GANA: A solution to keep up with scale

By Jenson CS
Building scalable and maintainable infrastructure is a complex problem when you have 18+ products. We have around 500+ microservices provisioned on Google Cloud Platform (GCP), Amazon Web Services (AWS), and our own data centers. We started with a single Google project called gojek-production and deployed all our workload there.
8000+ instances in a single Google project.
At present, gojek-production is our legacy infrastructure project. Internally, this project is called ‘infrastructure Stan Marsh’.
Managing such a big project became very difficult. So we decided to break it down into namespaces. A new namespace is defined as a segregation on the basis of network isolation which can be managed independently. It’s a Google project in case of GCP, a new organisation in case of AWS or a new VLAN for the datacenter.
For example, we have different namespaces like GO-PAY, GO-POINTS, Data Engineering, and BI. For each namespace, we created a separate Google project or AWS organization to enable this segregation.
This post explains how we solved the problem of infrastructure segregation at scale by developing an in-house network range orchestration tool.
With migration, came challenges
As the migration started, we started getting tickets to enable data communication between gojek-production and the new project.
“Ok….let’s create peering or VPN tunnels between projects to solve this issue”
Excellent. Job done 😎
Then the IP address clashes started.
- IP address clashes between VPCs
- Kubernetes IP address range clashes
- IPsec VPN address range clashes
Now, every time we create a namespace, we do it with a new network range which does not conflict with existing networks.
To manage the subnet details, we created a Google sheet with a predefined network range for different network types (VPC, Kubernetes, VPN). When the network range/ subnet required VPN, VPC or Kubernetes cluster creation, we allocated one subnet range and updated the document.
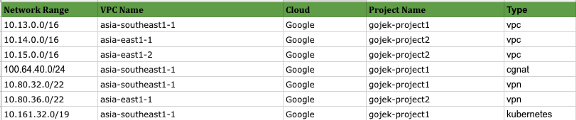
The challenge: we were still growing explosively, with no breaks. We had grown from a few hundred driver partners to over 100,000 (we currently have over two million). GO-FOOD had brought mom and pop shops online, and GO-PAY was providing financial inclusivity to millions in Indonesia.
Soon, the requests for new projects increased 300x. Google sheet copy-paste was not scaling anymore.
What do we do now? 🤔
We needed a solution which could handle network range orchestration for any use case — an IPM (IP address Management Tool). We searched for open source solutions, but did not find any. This led to us creating an in-house network range orchestration tool for GOJEK. We called it GANA (GOJEK Assigned Number Authority).
“That’s a weird name. Why GANA❓”
The name is inspired from IANA (Internet Assigned Numbers Authority) 😉.
GANA is GOJEK’s internal HTTP REST service which is written in Ruby on Rails. It is responsible for the coordination of address allocation to resources like VPC, Client VPN, Kubernetes and CGNAT (Cloud NAT). It can also support any kind of resource for future requirements.
How does GANA work?
GANA is a simple query system. You can pass your requirements to it, and if the resource is available with the given parameter, it will allocate you one subnet. Following the YAGNI principle, the Phase 1 implementation of GANA is a straightforward CRUD application.
To explain the full flow, let’s begin with using “10.200.0.0/16” as our subnet.
We divide the subnets using ‘ipcalc’ command to divide the large network into small chunks.
✝ ~ ./network_divider.sh 10.200.0.0/16 22
10.200.0.0/22
10.200.4.0/22
10.200.8.0/22
10.200.12.0/22
..............
..............
✝ ~ cat network_divider.sh
#!/usr/bin/env bash
LARGE_SUBNET=$1
DIVIDED_BY=$2
if [[ -z "$LARGE_SUBNET" && -z "${DIVIDED_BY}" ]]; then
echo "Required variables are missing. Usage: ./script_name.sh x.x.x.x/x x"
exit
fi
X=`echo $LARGE_SUBNET | cut -f 2 -d.`
for y in `seq 0 255` ; do ipcalc 10.$X.$y.0/$DIVIDED_BY|grep
Network|awk '{print $2}'; done |uniq- Seeding network ranges to Gana.
This creates a network range pool in GANA. The job requires three mandatory fields:
a. Subnet: The small chunks of network ranges which are generated using ipcalc or the above script.
b. Category: Type of network which is going to use the subnets. E.g: VPC, VPN
c. Size: Indicates the number of IPs available in the particular pool. In our case (VPN), we are dividing a class A subnet into “/22” and marking them as the default size.
> curl -X POST \
> http://ganahost.domainname.com/v1/networks \
> -H 'Content-Type: application/json' \
> -d '{
> "network": {
> "subnet": "10.200.0.0/22",
> "category": "vpn",
> "size": "default"
> }
> }'
>
> In the above example user creating a subnet in GANA pool for VPN category.2. Allocation
Allocation is a type of mapping between a network range and the project/VPC’s. GANA maintains unique combinations of project, category and network_name.
curl -X PUT
http://ganahost.domain.com/v1/networks
-H ‘Content-Type: application/json’
-d ‘{
“network”: {
“project”: “project1”,
“category”: “vpn”,
“network_name”: “asia-east1-01”,
“size”: “default”
}
}’
In the above example, the user is requesting a subnet for VPN. In GANA, we have already seeded one range for VPN.3. Show
Users can get the details of the network range allocated to any project for a particular category.
curl -X GET http://ganahost.domain.com/v1/networks/vpn/project1/asia-east1-014. Deallocation
Deallocation will remove the mapping between a network range and the project. GANA then ensures that the deallocated network ranges are available for the next project.
curl -X PUT \
http://ganahost.domain.com/v1/networks/deallocate \
-H ‘Content-Type: application/json’ \
-d ‘{
“network”: {
“project”: “project1”,
“category”: “vpn”,
“network_name”: “asia-east1-01”
}
}’
In the above exam user deallocating vpn network range from Gana which is used by project1 in asia-east1-01 vpc.How GANA helped us with infrastructure automation
We started our self-served infrastructure automation project — Olympus. We created a custom terraform provider for GANA and used the same in our automation. GANA ensures the uniqueness of IP addresses across all the namespaces. This helps the infrastructure team to avoid manual interactions.
GANA’s features can also be accessed through Terraform.
Here is an example of how you can allocate a subnet range for your VPN using Terraform:
resource “gana_allocate_subnet” “kubernetes_cluster” {
project = “project1”
category = “vpn”
network_name = “asia-east1-01”
gana_hostname = “ganahost.domain.com”
gana_username = “username”
gana_password = “${var.gana_password}”
size = “default”
}When you run ‘terraform destroy’ command, GANA provider will take care of subnet deallocation.
Here is an example of how Terraform ‘data’ resource can consume data from GANA:
data “gana_subnet” “dev_vpn” {
project = “project1”
category = “vpn”
network_name = “asia-east1-01”
gana_hostname = “ganahost.domain.com”
gana_username = “username”
gana_password = “${var.gana_password}”
}What’s next?
In future, instead of the seeding task, we can use an algorithm for auto-allocation depending on the type and size of the subnet.
We are also on the way to make GANA and its Terraform provider open source. Keep an eye on GOJEK’s GitHub repository.
Scale is what pushes us to build new things. We’ve scaled 6600x since we launched our app (just over three years ago!). We’re one of the largest food tech startups in the world, and the largest digital wallet player in Indonesia💪. We’re still scaling, and could use more help. If you want to be part of our journey, rush to gojek.jobs and be part of our growth story.