Fronting : An Armoured Car for Kafka Ingestion
We see 6 Billion+ events every day and it’s steadily rising. In order to make data-driven decisions, the completeness of data is a must.

By Prakhar Mathur
Data is the core strength of GO-JEK. Different teams produce a large amount of data to different Kafka clusters. To provide reliable and seamless publishing of these many events for transactional use cases where we cannot afford data loss, we have come up with a solution. We abstracted out the entire Kafka domain knowledge for the producers and provided them with a RESTful interface where they can push all events.
What problems are solved?
- Without a fronting cluster, all the teams will have to use Kafka clients in their projects, requiring a considerable amount of learning curve to understand Kafka
- Each team will require acknowledgements of proper ingestion of every message in order to make sure there is no data loss.
- In cases of failures, they will have to maintain their own data store, leading to a huge amount of buffering till the messages start going successfully.
Architecture
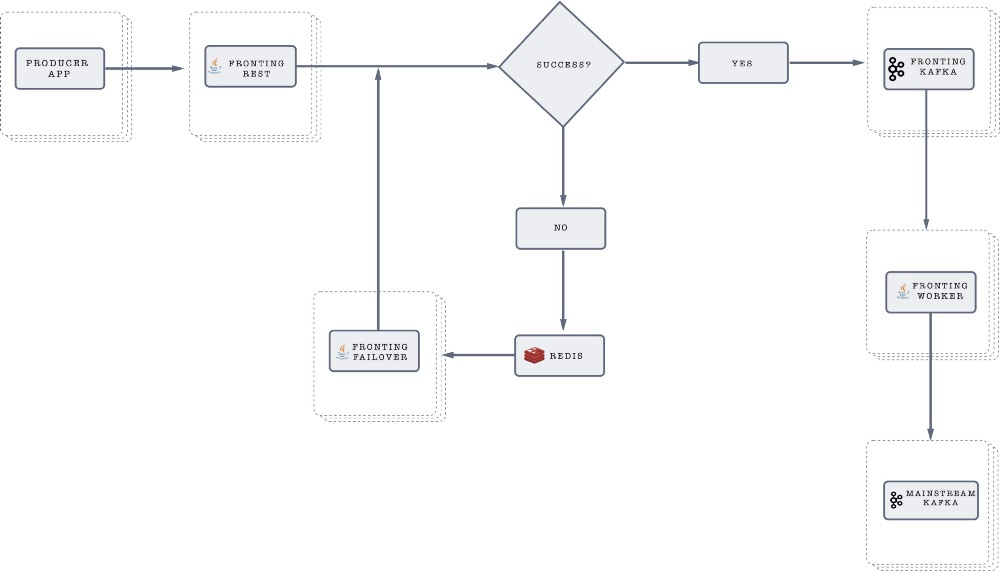
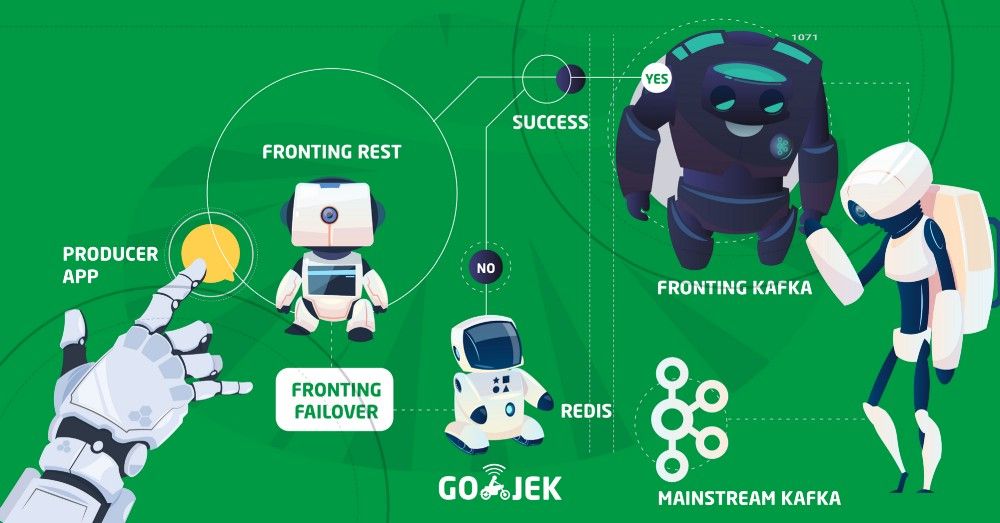
Data-flow
Every event from all the producer apps goes through following stages :
- Fronting REST : All the events first hit a REST server that can receive messages in batches or one by one. The server then tries to send these events to a Fronting Kafka. If it is not able to push it to Fronting Kafka, then it pushes to Redis.
2. Fronting Kafka :
- This Kafka plays a crucial role. Let’s say in some scenarios, our main Kafka goes down, then there won’t be any data loss, only the fronting worker consumer lag will keep increasing till the recovery of the main Kafka
- Thus, this Kafka acts like a buffer, instead of letting the producers worry about failed messages
- This Kafka also provides us with an abstraction, because of which we can push these messages to a fallback Kafka
- We can also start sending messages to a different Kafka cluster, just by changing configuration. The producing OMS won’t need to change configs or restart
3. Redis : If Fronting REST fails to pump events to Fronting Kafka, it pushes all those events to Redis.
4. Fronting Failover : It is a Java application which continuously checks for failed events in Redis. Once any failed message is received in Redis, it verifies if Fronting Kafka is up or not, and forwards the message to it as soon as it is up.
5. Fronting Worker : After successful ingestion of data in Fronting Kafka, Fronting worker does the job of consuming data from Fronting Kafka and pushes it to our target Kafka cluster.
Because of Fronting Kafka, we are also able to implement a Kafka Failover mechanism, wherein we have added one more fronting worker which will simultaneously push data to a backup Kafka.
Infrastructure
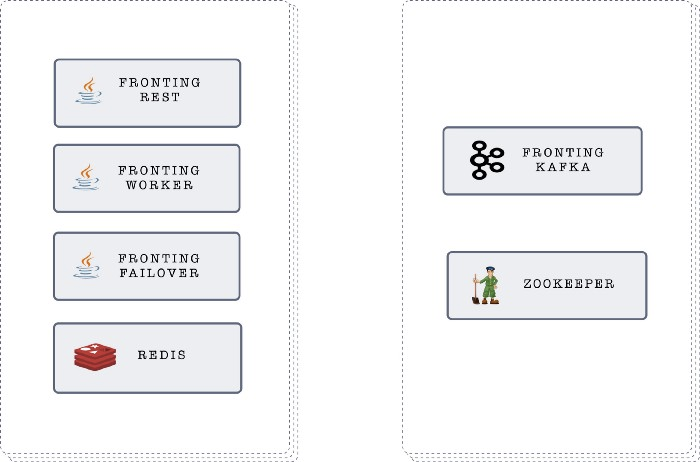
- In the above diagram, Fronting RES, Redis, Fronting Failover and Fronting Worker resides inside one VM, each being in an LXC container
- Fronting Kafka brokers and Zookeeper resides in different LXC containers inside one VM
- The reason behind putting Kafka brokers inside different LXC containers in one VM is to avoid syncing issues of brokers due to network latency
- Another reason being the easy deployment of these many separate services on one VM
- Producers publish data to fronting servers, particularly suited for high traffic
- Each team is allocated with highly available fronting clusters to avoid any single point failure
Conclusion
Without a Fronting Cluster, every team would have ended up handling all of the aforementioned problems by themselves. Now, all of them can publish events just by sending them to a REST server and leave all the Kafka related issues to the cluster itself.
Happy Data Publishing!
We’re hiring! Join us. Solving some of these grand problems requires a lot of engineering ingenuity. If you have what it takes, and are interested in working with a startup expanding across SouthEast Asia, please check our gojek.jobs for more.
