Data infrastructure at GO-JEK
.

By Ravi Suhag
At GO-JEK, we build products that help millions of Indonesians commute, shop, eat and pay, daily. The ‘Data Engineering’ (DE) team is responsible to create a reliable data infrastructure across all of GO-JEK’s 18+ products. In the process of realising this vision, here are some learnings:
- Scale: Data at GO-JEK doesn’t grow linearly with the business, but exponentially, as people start building new products and logging new activities on top of the growth of the business. We currently see 6 Billion events daily and rising.
- Automation: Working at such a large scale makes it really important to automate everything from deployment to infrastructure. This way we can push features faster without causing chaos and disruption to the production environment.
- Product mindset: The DE team operates as an internal B2B SaaS company. We measure success with business metrics like user adoption, retention, and the revenue, or cost savings generated per feature. And our users are Product Managers, Developers, Data Scientists and Analysts within GO-JEK.
Infrastructure overview
Our data infrastructure lets publish and consume raw and aggregated data effortlessly and reliably. This unleashes a plethora of possibilities within GO-JEK. From AI-based allocations, fraud detections, recommendations, to critical real-time business reporting and monitoring. Given the real-time nature of business at GO-JEK, the entire data infrastructure from the ground up focuses on real-time data processing, unlike traditional batch processing architectures.
A simplified architecture diagram showing major components of our infrastructure stack:
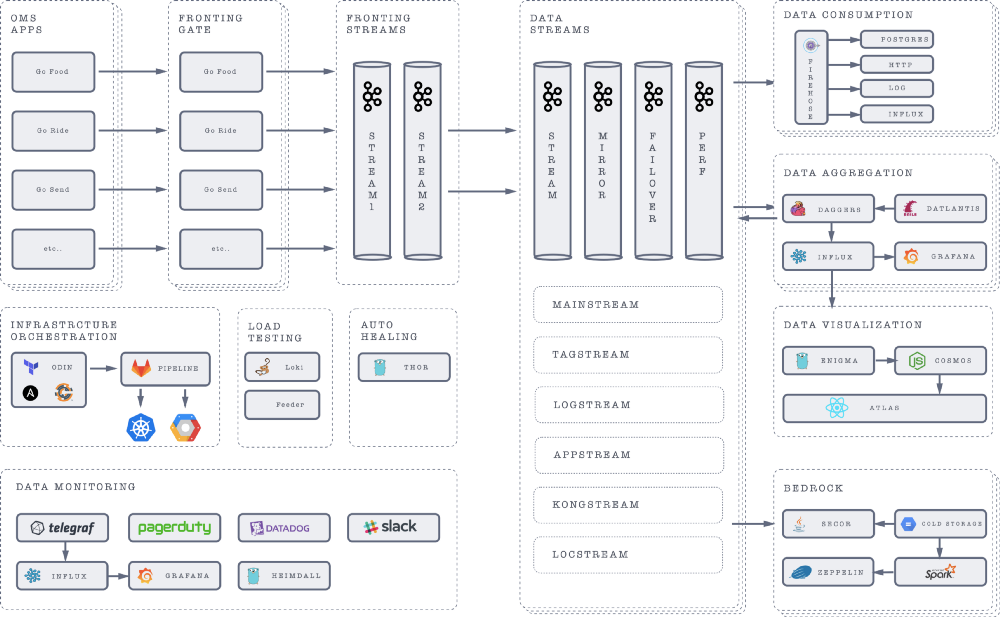
Data Ingestion
Raw data comes into our system from two main channels:
- Source code instrumentation: sends events through stream producer library available for different programming languages used at GO-JEK e.g. Clojure, Java, Ruby, Go.
- Machine stats daemon: runs on compute instances to collect API logs, container logs, statistics, like counters and timers, sent over UDP or TCP.
Stream producers provide publishers with the power to evolve their data schemas without breaking any of the consumers. Data is encoded as protocol buffers, a language-neutral, platform-neutral extensible mechanism for serializing structured data.
Stream producers publish encoded data to fronting servers, particularly suited for high traffic. Each team is allocated with one or more highly available fronting servers to avoid any single point failure and data loss.
Data Stream
- Fronting streams push data to central data streams. Data streams are highly reliable multi-region, rack aware Kafka clusters.
- We have more than 10 different data streams. Each handle more than a billions points each day. e.g. Locstream- Driver Location stream, Logstream- API Log stream, Tagstream- Segmentation stream etc.
- Mirror stream is the mirror of its corresponding data stream with high data retention, purposed for data aggregation and data replays.
- Perf stream is an exact copy of data stream for chaos engineering and load testing purposes.
- We are also working on making data stream highly available by having a failover mirror cluster by using cluster service discovery to prevent any downtime.
Data Consumption
Our Firehose component allows consumption of raw as well as aggregated data without doing anything more than setting up a web application to receive messages.
- Firehose can work in different sink modes. At the moment firehose supports more than 5 sink modes including HTTP, Influx, Postgres, Log and more.
- Firehose can be easily deployed on VMs — Virtual Machines or Kubernetes clusters.
Bedrock
Data must be retained for business or compliance purposes on a long-term basis, if not indefinitely.
- Secor clusters pull data from data streams to persist messages for long-term storage. We run Secor, distributed across multiple machines. The data is stored in parquet format to cloud storage.
- Zeppelin is a web-based notebook that enables interactive data analytics. We use it for querying data from apache spark cluster on top of our cold-storage.
Data Aggregation
- Dagger is our real-time streaming aggregation and analytics platform powered by Flink.
- To inhibit control and isolation, each team has dedicated dagger clusters, but it comes at the cost of handling large volume data replication and maintenance. Currently, we are running more than 10 dagger clusters with increasing demand.
- Datlantis is a user friendly interface to a fully automated system that creates and deploys custom streaming aggregation on top of Daggers. This allows us to create and deploy massive, production-grade real-time data aggregation pipelines in minutes using SQL-like syntax. The results are written to a time series database.
Data Visualization
Data is our biggest asset and there’s immense potential in making sense of it. Data viz infrastructure helps us find insights and improves our decision making.
- Enigma is a metrics query engine to access time series data with powerful functions to aggregate, filter and analyze.
- Cosmos is the configuration service which holds mappings of Atlas visualization layers and Dagger metrics. More on this later.
- Atlas is our geo visualization platform for exploring and visualizing location data sets at scale. Read more about ATLAS here.
Infrastructure automation
- Odin, built on top of terraform and Ansible/Chef enables us to safely and predictably create, change, and improve infrastructure. It allows us to define infrastructure as code to increase operator productivity and transparency.
- Odin can create clusters, services, replicate data infrastructure across multiple data centers and manage infrastructure state.
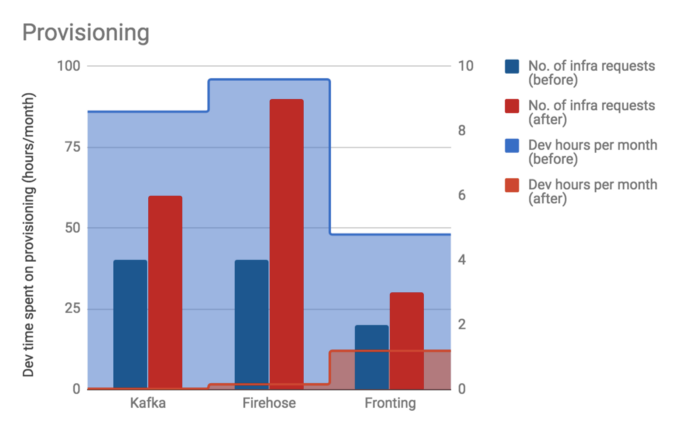
- Odin has helped us reduce provisioning time by 99% despite increasing number of requests.
Chaos engineering and load testing
- Loki is our disaster simulation tool that helps ensure the infrastructure can tolerate random instance failures. Loki can randomly terminate virtual machine instances and containers, exposing engineers to failures more frequently and incentivise them to build resilient services.
- Loki can also launch feeders and consumers on demand to load test the new or running clusters.
Infrastructure Monitoring
Infrastructure monitoring is an essential and a high priority job. It provides crucial information that helps us ensure service uptime and optimal performance. We use a wide range of monitoring tools to lets us visualize events and get alerts in real-time including TICK stack, Datadog, PagerDuty.
We are also working on Heimdall, an internal data tracing service to collect and visualise data and events by data infrastructure. Heimdall builds reporting dashboards for monitoring the state of data collection every day in GO-JEK.
Want to Learn More?
In the upcoming posts, we will be discussing each component in detail. If you like what you’re reading and interested in building large-scale infrastructure that excites you, do check out our engineering openings at gojek.jobs. As always, would love to hear what you guys think.