Elasticsearch - The Trouble with Nested Documents
How we optimised Global Search for GO-FOOD by removing nested documents.
By Vivek Mittal
GO-FOOD is one of the largest content-based services in GOJEK, listing north of 300,000 restaurants.
We use Elasticsearch to enable discovery on the food dataset.
To provide a delightful experience to GO-FOOD users, it is important to rank down closed restaurants and their dishes on Elasticsearch (ES) before presenting the search results. Every restaurant has an attribute called ‘operational hours’, which determines the time and day when the restaurant is accepting orders.
This blog post covers the optimisations we performed on Global Search while powering the search over restaurants and dishes (GO-FOOD entities).
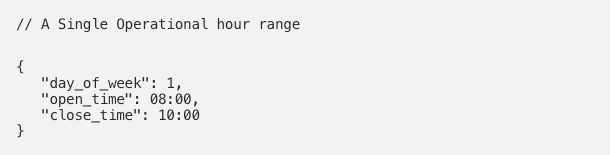
Example: A restaurant opens only two days a week, with specific timings:{

We have to index the operational hours in the restaurant’s Elasticsearch document so that the open restaurants can be ranked higher than the closed ones. The simplest approach is to index the restaurant document exactly how it looks in the above document. However, that does not work because Elasticsearch flattens the complex objects inside a document. A match across all attributes inside a single nested document is not possible with this method.
Reference: https://www.elastic.co/guide/en/elasticsearch/reference/current/nested.html
So, as suggested in the above reference, we used the nested data type to define the restaurant schema:

A simple Elasticsearch query to rank open restaurants higher than the closed restaurants looks like this:
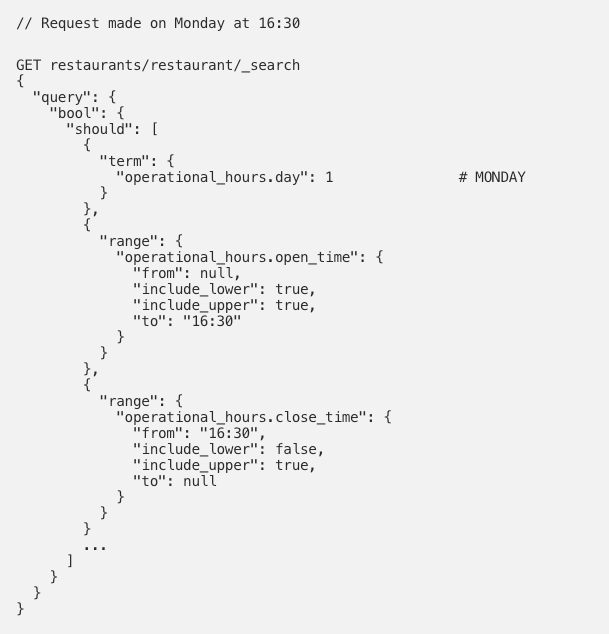
This works well. But was it fast?
Not fast enough, at least not during high read load. During peak load, the 99th percentile went as high as 600ms, causing close to 1% timeouts and unacceptably slow responses for at least 10% of the users.
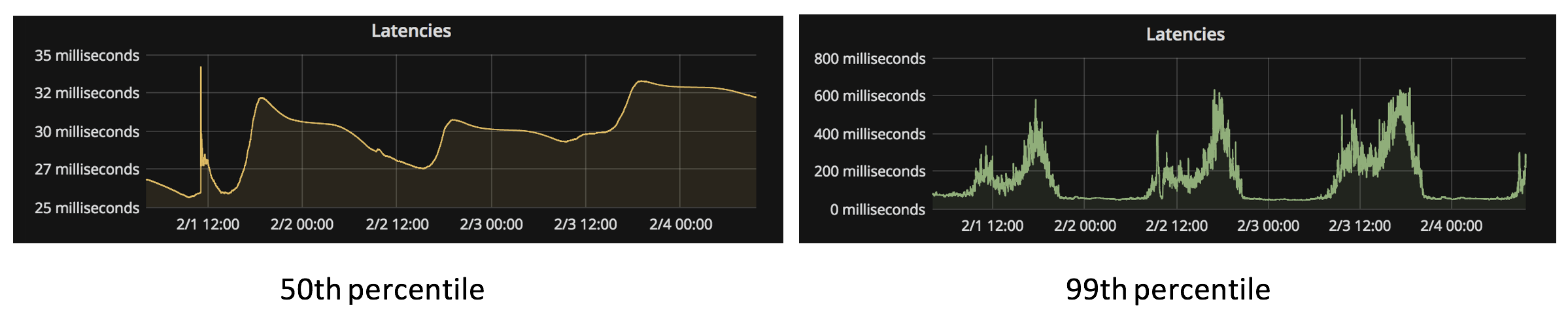
We profiled the Elasticsearch query and found that more than half of the time was spent on joining the nested operational hour documents with the parent document.
It is well-known that nested documents penalise the read performance, and high load per node-replica aggravates this penalty in a lucene-based index.
On further analysis, we figured that the response times were high during peak load due to the following reasons:
- Joining nested documents with top-level documents during reads.
- Large index size, causing frequent Full Garbage Collection (GC) (every operational hour was a different document inside Elasticsearch, increasing the index size). This in turn increased the
99th percentile.
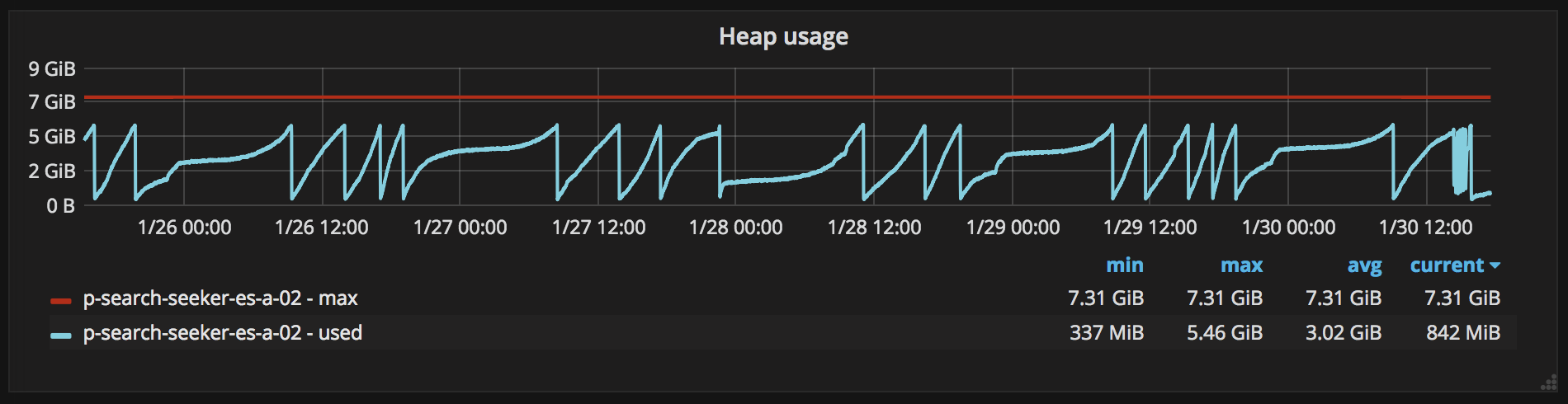
The easiest solution was to add more nodes to the ES cluster. This is acceptable, but not the most efficient use of resources. So, we decided to attempt to optimise the index before adding nodes horizontally.
The goal was simple, remove the nested document — denormalise the operational hour.
In a nutshell, we expanded the operational hour range to time points (rounded down to the nearest 5 minutes) and encoded each time point to an integer. While querying, we encode the request time using the same encoding function and a simple term clause on the encoded operational hour field to rank the open restaurants higher than the closed ones.
How it works
1. Encoding a single instance of time
We encoded a single point in time to a five letter integer where the first letter represents the day of the week, second and third letter represents the hour and the last two letters represent the minutes.
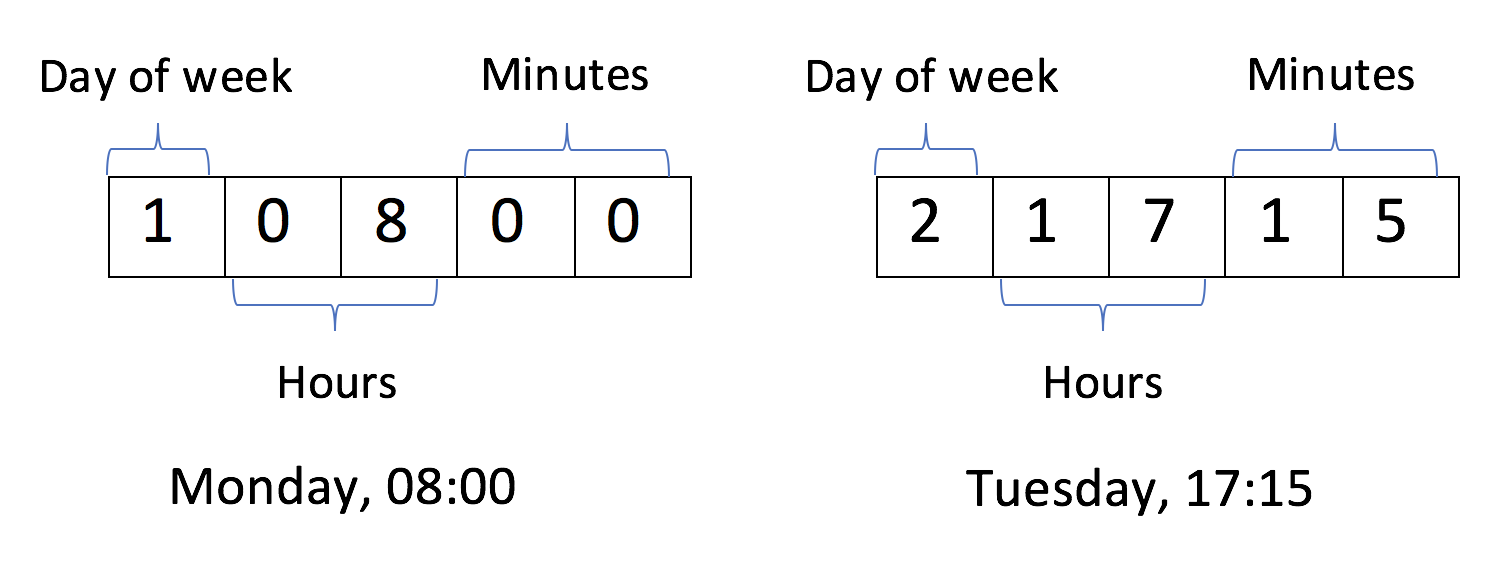
2. Exploding the time range to encoded time points
Expanding an operational hour range to a list of encoded open times (rounding down each open time to the nearest 5 minutes window):
The above depicts that the restaurant is open during the following timings (rounded down to five minutes)
Monday 08:00, Monday 08:05, Monday 08:10 ............ Monday 10:00which can then be encoded as
10800,10805,10810,10815,10820,10825,10830,10835,10840,10845,10850,10855,10900,10905,10910,10915,10920,10925,10930,10935,10940,10945,10950,10955,110003. Modify index schema
We then changed the index schema to make the operational hours an integer field (removing the nested field altogether):

The restaurant indexing requests started looking like:
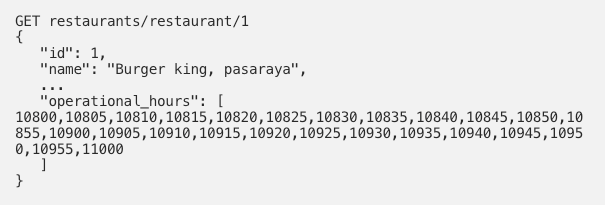
4. Encode request time & perform a term match
We encode the request time using the same encoding function (rounding down to the nearest 5 minutes window) and make a term query to find the exact open time point in the document.
A simple Elasticsearch query to rank open restaurants higher than the closed restaurants:
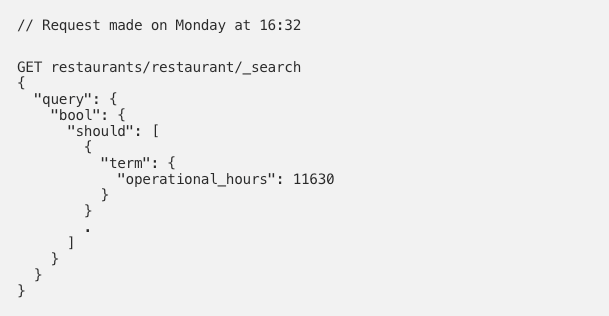
The only disadvantage of this encoding is that a restaurant might be ranked incorrectly for the step size defined (5 minutes after close time). This is a small compromise we chose to live with at the moment, considering that this had no impact, whatsoever, on our CTR.
Results
After the encoding, there was over 35% improvement in the 50th percentile and over 90% improvement in 99th percentile during peak load, with zero timeouts.

Since we removed over 90% documents (nested operational hours documents) from Elasticsearch, index size was also reduced significantly. This caused less frequent full GCs, enabling better performance overall.
We also index encoded restaurant operational hours in the dishes index, where we saw an even better performance improvement (because of a relatively much larger data set in dishes).
Hope this was an interesting read. Thanks for taking the time. 🙂
P.S. This article emphasises the performance impact of nested documents at scale. Starting with ES 5.2, this can be solved using the ‘date_range’ type.
GO-FOOD is just one of the 18+ products in the on-demand ecosystem contained within the GOJEK Super App. Our products help people commute, pay bills, move houses… even get massages. Building something on this scale requires intelligent ideation and constant iteration. If that sounds like your cup of tea, head to gojek.jobs and help us grab a larger slice of Southeast Asia’s on-demand service pie. 🍕