How I met my Gojek driver - without a single call
The story of how the Gojek Data Science team used machine learning to automate the naming of pickup points at scale

By Divya Choudhary
At Gojek, we work hard to provide the best experience to our customers; be it making a smooth payment or ordering the best Martabak.
Around 100 GB of data from over 18 products flows through our data systems each hour. Gojek's Data Science team is immensely privileged to be able to analyse it all and extract meaningful patterns. The aim is to understand all customers, drivers, and merchants on our platform and provide them a great user experience.
This blog post explains Language Modelling (LM), the second step of how we were able to ease friction for pickups between a driver and a customer. The first step was clustering, which was covered in a previous post by my colleague.
The pickup experience dilemma
One of the important problems that was hampering experience on the GO-RIDE and GO-CAR products was the lack of precise location sharing between customers and drivers.
Customers’ perspective: We’ve all been in situations where a huge mall has multiple exits. You have to keep running from one exit to the other, trying to figure out where your cab driver is. Especially in Jakarta’s huge malls. 😂
Drivers’ perspective: The location indicated is correct, but the customer is elsewhere. Or, the driver’s unfamiliarity with the mall makes it a cumbersome experience to understand where the customer is.
Enter the Data Science Team. Once this problem became pronounced, we had to act. That’s when we built ‘Frequented Place of Interest’ a.k.a FPOI.
FPOI to the rescue
With FPOI, we find pre-defined pickup points for each Place Of Interest (POI). These pickup points are then displayed to the customer while they are on the ride/car booking page.
Where is language modelling in all of this?
The solution to the problem was a machine learning algorithm involving two crucial steps:
- Clustering to get gates of a POI: Pickup points were clustered to find the points around or within a POI that customers prefer to be picked up from. Please refer to our blog on this first step of the algorithm here.
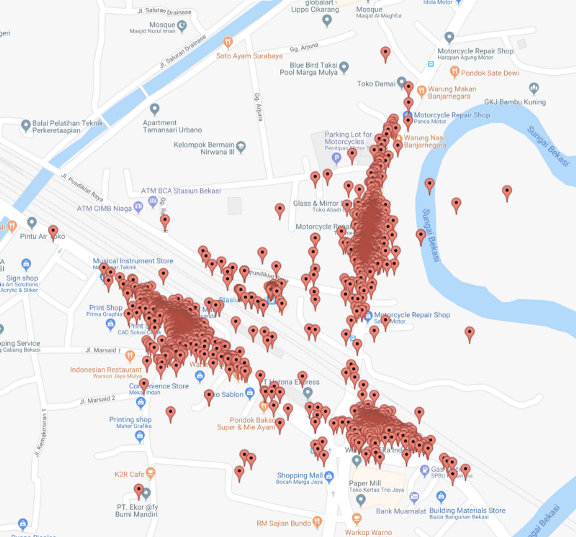
2. Language model to name the gates: The popular pickup cluster centres in/around the POI need to be named. This way customers have a drop-down menu to choose from. Now, customers can choose the pickup gates they want to be picked up from based on their convenience and proximity to the gate.
What is a language model?
Language Model (LM) is a way to determine how likely a certain sentence is in the language. “You are reading my LM write up now”, is more likely to be said than, “Now you are my LM reading write up”, even though both sentences contain correct English words. Similarly, the sentence “I had an ice-cream with a…” is more likely to end with “spoon”, than with “banana”. LM helps impart this understanding of a language to machines.
What’s the need?
Computers are programmed to understand specific instructions. The languages we speak are much more complex than that; because you can say one thing in multiple ways. “Where do I go for a party tonight?” and “Which are the best clubbing places near me?” — are examples of language variability.
As if this was not complex enough, sometimes you say something that can have several meanings, like “Look at the dog with one eye.” Forget machines, this has boggled even human geniuses on whether “the dog is one-eyed” or “one eye should be closed while looking at it” !! This is called language ambiguity.
Thanks to facial expressions, voice modulations or personal experiences, a human being usually understands the correct meaning in the context of the conversation. A computer… not so much! Making it learn by passing these complete parameters of intent and context to the computer along with the text of the conversation is important and language models help us achieve this.
“Computers are incredibly fast, accurate and stupid; humans are incredibly slow, inaccurate and brilliant; together they are powerful beyond imagination.”
— Albert Einstein.
Types of Language Models
Language models are broadly of two types:
Statistical LM: A language model is formalised as a probability distribution over a sequence of strings (words). Traditional methods usually involve making an n-th order Markov assumption and estimating n-gram probabilities via counting and subsequent smoothing.
Neural LM: The use of neural networks in the development of language models has become very popular these days. This is often called Neural Network based Language Models, or NNLM for short.
At Gojek, we used a statistical language model to generate names for all pickup gates around a POI as generated by the clustering step.
How we used LM to name gates of a POI
The pickup gates that came out of the clustering exercise for each POI are unlikely to be distinctive from the POI itself in terms of spatial location (latitude and longitude). In many cases, they are literally the gates of the POI! Hence, it did not make sense to use Google’s reverse geocoding API to get the names of these close gate coordinates, as the names of gates would not be distinct. We had to use another way to generate distinct names for these gates. Automatically — n-gram language model on the booking related text data was our solution.
N-gram language model
An n-gram language model is a probabilistic model of a word sequence. In simple terms, it’s a model that lets you find the most probable n-gram given a (n-1) gram.
An n-gram is a contiguous sequence of n-items from a given sequence of text. A sequence of one item, say a word, is called a unigram. A sequence of two words is called a bigram, and so on.

Markov Assumption
From the definition of LM it is clear that some words are more probable to follow a word in certain contexts. Ideally, it would be best to have all the words up to the word that we are trying to predict in the n-gram. This is called history of a n-gram language model. It would be inefficient to know the entire history, as we can encounter infinitely many sequences of sentences, or the history we know would have never occurred before. Therefore, we needed to approximate the history by only a few words.
As per Markov Assumption, a Bigram language model assumes that we can predict the probability of the future word by only looking at the last word encountered. Similarly, a Trigram language model (by looking at the last two words in the past, history =2), and an N-gram language model (looking N-1 words in the past, history = N-1). So, in general the conditional probability of the next word in a sequence would be:
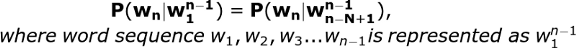
Maximum Likelihood Estimate (MLE)
The way to estimate the probabilities is to use Maximum Likelihood Estimation (MLE). This is based on taking counts from the corpus (the text data dump is usually referred as corpus in LM) and normalising them to lie in the interval of 0 to 1.
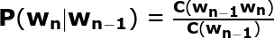
For example, to compute the bigram probability of word ‘Tebet’ following word ‘Stasiun’ is to count the bigrams c(‘Stasiun Tebet’) from the corpus and normalise it with the number of bigrams that starts with ‘Stasiun’.
We used Markov Assumption for building the most probable gate name n-grams starting with varying history from 2 to 4 and then choosing the most probable n-gram output from the combined output.
Journey from booking-related-text to pickup gate names
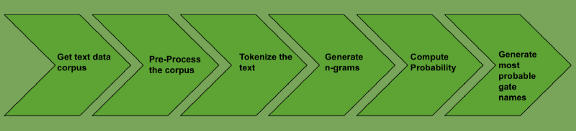
Corpus is generated by collecting historical booking-related-text data for each of the gate clusters for a particular POI.
This corpus is then pre-processed to remove inconsistencies in the text data, remove stop-words or non-name contributing words like ‘wait’, ‘hurry’, ‘late’, phone numbers etc. Pre-processing is the heart of any text mining exercise and is also a step that is hugely use-case dependent. For example, prepositions are generally considered as stop words for most of text manipulations like summary extraction, topic modelling etc. But for our use case, prepositions like ‘at’(di in Bahasa Indonesia), ‘in front’(depan in Bahasa Indonesia) etc. were not really stop words.
The cleaned text is then tokenised to create unigrams. These unigrams are then combined to get multiple n-grams. Starting with top bigrams for each gate, most probable higher n-grams are generated using the conditional probability of the Markov Assumption.
Since no machine learning algorithm fits as it is to every business solution, we had to put a layer of business logic check over the n-grams generated. This was to avoid cases of considering only those phrases that have higher representation in the overall booking-related-text data and higher coverage not just in the booking-related-text data of that gate. This, in a way, also asserts that there are enough number of bookings from that particular gate, with the most probable name being generated by the language model.
Smoothing
Because of the limited corpora, most word sequences might get assigned to zero probability. Imagine cases where a particular n-gram has never occurred in your corpora. The MLE estimation gives accurate results when the sequences are frequent in our training data, but it does not give good results in zero probability sequences and sequences with low frequency. To deal with these cases, various smoothing techniques like add-one smoothing, KN smoothing and Laplace smoothing can be used.
Thanks to the immense number of bookings on the Gojek platform, we had an abundance of data and didn’t face much trouble on this front. Hence, we chose to resort to simple ‘add-one smoothing’ technique for the cases of sparsity.
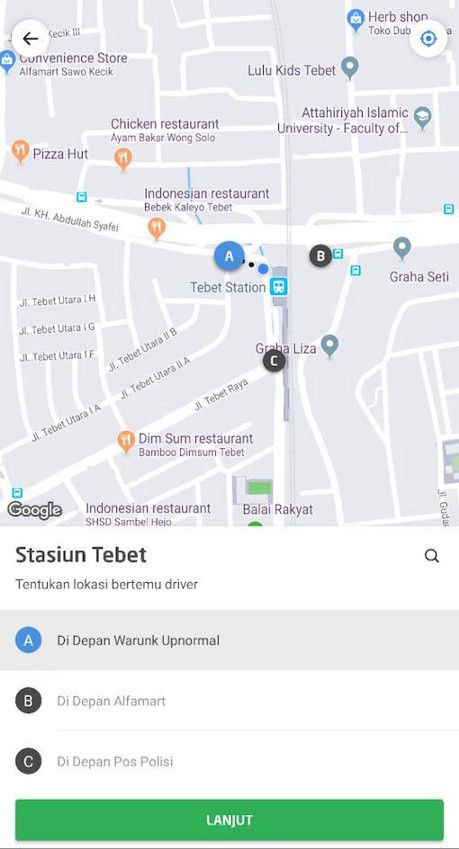
The final output of the language model produced gate names for both ride/car services for each POI. Here is how the gate names finally shaped up:
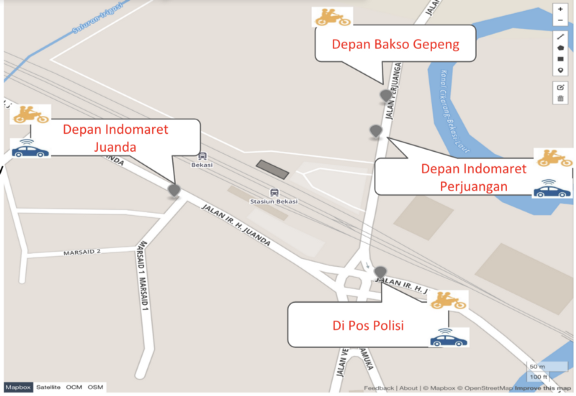
In the end, it was language modelling that made the naming of these gates so cool! 😄
This is just a glimpse of one cool problem we solved at Gojek. There are many more projects ongoing and in the pipeline. Stick around to get updates on them. Or better yet, join us! Visit gojek.jobs and pick your passion.