.
Queuing brings in resiliency by:
- Decoupling Producers from consumers
- Smoothen out bursts of traffic by buffering
- Retries on intermittent failures
A typical queuing architecture looks like this:
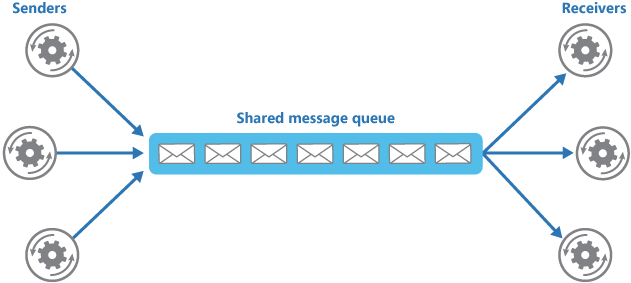
At GO-JEK, we heavily use queuing to process asynchronous flows for our customers. Queuing can introduce latencies and so using it in a synchronous context should be carefully designed.
Case 1: Terminating Bookings
This service plays an important role in terminating all bookings at GO-JEK. There are a bunch of activities that needs to be completed before a booking is considered completed.
If a customer has booked a ride using GO-PAY, you need to:
- Debit customer balance
- Credit driver balance
- Update a service to release driver back to the free pool
- Mark the state of booking as completed
- Record the history of this transaction
- Reward driver with points
The more tasks you have to do, the more the failure modes. AND the more ways in which a service or an API call can fail. All of the above tasks can be done asynchronously without asking customers or drivers to wait. Without a queuing solution. If there is a failure in some system, both customers and drivers are stuck waiting for their transactions to complete. Queuing can also help retry requests once the failure has been rectified.
Queuing decouples booking flow to provide much more resilience in the whole architecture.
Case 2: SMS Notifications
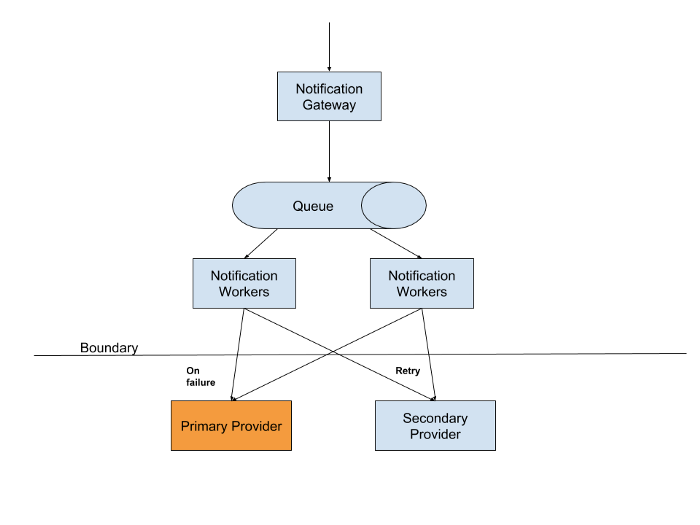
We heavily use SMS for communicating with our customers/drivers/merchants. To make our systems resilient against SMS provider failures, we integrate with multiple SMS providers.
To decouple ourselves from failures on our SMS providers, we use queuing to deliver messages. Messages in the queue are removed when they are successfully sent through our SMS provider. We retry SMS with a different provider when our primary provider fails to meet a certain SLA for delivering a SMS.
Pattern[9] = Monitoring and alerting
Monitoring is measuring some metric over a period of time.
Alerting is sending a notification when some metric violates its threshold.
Monitoring and alerting can help you measure the current state/health of your system so you are alerted of the faults in your system as quickly as possible. This can prevent faults turning into failures.
Resiliency does not mean your systems will never fail. Instead, it means that it recovers quickly and gracefully from faults.
For example: Without monitoring/alerting you might not be able to detect a memory leak in your production application before it crashes.
At GO-JEK, we collect various kinds of metrics which includes system metrics, app metrics, business metrics etc. Also, alerts with thresholds are set for various kinds of metrics. So when a fault happens, we know beforehand and take corrective measures.
Monitoring with alerting can help in 2 ways:
- It notifies potential faults in the system, helping you recover from it before it causes failure in all systems (Uptime)(Proactive)
- It can help diagnose the issue and pinpoint the root cause to help recover your systems from failure(MTTR — Mean time to recovery)(Active)
Pattern[10] = Canary releases
Releasing a new feature/version of a software to only a certain set of users in order to reduce the risk of failures
More about canary releases here
Canary releases at GO-JEK is being done at various places:
Case 1: Back-end Deployments
Every deployment on back-end involving critical changes goes through a canary release. The new version of the software is deployed only to a single node or to a selected set of nodes along-side stable running version.
After the release, the canary is monitored for status codes, latencies etc. Only after monitoring the system for a particular period of time, the new version of the software is released to all users.
Case 2: Mobile releases
Even new app roll-outs go through this phase of releasing to a small set of users. Continuous monitoring for usage, crashes and bugs follows this release. Only when the team is confident about the new release do they go ahead with a full-blown release.
Canary releases help you avoid risk of failures on new version/feature releases, in-turn helping resiliency of systems.
Conclusion
All the above patterns can help us maintain stability across our systems.
If there is one thing you take home from these patterns, it should be …
The more coupled your services are, the more they are together in failures
To repeat: Failures will happen, we only need to design systems to be resilient against these failures.
I talk a lot about Distributed systems on my Twitter and and Open source code at Github. Ping me, if you find this useful.
Goes without saying: We’re hiring! Developers, here’s your chance to work with SE Asia’s fastest growing unicorn. Check out gojek.jobs for more.