How GO-JEK handles microservices communication at scale
Microservices are great. They offer a way to split a monolith into independently scalable and maintainable chunks.

By Soham Kamani
Microservices are great. They offer a way to split a monolith into independently scalable and maintainable chunks.
One of the challenges engineers face while adopting this architecture is the task of making these services talk to each other at scale. As the number of services go up, the conversations between them gets increasingly complex.
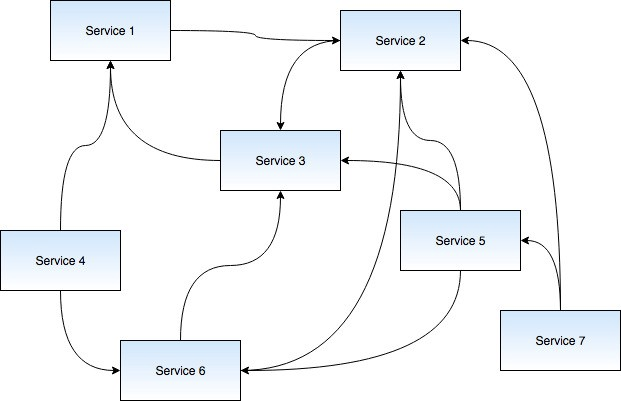
As you might have guessed, a lot of things can go wrong:
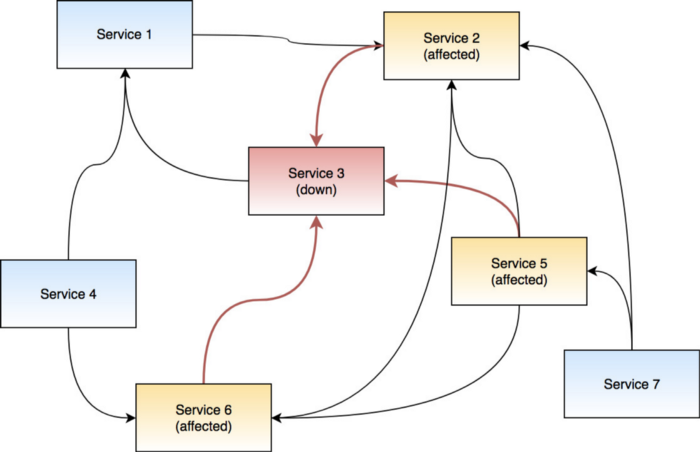
- One of the services may go down; which may not be such a big deal on its own. But when you consider there are many other services which depend on the one experiencing problems, things can get ugly really quick.
- One of the services may be taking too long. This is especially problematic when a service goes down. Most of the times, the supporting applications handle errors gracefully, but when a downstream service slows down, it also slows down other services that depend on it.
- Growing pains: Often enough, we see services making too many requests under heavy load. Unless these requests are limited, they can cause the called services to slow down or go down (which, incidentally, cause the previous two problems.)
Fortunately, there are many options to deal with problems such as these.
TLDR : Adding Heimdall to our services made it much easier to handle failures and ensure our service errors are localized only to the service at fault.
Heimdall to the rescue
Let’s see how to create an HTTP client with Heimdall that you can use to make calls to your downstream services:
The above code created an HTTP client with the following properties:
- A maximum timeout of 1000ms per request
- The maximum of 30 concurrent requests
- A maximum of a 20% error rate
- A sleep window of 1500ms
- A period of 500ms between subsequent retries
- A maximum of 4 retries
You can then use the client to make HTTP requests. For example, if you want to make a GET request and display the contents of the GojekEngineering home page:
Heimdall uses a bunch of mechanisms to increase resilience in any microservice architecture:
Retries
One of the simplest, but most effective solutions is to simply retry what you were going to do if it does not work the first time. If the error is intermittent, chances are, it’ll work the second or third time around.
Some of the things you would want to consider when retrying:
- Is the error intermittent? If the nature of the error indicates that it will fail no matter how many times you try (think authentication and validation errors), it doesn’t make sense to retry.
- How often do you want to retry? Even if the error is intermittent, you don’t want the calling application to try forever. If there are many errors, the number of retries for each failed request could lead to a huge increase in the total requests being sent, which can lead to unnecessarily high load.
- What is the time interval you want to wait for before trying again? The assumption here is that if an application gives an intermittent error, there is something wrong with it, and for that we would should give enough time for the application to recover. Most of the times, this interval increases for each subsequent retry.
Circuit breakers
Every modern household electrical system comes with a circuit breaker. A circuit breaker trips whenever it senses there is too much current flowing through the wire. It prevents a connected appliance from sustaining any damage due to the excess current.
This concept is also used to prevent damage to your applications in case there is too much load on one of your services. In order to implement this, we set a bunch of restrictions that are verified every time there is communication from one service to another. If one of the restrictions is violated more than a fixed number of times in a given time period, this communication is cut off for some time.
The restrictions put in place account for things like the frequency of requests sent, and the time it takes for the downstream service to respond:
Timeout
We can set a maximum time within which we expect a response from the downstream service. If the response takes longer, it’s registered as an error. Adding a timeout helps us with the problem of one service slowing down the whole system.
Maximum concurrent requests
This restriction is put in place to limit the density of requests going to the downstream service. “Concurrent requests” are a group of requests which are still awaiting a response from the downstream service.
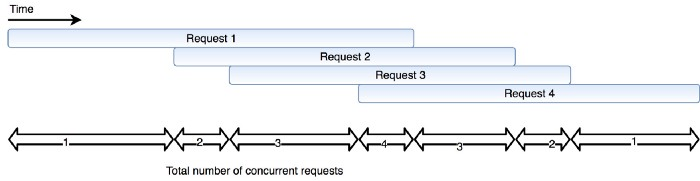
If our circuit breaker finds that the number of concurrent requests exceed the set maximum, an error is triggered. It’s worth noting that this threshold can be crossed if:
- The downstream services response time suddenly increases; which in turn would cause the pending requests to pile up, leading to a spike in the number of concurrent requests measured.
- The number of requests suddenly increases from the calling service.
Both these conditions occur when something goes wrong in a system. So capping the total number of concurrent requests is a good way to ensure the health of your application.
Error threshold percentage
The error threshold percentage is the point at which the circuit breaker finally trips. If the ratio of the total number of errors (as triggered by the other restrictions) to the total number of requests goes beyond this value, the circuit breaker stops any more requests from going downstream.
Sleep window
When the circuit breaker trips, it doesn’t stay like that forever (that would actually make the situation worse!). Instead, we set a time after which the circuit closes again, which we call the sleep window.
It’s important to set your sleep window such that it gives enough time to the downstream service to recover, while at the same time is not large enough to cause any sort of downtime to your existing users. For most cases, a window of 0.5–2 seconds is sufficient. Your mileage may vary depending on the nature of your application.
Retries and circuit breakers in practice
At GO-JEK, the number of services we have in production increases everyday. This, coupled with the enormous scale that we operate at, necessitates a robust system that can handle a large number of HTTP requests between our many services. In order to make it easier for our services (most of which are written in Go) to implement the principles we discussed, we developed Heimdall.
You can read more about how to use Heimdall by viewing the repository on Github, or see the full documentation on godoc.org
Adding Heimdall to our services made it much easier to handle failures and ensure our service errors are localized only to the service at fault.
If you’re wondering how we came up with the word ‘Heimdall’ — He’s a fictional character based on the god Heimdallr of Norse mythology. We all love comics, and a lot of our internal services are named after comic characters.
Any tips, recommendations, suggestions? Would love to hear from ya’ll on best practices, what worked, what didn’t. And… We’re hiring! Head to gojek.jobs to know more.
