How the Gojek Butler serves a Gourmet meal to our users
The story of Butler: our in-house solution for personalised search results within GoFood

By Maulik Soneji
From large restaurants to small roadside eateries, GoFood is responsible for delivering meals from more than 300K merchants quickly and efficiently. With so much choice, it is important to provide users a search experience where they can find their favourite merchants easily.
The idea behind Butler was to improve this search experience by taking into account customer preferences. With a better search experience, we wanted to improve our Click Through Rate (percentage of merchant page visits per search session) and Booking Conversion Rate (percentage of search sessions that result in a booking).
In this blog, we will cover the current architecture for GoFood search, how we personalised the search experience through Butler, and how we trained our model by collecting feedback from search results.
The architecture of GoFood Search
GoFood Search uses Elasticsearch for search and ranking of merchants. For each search request, we first query Elasticsearch, which ranks merchants according to the search query. The search query takes into account two things for the ranking: whether the merchant is open, and the distance from the user.
After fetching restaurant details from Elasticsearch, we query another service called Gourmet for getting merchant details. The returned response is a combination of Elasticsearch and Gourmet responses.
Coming up with a Search Personalisation Architecture
When tasked with personalising search results, we had to first analyse how to: a) fetch customer preference information and b) create a learning model.
This is how we did it:
a. Fetching Customer Preference Information
We have an internal batch processing product named Tagstore which populates customer data with information about their order and browsing history. It also takes into account the cuisine and merchant information for their orders in the last one month and six months.
This data is updated on a daily basis and fetching it required just a lookup to retrieve customer information.
b. Creating a learning model
While analysing our options for using a model to rank the restaurants, we found a plugin called LearnToRank (LTR), which allowed us to use a learning model against our searches.
A relevance by query dataset that summarises the judgment a user made on each search listing was prepared and a learning model was trained using Ranklib.
The judgment is basically weighed based on whether the user clicked the restaurant tile (weight =1), user made a booking (weight =2) or no action was taken by the user (weight =0).
Putting Butler to the test
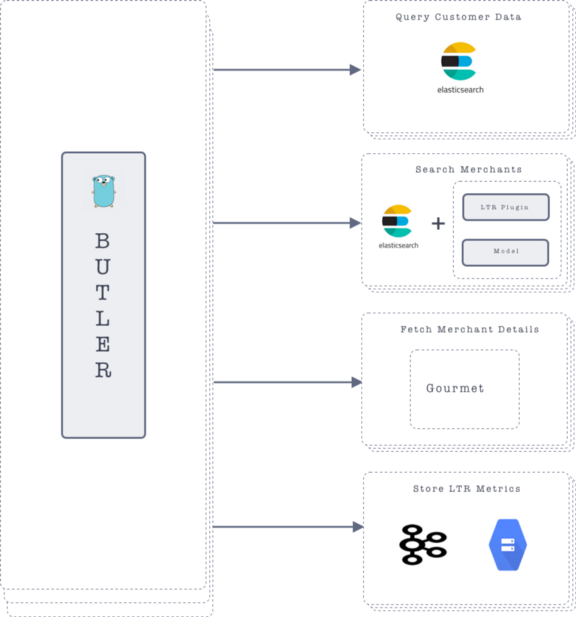
Butler is a Golang service that serves as the endpoint for serving the search results from Elasticsearch. With every search request, we take into account the customer ID, customer location and the tile that the user has selected (example: nearby restaurants, restaurants which are open 24X7, best selling merchants etc).
For personalising the Elasticsearch response, we first fetch the customer details from the Tagstore that we discussed previously. After this, we pass in the customer preference information as a parameter to the model in the search query.
The model is used to re-score the Elasticsearch documents and we get a personalised response to a user’s search request. When rolling out personalised search, we made sure that we roll it out only to a certain percentage of the search traffic.
We created a rollout endpoint for each tile, so that we can first test the personalised results for a particular tile and compare the results. Since user trends vary across different tiles, rolling it out to different tiles and measuring the non-personalised vs personalised results made more sense.
We also created a live dashboard that shows the booking conversion and search click conversion. Using this, we were able to track how our personalised search performed against traditional search.
The results speak for themselves. As of writing, we saw the booking conversion ratio and click-through conversion rate increase 23% and 14% respectively. We will go deeper into learning models and the impact of search personalisation in upcoming posts.
Creating a feedback cycle
As part of our initial efforts, we were just tracking the Service Level Agreements (SLAs), booking and search click conversions. We did not take into account the scores that LTR provides to each restaurant by considering customer profile information.
We realised that this was vital information to train the current model.
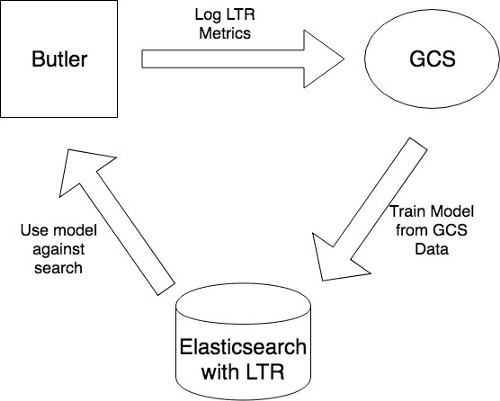
In order to collect these metrics, we enabled LTR metric logging in the search query. After collecting the LTR metrics, we push these metrics along with the customer information to Kafka
From Kafka, we have a cold storage pipeline setup which pushes the Kafka data to Google Cloud Storage (GCS). The search data, as well the positions at which the user clicked and made bookings from, is pushed to GCS via Kafka as well. These data sources are used to create the judgment dataset that can act as the training data for the next iteration of the LTR model.
What next, you ask?
As an improvement to the search personalisation experience, we want to improve the model’s performance by taking into account more information about customer-merchant interaction.
For example, we want to take into account the primary cuisine information of the merchant so that when users search for the cuisine we can prioritise the merchant.
Also, from a technical point of view, we want to run multiple learning models at the same time and compare the results from the various experiments. Watch this space for more information on our experiments with personalised search results.
Solving problems like search personalisation is part of our daily bread and butter at Gojek, and we could always use more help. If you have an appetite for an interesting challenge, visit gojek.jobs and help us build cool things! 😎