Enhancing Ziggurat - The Backbone Of Gojek's Kafka Ecosystem
What makes Ziggurat more useful, robust, and reliable than ever?

By Prateek Khatri
We love creating open source projects. Innovating and enabling the community to benefit from what we build has always given us a high. One such projects is Ziggurat — a framework built to simplify stream processing on Kafka. It can be used to create a full-fledged Clojure app that reads and processes messages from Kafka.
Ziggurat, which forms the backbone of the Kafka-based event driven ecosystem in Gojek, is used by over 250 services.
Its tight integration with an internal code-generation tool (which we fondly call The Kernel CLI) and a deployment service (The awesome Lambda Manager) makes the process of bootstrapping the first version of Kafka consumer a matter of milliseconds.
Building our Ziggurat
As with most first versions of products, there were some gaps and flaws which used to pull our devs and the Ziggurat Team in prod support issues, leading to 10s of man-hours to fix them. There were crucial Kafka features (released in later versions) which were required on the field, but weren’t yet implemented in Ziggurat. Repeated user feedback about almost every feature in Ziggurat persisted.
As a result, both users and the Ziggurat Team were loosing time and productivity.
Thus, we embarked on the journey of gradually and incrementally fixing things, adding value and improving reliability of this useful framework.
RabbitMQ auto-reconnect: The most critical bug fix
Earlier, we would spend hours resetting Kafka offsets for Ziggurat users to cover for lost messages. The message loss would happen whenever a RabbitMQ VM got restarted due to GCP maintenance. FYI, Ziggurat sends Kafka messages to RabbitMQ for async processing by workers.
The root cause behind this issue was a bug where the Ziggurat code tried to connect to RabbitMQ only 5 times till a max of only 500 ms!
That’s too low, isn’t it? 500 ms might cover minor network glitches but certainly not VM restarts or process shutdowns which can run into minutes.
So, what did we do?
We changed the logic to retry connecting to RabbitMQ infinitely. Basically, this enforced Ziggurat to not process the next message till the current one is pushed to RabbitMQ, no matter how long it takes. So, in the worst case the Kafka lag rises till the RabbitMQ server is back up. But, most importantly, the user doesn’t lose messages.
Although, if you’re thinking, “Shouldn’t infinite retries solution been there since the Day 1?”… Yes, it should’ve been. But there’s no cogent reason to explain when a feature becomes a bug, and it’s important to learn throughout the process and evolve.
We also added support for RabbitMQ cluster. The services can now save themselves from a single point of failure by avoiding the legacy one-node deployment.
Let me show you a screenshot of the monitoring dashboard we use to track all the useful metrics of this cluster:
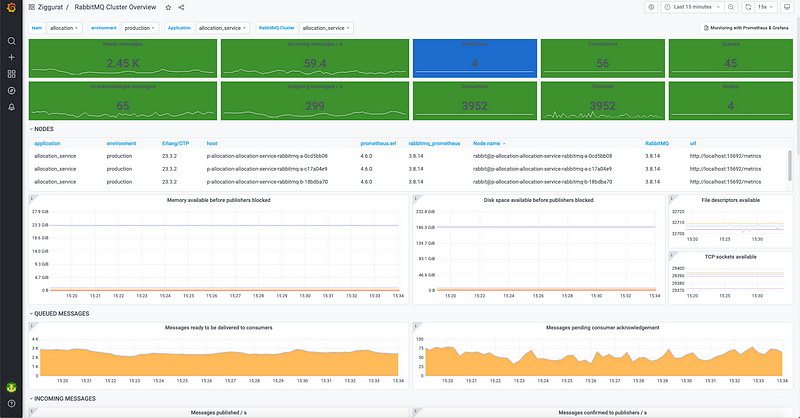
Here are other prominent improvements that were made to Ziggurat:
The Bulk Consumption feature via Kafka Consumer API
Sometime in July 2020, the GoFood team learnt their Kafka Streams app was going to receive messages in bulk from a Data Science model. GoFood’s Kafka consumer app used to make one call to ElasticSearch for every Kafka message read, i.e. O(n) calls, where n = number of messages read.
The obvious answer to this was consuming messages in bulk and make one network call to ElasticSearch for a batch of messages.
We figured out that implementing bulk consumption using Kafka Streams API would be a little convoluted. On the other hand, Kafka Consumer API seemed the right fit here. So, Ziggurat and GoFood team collaborated for a month spiking, planning, testing and integrating the Kafka Consumer API into Ziggurat.
This exercise provided users a choice while consuming messages. They can now use Kafka Streams API for the stateful operations like Stream Joins, Grouping and Aggregations while Kafka Consumer API can be used for simple consumption tasks.
Improving the use of Kafka Streams API
Well, the original event which triggered a series of improvement to the use of Kafka Streams API was a production issue which has been described in detail in this blog. The fix for the issue required us to add a Kafka Stream config default.api.timeout.ms which was not supported in Ziggurat yet.
While releasing a fix with this configuration, it struck us that we had been lagging behind in keeping the Kafka client up-to-date and we could make a lot of value by making small, incremental upgrades. Thus, started a journey of bringing in all the improvements of Kafka into Ziggurat.
Incremental co-operative re-balancing
Before Kafka Streams 2.4, Kafka was infamous for its stop-the-world re-balancing which was improved substantially by adopting an incremental approach.
For the uninitiated, re-balancing is a process by which Kafka reallocates resources (message partitions) among the participating threads. This happens whenever a new thread joins or an existing thread leaves. Now, let’s think for a moment what happens during a rolling deployment of a Kafka consumer app running on multiple VMs.
You see the problem with stop-the-world, right? As the consumers are stopped and started (for deployment) one by one, for each stop and start event (i.e. Kafka threads leaving and joining), Kafka pauses all the activity to do a re-distribution of resources. This not only contributes to higher than usual Kafka lag, in Gojek the high Kafka lag causes the alerts to trigger every time during a deployment. This leads to unnecessary distraction and loss of productivity for developers.
That’s where incremental re-balancing saves us from the trouble.
Our own internal experiments have shown marked difference between the two approaches. With incremental re-balancing (since Kafka 2.4), we could decrease Kafka lag developing during the deployments and it took much lesser time for the lag to subside to normal levels.
You can read about this new more approach in this in-depth article.
Accepting all Kafka stream, consumer and producer configs
So, we took this opportunity to make some major refactoring in Ziggurat to ensure each and every config required by Kafka APIs could be provided by the Ziggurat user. This way, we saved ourselves from going through the entire release cycle just to add one config!
In the initial days, the knowledge of Kafka and adoption of Ziggurat was limited. So, we stuck to a limited set of most-used Kafka configs. But, now that the framework is being used by hundreds of services for more complex tasks, it made sense to accept all possible configurations.
Successive Kafka client upgrades ultimately leading to the awesome Kafka 2.8
While fixing the original issue (described above), we realised, while Kafka was planning to release version 2.8 in April 2021, Ziggurat was still stuck with Kafka Streams 2.1 in February 2021. Moreover, we could see that the critical issues we’ve faced over the months (for example, the frequent TimeoutException due to broker disconnection or the high lag during deployments) had been fixed in later versions of Kafka.
Having realised the gaps, we quickly released new versions of Ziggurat eventually ending up with Kafka 2.8.
Kafka 2.8 introduces a lot of useful features for streams, consumers, and brokers. You can read more about them in this informative article.
What we found really useful was the new StreamsUncaughtExceptionHandler which automatically replaces a Stream thread during uncaught exceptions. Additionally, APIs to start new threads and stopping the existing ones, and the default timeout handling makes the new Streams client (and hence Ziggurat) more reliable than ever.
Monitoring Kafka Streams Client
Going through all the successive upgrades (reading through Kafka KIPs and official upgrade docs), we noticed we’ve not fully utilised the metrics published by Kafka Streams client.
On several occasions in the past, we’ve come across issues with Kafka Stream clients which are hard to debug in absence of lower level Kafka consumer metrics.
The monitoring setup in Gojek (comprising of the telegraf agent on VM/Kube and deployments of Prometheus and Grafana) allowed us to quickly visualise these Kafka metrics on a dashboard.
The user gets an option to see Stream client level metrics or can dig deeper into Stream Thread or Stream Task level metrics too by selecting an appropriate host, thread or task from the drop downs at the top.
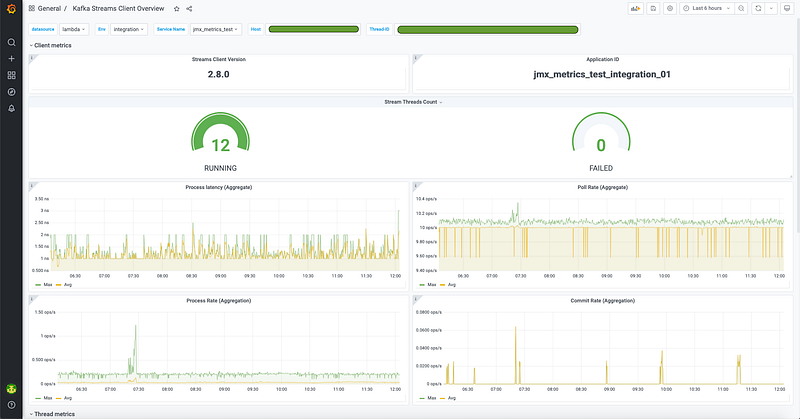
Other key improvements
Ziggurat Modes
Ziggurat is a blend of multiple tools (or behaviours) — a Kafka consumer, an embedded Jetty server and a collection of RabbitMQ workers.
Bundling all of them into one library makes it easier to not have multiple apps for multiple tasks during the initial phase of development. If any of these behaviours assume gigantic proportions, one can always spawn a dedicated app.
But, not everyone needs all of this. And, people often prefer to deploy their server and Kafka consumer separately. So, we introduced a concept of modes which allows the user to specify the modes they want to start the app with.
And, we built integrations with the internal CI/CD scripts making deployment and scaling different modes easier than ever. This provides the user the flexibility to manage different behaviours within a single app without the pains of managing multiple codebases.
This sums up the incredible journey Ziggurat went through in the last 1.5 years. And it’s an ever-evolving project. Go give it a try!

Find more stories from our vault, here.
Also, we’re hiring! Check out open job positions by clicking below:
