Hospital — Our Automated Solution for System Failures
Introducing Gojek’s open-source solution designed to ‘heal’ common system failures without developer intervention.

By Jainam Shah and Dilip Sharma
In the case of a system failure, most developers are aware of the triaging steps. That said, a lot of time is spent applying simple fixes — over and over again.
In this post, we introduce Hospital, an automated scripts runner that receives alerts and triggers scripts to prevent and fix problems without human intervention. The aim here is to keep systems alive while fixing known failures fast.
What is Hospital?
As the name suggests, it offers surgical treatment for sick or injured systems
For each System or VM, there is a monitoring system that collects metrics from different services and stores them in a time-series database. Alertmanager is a tool for processing alerts, which de-duplicates, groups, and sends alerts to the appropriate receiver. Hospital acts as a notification channel for Alertmanager. When an alert is received, Hospital automatically triggers a script. The script can prevent or fix the problem.
Why did we build it?
Some reasons to automate this include:
- No human intervention needed for known issues
- Save time on common failures
- Ensure availability of product

Why is Hospital better than humans?
- Immediacy: An automated feedback loop will always be quicker than humans
- Consistency: Different humans may operate differently while applying the same runbook for a known failure.
Bird’s Eye View
Let’s understand how Hospital works at a high level.
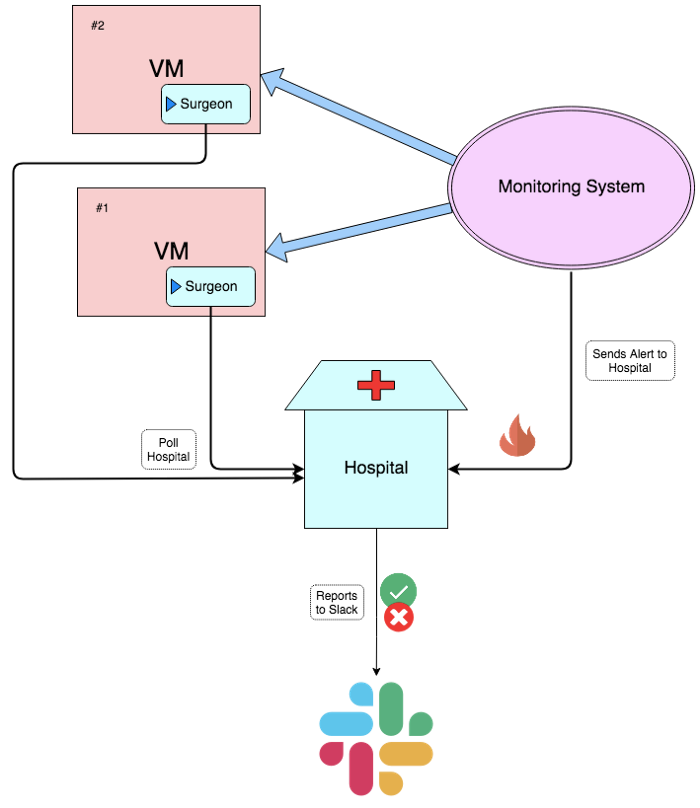
An application is running on a VM, and is monitored. Upon failure of the application, the monitoring system alerts hospital using a webhook. For each alert, Hospital is configured with certain scripts. Hospital’s agents, also known as Surgeons, are running on the application VM. They poll hospital frequently, and run the relevant script when an alert for the application has been triggered. After running the given script, the logs are reported to the users via Slack.
Demonstration
Let’s setup a system, and try healing it automatically using Hospital.
We will setup a LoadBalancer (HAProxy in our case) on a VM. We are monitoring the metrics of HAProxy and have configured alerts on queue build up. Hospital acts as a notification channel for the queue build-up alert. Surgeon — an agent of Hospital — is set up on the VM of HAProxy. After the setup, we will generate a queue artificially and try to fix it.
Present Scenario
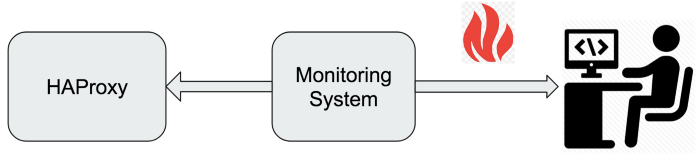
Currently, when an alert is triggered, it is received directly by a developer via Pagers. After receiving the alert, developer tries to fix it.
Pleasant Scenario
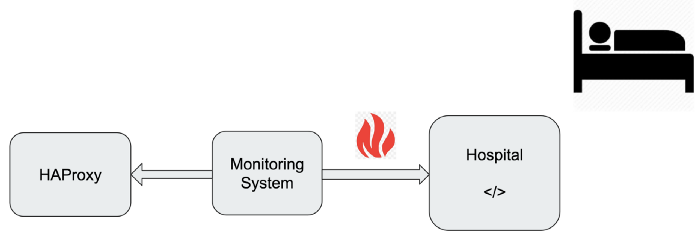
In this scenario, Hospital will receive the queue build up alert, apply the script instantly, and report the result to developers asynchronously.
With Hospital watching, developers can sleep peacefully. 🛌
LoadBalancer
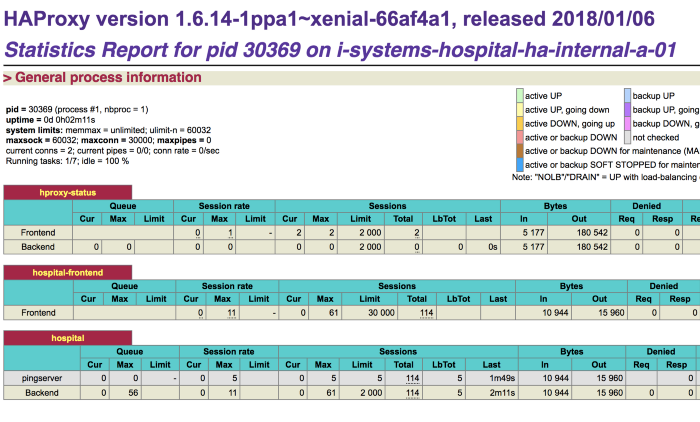
Alerts in Prometheus
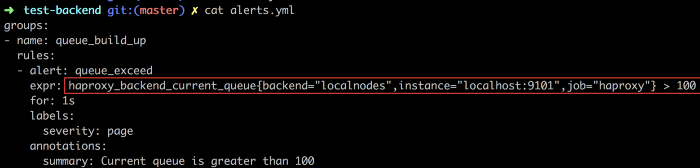
We are using Prometheus for monitoring HAProxy.
It is good to set up alerts on queue build up of a LoadBalancer. So, we have configured alerts for queue build up greater than 100.
Configure Hospital API in Alertmanager
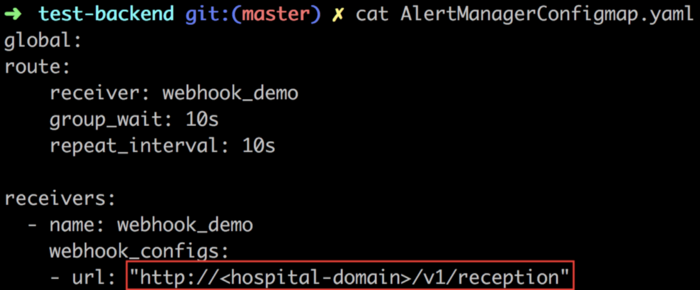
Using Alertmanager, we are sending alerts to Hospital running on port 8080.
Configure Hospital for alerts
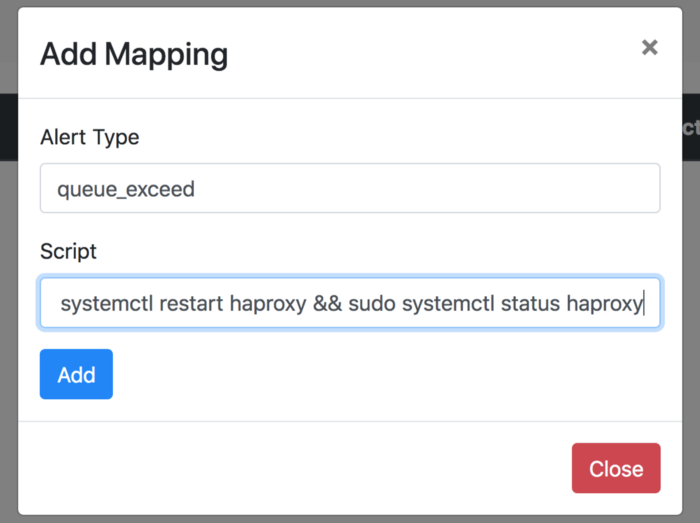
Now, when Hospital receives an alert of queue exceed, it’ll execute this script, which has been added using Hospital’s Dashboard.
Start the Surgeon’s Shift (Script Runner)!
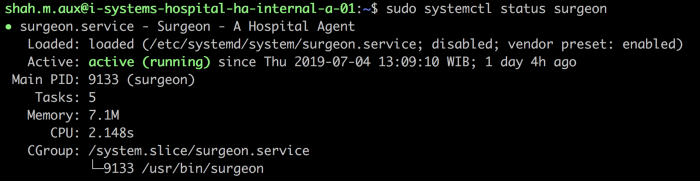
As mentioned above, Surgeon is an agent of Hospital. We’re running it on the VM of HAproxy to execute scripts
Brace for Impact!!!

We’ll artificially generate a queue on HAProxy, which will trigger an alert.
How is a Queue generated artificially?
- Setup maximum connection on HAProxy as 5.
- Induce sleep in the backend server of HAProxy.
- Now when you keep adding more requests, they will not be served and the queue will start building.
Hospital, you’re up.
Reporting
We are sending the results of scripts run by Surgeon in Slack. Detailed logs can be viewed on the dashboard, along with the summary of each VM.
Demo Video
We attack using Vegeta. You can see in Grafana Dashboard that the queue is building. An alert is triggered, and voila, fixed by Hospital.
What Hospital is Not
The script is intended to treat the symptoms. The root cause may not be fixed. For example, the symptom of a queue buildup at LoadBalancer level can be fixed by a restart. However, the root cause, which may be a database slowdown, will not be fixed.
In conclusion
For repetitive and mechanical tasks, machines are better than humans. Period.
Hospital reduces MTTR by at least 5 minutes compared to a human.
We’ve open sourced Hospital! 🏥 You can find it here:
 gojekfarm
gojekfarm
Try out Hospital to heal your systems and let us know the feedback in the comments below!!!
Keep watching this space for more updates, or sign up for our newsletter to have them delivered to your inbox. 😎

