Handling Dead Letters in a Streaming System
How we solved the critical problem of invalid records that broke our streaming pipeline.

By Chakravarthy VP
Did you know? We’ve completed well over 3.5 billion transactions since the launch of the Gojek app in 2015. With the staggering number of orders, merchant partners, driver partners, and consumers who are part of our ecosystem, one can imagine the abundant amount of data we work with. And one can also assume the issues faced by us, that have the potential to topple the products we’ve built with a lot of love. 💚
In this post, we’ll uncover the reliability-related issues that arose due to invalid data and how we solved it.
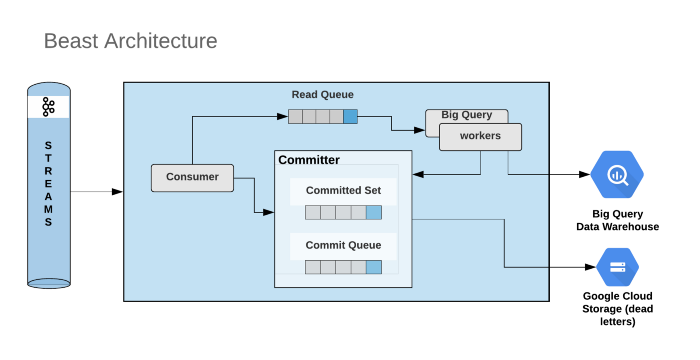
If you’re an ardent follower of our blogs, you might remember reading about Beast, an open-source initiative from Gojek that moves enormous volumes of data from Kafka to Google’s BigQuery (BQ).
ICYMI, read about Beast in detail, here.
For us, Beast is a scalable solution to move data, in near real-time, in a standardised format. The exponential growth of data is backed by the Gojek data platform that enables multiple stakeholders in Gojek to gather, process, gain deeper analytical insights to make key informed decisions supporting our growth framework.
The Design
Beast comprises of the following key components:
- Consumer: Kafka consumer threads that consume data from Kafka topic partitions in batches
- BQ Worker: Worker threads that process the batch and push it to BigQuery
- Committer Thread: Threads that commit the offset to Kafka
Blocking Queues: Each thread group is decoupled through Queues. This design enables us to vertically scale individual components based on the application’s requirements.
The Worker threads work on the batched/polled consumer records from Kafka, deserialise using protobuf schema, flatten the data set, and store the records into BigQuery tables.
The Requirement
Zero Data Loss: One of our key requirements is to have Beast process each data point at least once without compromising the throughput and data integrity.
Beast deployment in a nutshell
Each Beast deployment is a Kubernetes Deployment.
Currently, we have more than 500 deployments of Beast, pushing tens of thousands of Gigabytes of data per day.
Each Beast instance (Kubernetes pods) consumed from one topic deserialises the bytes based on the schema enabled for this topic. We have different Kafka, Kubernetes clusters deployed with Beast for different geographical regions (Indonesia, Vietnam, Thailand). Having a Beast instance/topic/schema allows us to scale based on ingestion volumes or throughput for each topic individually.
Let’s look at the problem statement
Erroneous events that are part of the data stream could fail different parts of the system, which can lead to constant crashes — eventually building the kafka consumer lag, resulting in data loss.
‘Unbounded Data’ are streaming events pushed by various producers in the system (application domain). Events confirm to a protobuf schema. Sometimes, the producers supply invalid records that fail our processing. In general, here are some erroneous types of events:
- Invalid Data: These are semantic validation errors where the source protobuf schema is intact, but the data is invalid.
- Invalid Schema: This is when the source protobuf schema is invalid. Cases like a retyped field fall into this category.
- Partition Key Out Of Range: This is a case where the schema has a timestamp field that falls outside the allowed range, say, 1 year in the future. One of the mandatory fields in each event, a ‘timestamp’ type, is on which the Big Query tables are partitioned. This field signifies events produced time and is set by the producers.
Big Query rejects inserts when the event time data falls outside certain ranges as mentioned above. When this happens, the worker threads bomb out of the stack gracefully and the internal queue fills up without processing. The consumer threads fill-up the bounded queues since BQ consumer sink does not process them, timing out eventually, breaking from the thread, and thus failing the Beast instance. The subsequent restart of the instance starts with the uncommitted offset, which has these invalid records failing beast again.
When Beast is on a constant CrashLoop…
- It leads to enormous unprocessed volumes of data sitting in Kafka, with eventual back pressure building up.
- The invalid data that broke the instance needs to clear up. Manual intervention is needed to enable Beast to continue processing the valid records. This is done by changing the consumer group with the latest offset (which leads to data loss).
- Troubleshooting is expensive.
Also, why do things manually when they can be automated? 🤷♂️
The Solution: Dead letters stored to GCP
We decided to build a ‘Dead Letter Store’ for out of range partition keys, which enables the following:
- Unprocessed messages are stored in a separate store, and they can be exposed to diagnosis for applications.
- Improves reliability.
- Includes metrics to segment applications that produce these messages.
- Alerts relevant applications.
We brainstormed different solutions, including publishing these erroneous records onto Kafka. With the deployment architecture, as described above, having a Kafka dead letter topic per Beast deployment is cumbersome. There were a few cons with this approach:
- Additional overhead in managing the DLQ topics. The number of topics needed would be: ~ (no of clusters * no topics that run Beast). This would be thousands of topics overall!
- Overhead in running additional instances (instance/topic or schema) to store these messages to an additional store.
- Increased cost to maintain the cluster.
As an alternate solution, we decided to proceed with dumping these invalid messages (dead letters) to Google Cloud Storage.
Key aspects of the solution design
- The validity of the record is not determined when an event is consumed as it will increase the processing latency and reduce the throughput.
- We handle invalid messages only on failure to insert a batch to BQ.
- On failure to push to BQ, we assess the validity of the failed batch, split the records into those that are valid and invalid. The invalid records are stored in GCS. The valid records are retried to push into BQ. This is synchronously processed in the same Worker thread.
- The error records are gzip-compressed and stored as GCS object, partitioned into respective topic/dt=date-time paths.
- We also update metrics on the processed erroneous records which are shown in Grafana. We enabled alerting on these metrics.
Below is a code snippet that uses Google Cloud SDK to store these messages.
 262588213843476
262588213843476
Applications are alerted automatically when they produce out of range records through internal channels.
This solution improved the reliability in Beast. 🖖
