DAGGERS: Data aggregation in real time
How we deploy jobs in production within few minutes and aggregate data in real time, without any developer effort.

By Gaurav Singhania
We have a Super App of 18+ products ranging from ride-hailing, food delivery to payment wallets. Given the nature of our products and how it’s interlinked, it’s imperative for us to react to the market in real time. Surge pricing, API Monitoring are just a few examples.
Problems Faced
Hand coding the aggregation logic had the following challenges:
- Lack of in-depth domain knowledge for various use-cases
- Multiple back and forth to fine tune the logic
- Longer feedback cycle; 3–4 weeks per use-case
- Requirement backlog piling up
- Limited engineering bandwidth
Creating the blueprint
Given the variety of problems, we wanted a DIY solution with an SQL interface for real time data aggregation. With a DIY solution, analysts would be able to tackle the problem without any development effort. Now, as analysts would be the first to interact with it, SQL was the obvious choice for its language.
Few things we had to keep in mind:
- Abstract out the technicalities
- Simple data presentation
- Minimal configuration
- Easy user-interaction with (generated) data
Abstracting technicalities
At GO-JEK, we rely heavily on Apache Kafka. For maintaining the sanity of data in Kafka, we use Protocol Buffer (Protobuf) as the schema. Apart from faster SerDe, it also allows us to be backward compatible by following simple rules such as:
- No change to data type of existing fields
- Add new fields rather than editing the old ones
- No change in the sequence of fields
We also have multiple Kafka clusters depending on the source, and criticality of data. To help users interact with data freely, we let our user select the schema and auto populate topics across clusters with the schema. This allows our users to be incognisant of the underlying Kafka details.
Designing the engine
More than designing, it was about selecting the right one for our use case. We finalised Apache Flink for the following reasons:
- SQL support with Apache Calcite
- High Performance
- Low-latency
- Streaming over windows
Architecture of DAGGERS
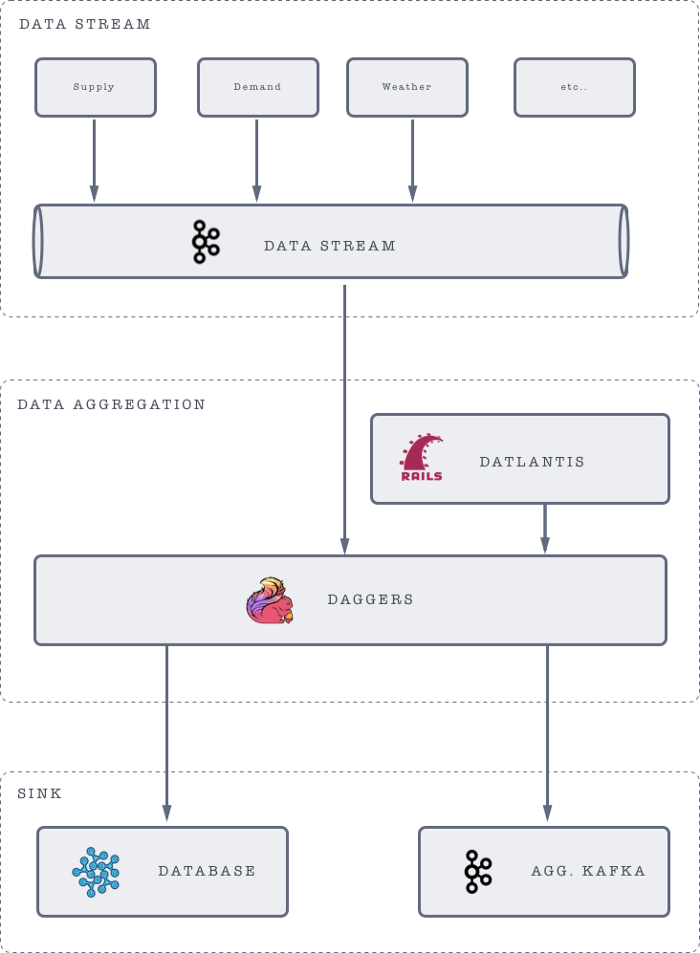
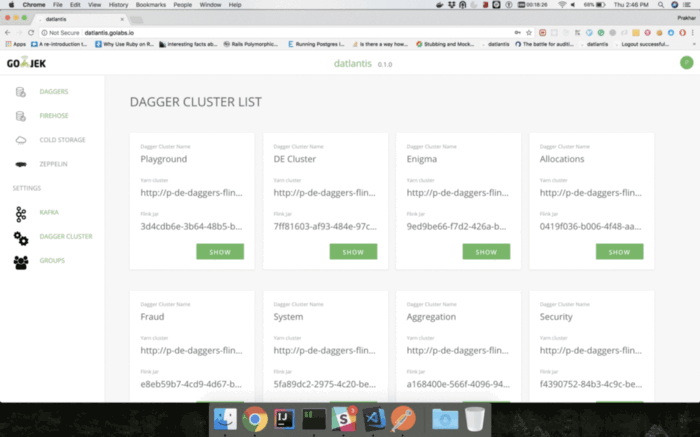
User Interface
Our UI portal - Datlantis, integrated with CAS takes care of authentication and authorisation. It allows a user to create a DAGGER in 3 simple steps
- Select input data source
- Write Query
- Select output data sink
Data Source
Different Kafka clusters serves as the data source for Daggers
Data Sink
For Daggers, we have multiple sinks
- Time series database — influx
- Apache Kafka
Monitoring: We push the generated data to influx, which is then integrated with grafana to allow a user to create dashboards for monitoring & alerting purposes.
Application: Data is sent to Kafka which can then be used by a downstream system.
Creating DAGGER
A job in Flink is created by writing a SQL like query after selecting desired data source & sink on Datlantis. The job thus created, pushes the aggregated data to the configured sink.
The gif below demonstrates the entire workflow for creating a Dagger.
Sample Query
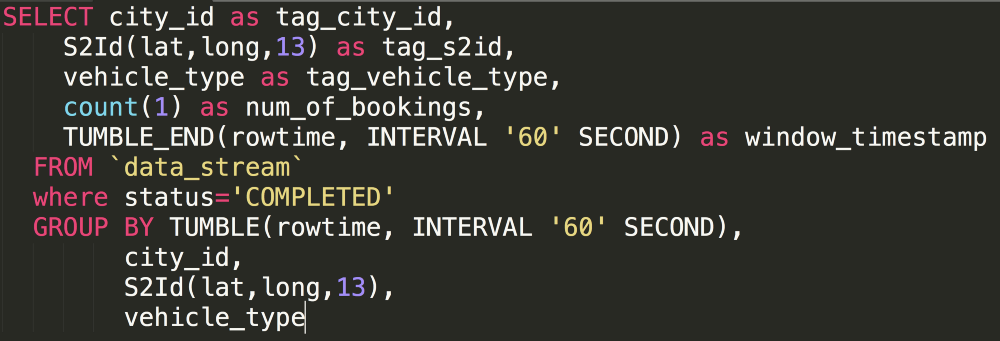
The above query will generate a completed booking with different dimensions every minute:
- City
- Vehicle type
- Location (S2ID)
Deployment
We have hosted multiple Flink over Apache Yarn for different teams. The entire process is automated with the help of terraform and chef.
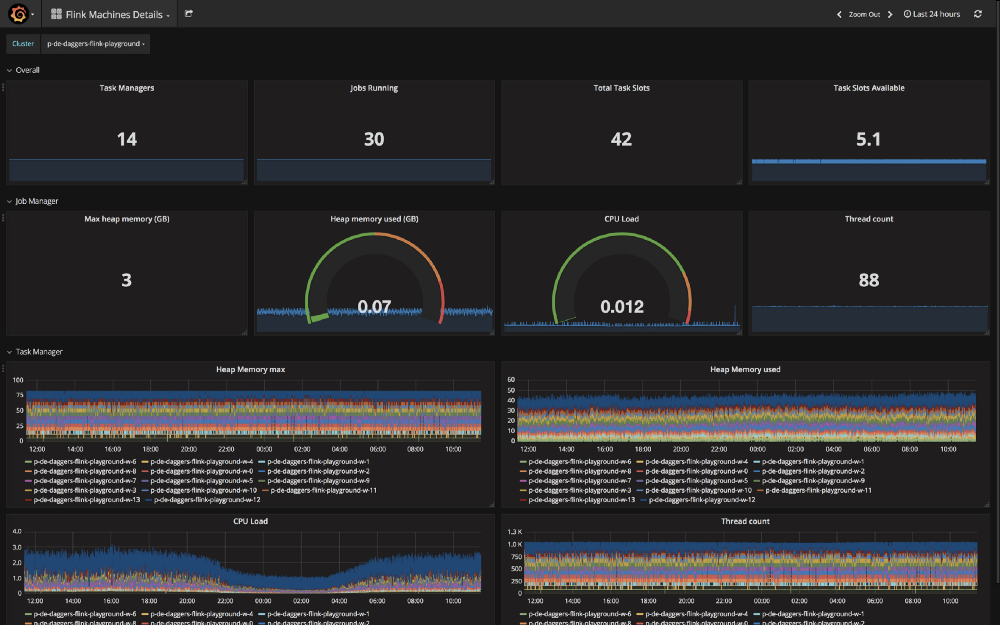
Control Room
The above infrastructure needs to maintained and monitored. To be able to do that, we have :
- Dashboards for the health of each Flink cluster
- Dashboards for the health of critical Flink job(s)
- Alerting in case of any problem(s)
Impact
- 5+ Billion message per day — For tracking system uptime across 300+ micro services.
- 44,000 geo location points data processed every minute for dynamic surge pricing.
- 25+ Metrics captured- Created & Monitored by analysts.
- 26% better conversion by User segmentation & real time triggers.
More use cases can be found here
Daggers is one example of building an in-house product to empower data-driven decisions. There are tonnes of these examples and we’re looking for developers who want to build beautifully designed products from scratch. Check out gojek.jobs for the openings we have. It should be worth your while 😉
