Feast: Bridging ML Models and Data
A breakdown of the open-source machine learning feature store developed by Gojek with Google Cloud.

By Yu-Xi Lim
A year ago, we first announced Feast with our friends at Google. Feast is our solution for feature management, storage, and serving. In this post, we revisit this most critical stage of the machine learning life cycle as the next part of our series on Gojek’s Machine Learning Platform.
Introduction
Features are the lifeblood of modern machine learning systems. No other activity in the machine learning life cycle has a higher return on investment than improving the data a model has access to. However, the process of creating, managing, sharing, and serving features can also be one of the most time-consuming activities ML teams focus on.
Feast, an open-source feature store for machine learning, sets out to address these pains. In this blog post, we will explain the motivation behind building Feast, as well as the impact that it has had at Gojek. We will more deeply explore the functionality Feast provides and our vision for the project going forward in a separate series.
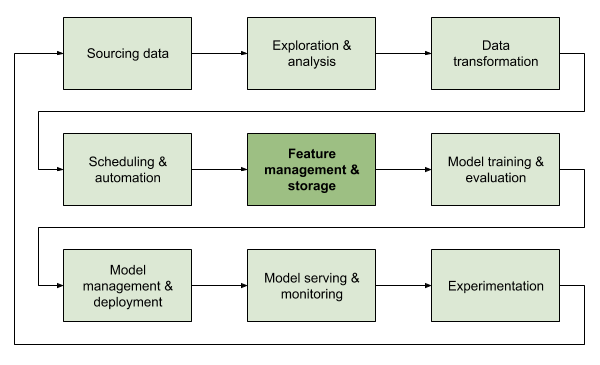
Matching customers to drivers
Allocating the right driver to a customer is an essential decision in any kind of ride-hailing service. At Gojek, millions of customers are allocated to hundreds of thousands of drivers every day. We have huge amounts of data to optimise our decisions, which in turn drives objectives that balance the needs of our drivers and customers.
It should not come as a surprise that one of the first end-to-end machine learning systems we built at Gojek was an ML-powered driver allocation system. The first iteration of this system was nothing more than a single model, served as a web service, that ranked drivers. Over time, this system has evolved into a robust multi-objective system called Jaeger capable of optimising dispatch time, driver utilisation, income, cancellation rates, and more.
The models that Jaeger is composed of all have one thing in common: They depend on features to make the right decisions. These features allow Jaeger to:
- Know how long a driver has been waiting for a trip to prioritise them
- Accurately locate and route drivers to customers to optimise arrival times
- Account for demand changes in areas to efficiently balance driver supply
The problems with features
It was clear that we had to make it very easy for the Jaeger team to develop and iterate on features. Yet despite designing our initial data infrastructure with this goal in mind, we still ran into many challenges while scaling up our systems.
Getting features into production is hard: As domain experts, our data scientists would typically do all data transformation and feature engineering tasks, the results of which are stored in our data warehouse. However, when moving to production we had no standardised way to serve these features to online systems. This meant that engineers would need to be involved in setting up database clusters, data ingestion jobs, infrastructure monitoring, etc, for each model, each project, each environment, and each region.
Inconsistency between training and serving: In managing this now overly complex infrastructure, we soon realised that we had inconsistencies in feature data between model training and serving. This was because feature transforms had to be re-written from Python for online serving. Not only were we spending more man-hours on the same task, but we were also creating a source of inconsistencies which ultimately led to training-serving skew.
Features not being reused: The majority of Jaeger’s features are based on three entity types: Customers, Drivers, and Areas (S2 cells). Over time, other project teams also began developing their own features on these same entity types, but strangely none of these features were making their way into Jaeger. There was no easy way for the Jaeger team to know which features other teams were developing, and no simple way to integrate these features into Jaeger without reimplementing them.
Feature definitions vary: The definition and intent of features for Jaeger were completely defined in code. Which is another way of saying “not at all”. Without a centralised way of defining features in a way that non-technical folks can understand, we remained unable to standardise definitions across the organisation.
Enter: Feast
At the start of 2019, we introduced Feast, a project we developed in collaboration with Google Cloud to address the challenges we were facing in Jaeger and other ML systems. Feast allows teams to define, manage, discover, and serve features.
Feast sits squarely between data engineering and ML engineering. On the one side, you have data owners (data engineers, data scientists) creating data sets and data streams (outside of Feast) and ingesting them into the system. On the other side, you have ML practitioners who consume these features, either during training or serving.
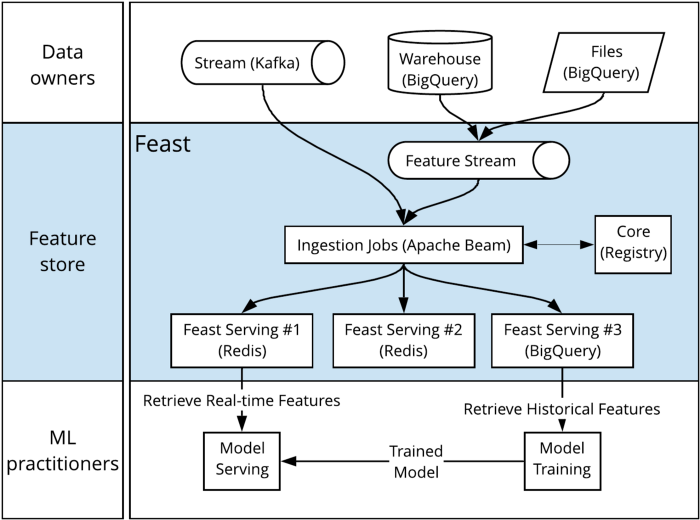
Once deployed, getting features in and out of Feast is simple, and can be done using our Python, Java, or Golang SDKs.
Beyond connecting the feature producers to the feature consumers, Feast also provides other conveniences for both parties:
Decentralised serving: As a platform team we built the original Feast as a centralised service, but many of our customers are other engineering teams who want to deploy their own instances of Feast. Subsequently, we decoupled data ingestion from the layer that populates Feast data stores by introducing a common feature stream. Feature data is now centrally persisted on this feature stream after ingestion and is made available to any number of Feast serving deployments, some of which are managed by other teams.
Unified feature serving API: Despite the original release of Feast having consistent data access and feature identifiers, it still had two distinct APIs: One historical and online. We have now unified these APIs into a single gRPC layer. The goal of this unification is to minimise any variation in client-side code between training and serving.
Consistent feature joins: A data scientist needs to produce a data set from multiple upstream data sources that are being updated at different rates (minutely, daily, etc), for a specific group of entities (drivers, customers, etc), for a specific list of features, over a specific period, and joins the features in a way that is consistent between historical retrieval and online serving. This is something that Feast does out-of-the-box to ensure that there is no training-serving skew between the two stages of the ML lifecycle.
Project isolation: More recently, we also introduced the concept of ‘projects’. Projects allow for resource isolation, meaning users can create feature sets, features, and entities within private namespaces. They also allow for simplified retrieval from the serving API, meaning users can now reference features inside projects directly.
Jaeger on Feast
Downstream from data production are our ML teams working on end-to-end systems like Jaeger. Once data is ingested, these teams can simply select a list of features from Feast to training their model. Once they are satisfied with the results of training, the list of features is exported, with the model binary, and persisted in our model store.
At serving time, the model is loaded with this list of features into a model serving application. Every incoming prediction request first triggers a feature value lookup from Feast using this list of features, after which the features are fed into the model. For the Jaeger team, this removed the need for redeveloping feature transformations in the serving layer and allowed for the standardisation of feature retrieval on a single feature serving API.
From the perspective of a data scientist, the process of creating features and using these features in a project are now distinct tasks. In fact, they are often performed by different teams at different times. For the Jaeger team, this means much faster iteration times since they only have to focus on feature selection. The infrastructure will take care of serving and online feature data access.
From an engineering perspective, it means we only have to manage a single infrastructural piece that scales horizontally to more feature producers and consumers, thus freeing up our engineers from having to manage project-specific data infrastructure.
What’s next?
Feast users have been asking for better insight into their data, both in-flight and at rest. For Feast 0.5, coming in March, we are making our APIs TFX compatible to allow for feature statistics generation and validation for both batch and streaming data. This will allow Feast users to have a deeper understanding of data that is available throughout Feast and will allow them to react faster to changes in data in production.
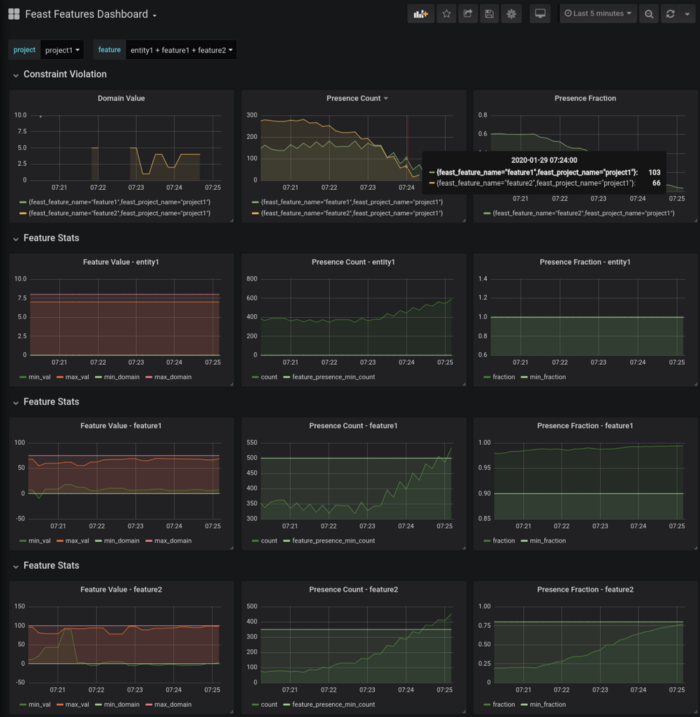
We are not stopping there. In future versions of Feast, we will also be addressing feature transformations, feature discovery and cataloging, and AAA.
We have been pleasantly surprised at the community interest in Feast and have received lots of great feedback and pull requests. We would especially like to thank our friends at Agoda who have been very active in discussions and implementation. If you want to find out more about Feast or help out in any way, do check out these resources:
- Project website: https://feast.dev/
- Come and say hello to us in #Feast
- Our documentation: docs.feast.dev
- GitHub repository: gojek/feast
- Mailing list: feast-discuss@googlegroups.com
If you are excited by the idea of developing such tools for data scientists, please consider joining Gojek’s Data Science Platform team.
Contributions from:
David Heryanto, Shu Heng Khor, Willem Pienaar, Zhiling Chen
