Columbus: In Search of New Frontiers
The story of GOJEK’s Tile38-based serviceability solution which helped improve efficiency and code maintainability.
By Akshay Nambiar
When you open the GOJEK app to book a ride, or order some food, for example, a lot of things happen at the backend. One of the things we have to do on such occasions is to understand whether the area the customer is in is serviceable by our driver partners.
Until recently, whenever a developer needed to add new service areas to the map, the task took them close to around seven days.
One of the pillars of GOJEK’s work philosophy, is the elimination of human bottlenecks through automation. We had to do something.
This story is about how we replaced an existing in-house geospatial data-basing and analysis solution (which was quite cumbersome) with a new Tile38-based implementation
The background info
A Geographic Information System (GIS) can be used to capture, store, manipulate, analyse, manage and present spatial or geographic data. GIS can be used for all kinds of mapping and location-based analysis. At GOJEK, we use GIS to store and analyse spatial data, to figure out if the area where the customer is located is serviceable or not. This was done using the serviceability-api.
In service of this, and to enable faster, easier deployments and get rid of code maintainability nightmares, we decided to replace the in-house serviceability-api with a simple wrapper over TILE38 in-memory Geo-spatial database.
As an homage to the explorer who contributed so much to the new world, we decided to call this solution — Columbus.
Similar to how Columbus discovered places around the world, GOJEK uses Columbus as a service to expand our horizons.
Why do we need it?
Let’s start with what public transport in Indonesia looked like before GOJEK. Many depended on ojeks, decentralised motorcycle taxis that waited at designated taxi stands. The scene looked something like this:

Today, the click of a button ensures the taxi comes to your location. What makes this possible?
Computers, engineering, algorithms, engineers (😎). But at its core — mapping.
Smartphones and GPS systems helped us build systems that allow customers to set pickup points on a map and use real-time location tracking. Usually, the address of a customer and the location of the driver partner is used to figure out who will be able to deliver the service to the customer.
We’re overlooking one thing, however. How to figure out if the customer’s location is serviceable, and if so, which sub-zone they are in at present.
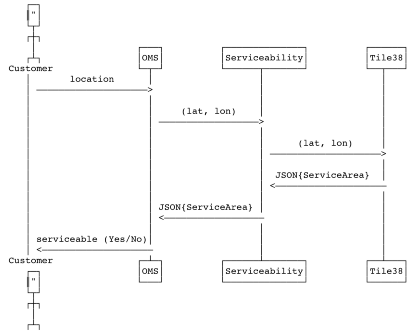
While the latitude, longitude (lat, long) is used to deliver the services, at a computational level, it needs to be analysed if the region which the coordinates point to falls in a serviceable area. After this first level check, we further need to compute more information about the particular zone in which customer/partner is located (all the OMSs won’t necessarily need the second level of information).
As different GOJEK products require different levels of information, geo-spatial data management and processing is required. Thus, for every query and every order, the serviceability-api is called to get information about the customer location.
The old serviceability-api uses core logic to implement geofencing based on geospatial analysis. Offloading this core logic to a trusted third-party open source software can reduce the code maintainability to only the features required for serviceability.
So we turned to Tile38 — a trusted open source in-memory geo-spatial database system. This made the lives of GOJEK engineers easier, enabling us to concentrate on real problems instead of the grunt work required to expand or add a service area zone (limited by hard assumptions made during the creation of the old serviceability-api).
Delete-Delete-Delete
The old in-house solution was hamstrung by assumptions made at the time of its creation, when GOJEK was operational only in Indonesia. At this time, most of the OMSs used the secondary level information about a customer location, which included the following fields related to a particular area.
serviceArea
kabId
kecId
propId
kecName
kabName
propName
Adding a new area with this much of secondary information was a nightmare for the engineers, as they had to rebuilt the area map with the inner region specifications. Then, this data was combined as a single object, and finally rasterised to obtain the S2ID. This was a time-consuming step which also caused further issues with deploying the changes during peak hours.
This meant that no changes to the serviceability could be done during peak working hours, thus forcing the engineers to spend valuable sleep time working on deployments.
As GOJEK started to venture into new markets, it became obvious that the initial assumptions about the data was not applicable in the new countries GOJEK ventured into. Only the first level of information was now sufficient and the secondary level of information was needed only by a few OMSs. The first level of information was far less than the secondary level information.
serviceArea
countryCode
currency
tzname
Adding data to the existing old serviceability-api on the fly was not possible, as it required redeployment with the updated data. This was not really feasible at the pace at which GOJEK was growing.
Serviceability is a crucial piece of software which is used by all the OMSs in GOJEK for information about the location of the customer and the driver partner, be it the first level of information or the second level of information. This meant it handled a lot of traffic. So, replacing an already existing solution with a comparatively slower solution would not be feasible. A few options were considered, and the first choice was Tile38.
We decided to do a spike and test Tile38 against production traffic in GOJEK.
Luckily, Tile38 was up to the task, and could handle our use-case.
Short-lived joy

A geofence is a virtual boundary that can detect when an object enters or exits the area. This boundary can be a radius or any search area format, such as a bounding box, GeoJSON object, etc. We decided to use this capability of Tile38 in order to segregate a collection of coordinates into service areas.
While this would, in theory, solve the problem of segregating service areas, the question of how fast Tile38 can find a service area which encloses a given lat-long came up. For this, we created a spike server written in Golang to see whether it would actually return the correct service area enclosing the given lat-long within a reasonable time.
It did not.
The older version of serviceability had a response time of 2ms while Tile38 had given a response time of 180ms. 😓
How did we solve the problem ?
Step 1: Fix optimisation issues
The first thing that we noticed was that containers were restarting and a lot of requests were timing out. This timeout issue made us realise that this could be a problem with the Redis Connection pooling configs. We had used RESP protocol to communicate with the Tile38 DB and the connection pool configs were set in a non-optimal manner.
After a lot of testing, we came up with optimal values for maxActiveConn, maxIdleConn and maxIdleConnTimeout values.
Consequence: Reduced response time from 100ms to 70ms.
STEP 2: Fiddle with commands
The second step that we took was to locally check the response time of the query used to retrieve the data from Tile38. To our surprise, we found out that the query itself took around 20ms and we were querying Tile38 DB twice to get the result (it was not possible with a single query at that phase of development). Naturally, we found another way to query the database which took less time (13ms). This opened up an ocean of possibilities, and we then leveraged Tile38’s capability to run LUA scripts to shave off another 5ms.
Consequence: Reduced response time from 70 to 40 ~ 50ms.
STEP 3: The apple that fell from the tree
We were still left with 2 query statements that took around 20ms to run both the commands. We needed to reduce this to one command.
Our strategy? We stored our response inside the key in the Redis collection.
This reduced the number of queries from 2 to 1 and allowed us to use another query, which takes a lot less time to execute than the previous ones.
Consequence: Reduced response time from 40ms to 15ms.
STEP 4: The cherry on top
We knew we were close to the finish line, and the final step was to optimise Tile38 itself by reducing the precision of search. We did this by increasing the search radius from 1m to 200m. This added the finishing touch to Columbus
Consequence: 15ms to 10ms.
STEP 5: Deploy!
We deployed Columbus to production with this response time, still a little shy of the 5ms that was our target.
However, there was a surprise in store.
All this time, we were using GO-REPLAY to replay the production traffic onto Columbus, but when the actual production traffic was served, the final response time reduced to 3ms.
Not only had we solved the response time issue, our original objective of saving developers time in adding new service areas was also met. We created a separate repository that was only used to store the data and add new service areas.
A developer who used to spend around 7 days adding a set of service areas can now do it in 30 seconds with the help of a small Golang script.
The importance of Clean Code
The programming language of choice to communicate with Tile38 and to give results to the OMSs was ‘Go’, because of its lower memory footprint and concurrency capabilities. The spike was successful, yet the initial response time was not satisfactory. However, that was only a matter of fine tuning the parameters and increasing the replicas.
We started writing the wrapper code around TILE38, with the best practices that we picked up from GOJEK’s Engineering Bootcamp003. So the confidence in the code stemmed from the extensive tests/specifications that we had written for the logic itself. Slowly, things were falling into place, and then it was time to decide how to do the deployment. We needed a deployment option that could also handle scale seamlessly — Kubernetes was the default choice.
With support for TILE38 for Kubernetes already available and the help of existing tools at GOJEK, deployment to Kubernetes cluster was a simple affair. All we had to do was configure the deployments as per our requirements.
To market we go
It was time to find customers for our elegant solution. We made a list of the OMSs which required the first level of information and the list of OMSs which required the second level of information. Given the number of OMSs we have, this was not a cakewalk.
We went ahead and started providing only the first level of information in the integration environment, just to figure out which OMSs would break. That was probably the best decision taken, as it helped us figure out which OMSs require which level of information.
Once we segregated the OMSs, it was time for the final deployment plan. Programmers are lazy, and to get everyone to the new system is difficult and (usually) time-consuming. So we decided to provide two end points on Columbus, and seamlessly route the requests for the majority of OMSs to one of the end points and provide the next endpoint as a configuration change to the OMSs which required the second level of information. Once all the systems were in place, we slowly rolled out the actual traffic to Columbus.
Voila!
Columbus had no problem scaling. Now, addition or expansion of service regions could be done in a matter of seconds as opposed to the many hours that were required earlier.
DEPLOYMENT OF TILE38
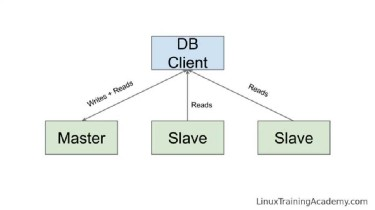
Guess what! Tile38 provides leader-follower capabilities too, so we used this to create a helm chart which was in turn used to deploy Tile38 DB pods to production.
As we finished the work on Columbus for our first use case, we stumbled across another one. The team which manages the Pick-up Point of Interest (PPOI), at popular locations, was having issues with accuracy, which could be improved with some help from Columbus.
As a result, the same Columbus deployment is helping tackle two different use-cases, on the same deployment. One to figure out the service-area location and another to list the Pick-up Points of Interest.
We may have accomplished what we set out to do, but at GOJEK, work is never truly done. Something can always be improved.
Rephrasing the words of Robert Frost:
“ Columbus still has promises to keep,
And miles to go before it sleeps.”

Here’s a little context: GOJEK processes over 100 million orders a month, and completed 2 billion orders in 2018. With 19+ products and millions of api calls happening every second, every step that improves efficiency is a step we try and take. This also includes hiring people capable of ideating (and implementing) better solutions. Think that’s you? Visit gojek.jobs, and grab the chance to work with us! 🖖