Beast: Moving Data from Kafka to BigQuery
GOJEK’s open source solution for rapid movement of data from Kafka to Google BigQuery.

By Rajat Goyal and Maulik Soneji
In order to serve customers across 19+ products, GOJEK places a lot of emphasis on data. Our Data Warehouse, built by integrating data from multiple applications and sources, helps our team of data scientists, as well as business and product analysts make solid, data-driven decisions.
This post explains our open source solution for easy movement of data from Kafka to BigQuery.
Data Warehouse setup at GOJEK
We use Google Bigquery (BQ) as our Data Warehouse, which serves as a powerful tool for interactive analysis. This has proven extremely valuable for our use cases.
Our approach to push data to our warehouse is to first push the data to Kafka. We rely on multiple Kafka clusters to ingest relevant events across teams.
A common approach to push data from Kafka to BigQuery is to first push it to GCS, and then import said data into BigQuery from GCS. While this solves the use case of running analytics on historical data, we also use BigQuery for near-real-time analytics & reporting. This analysis in-turn provides valuable insights to make the right business decisions in a short time frame.
The initial approach
Our original implementation used an individual code base for each topic in Kafka and use them to push data to BQ.
This required a lot of maintenance in order to keep up with the new topics and new fields to existing topics being added to Kafka. Such changes required the manual intervention of a dev/analyst to update the schema in both code and BQ table. We also witnessed incidents of data loss on a few occasions, which required manually loading data from GCS.
The need for a new solution
New topics are added almost every other day to the several Kafka clusters in the organisation. Given that GOJEK has expanded its operations to several countries, managing the agglomeration of individual scripts for each topic was a massive ordeal.
In order to deal with scaling issues, we decided to write a new system from scratch and take into account learnings from our previous experiences. Our solution was a system that could ingest all the data pushed to Kafka and write it to Bigquery.
We decided to call it ‘Beast’ as it has to ingest all data that is generated in GOJEK.
Before starting with development, we had the following requirements to take care of:
- No data loss: Every single message should be pushed from Kafka to BQ at least once
- Single codebase: A single repository able to handle any proto schema, for any topic, without any code changes
- Scalability: The app needs to be able to handle substantially high throughput
- Observability: A dev should be able to see the state of the system at any given point of time
- Painless upgrades: Updating the schema for a topic should be a simple operation
Architecture
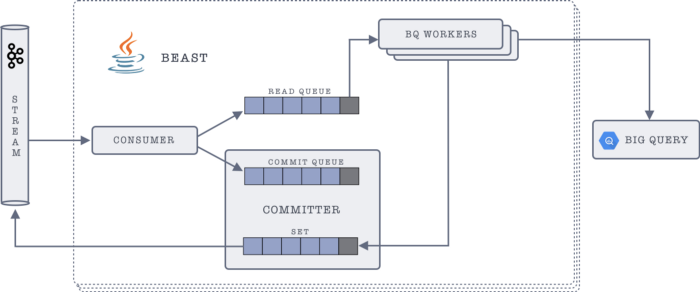
Beast takes inspiration from Sakaar, our in-house solution for pushing data from Kafka to GCS. Like Sakaar, Beast utilises Java’s blocking queues, for consuming, processing, pushing and committing the messages. Blocking queues allow us to make each of these stages independent of the other, letting us optimise each stage in and of itself.
Each Beast instance packs the following components:
- Consumer: A native Kafka consumer, which consumes messages in batches from Kafka, translates them to BQ compatible format, and pushes all of them into two blocking queues — Read Queue and Commit Queue.
- BQ Workers: A group of worker threads which pick messages from the read queue, and push to BigQuery. Once a message batch is pushed successfully, the BQ worker adds the committed offset of the batch to the Acknowledgement Set. This offset acts as an acknowledgement of the batch being successfully pushed.
- Kafka Committer: A thread which keeps polling the head of the commit queue, to get the earliest message batch. The committer looks for the commit offset of that batch in the Acknowledgement Set. If the acknowledgement is available (implying that the batch was successfully pushed to BQ), then the offset of that batch is committed back to Kafka, and it’s removed from the commit queue.
Salient Features
Beast is entirely cloud native, thus scaling it is a piece of cake.
For high throughput topics, all we need to do is spawn more pods. Since Beast relies on Kafka consumers, we can have as many consumers as the number of partitions, and as long as they have the same consumer group, Kafka will ensure that all the consumers receive unique messages.
Beast takes a proto-descriptor file, which defines the details of all the protos in the registry. It then simply picks the details of the proto, specified in the configuration. This allows us to use the same codebase for all deployments, and also makes the upgrades a breeze.
Beast is open source 💚 🙌
Beast is now part of the open source domain. Do give it a shot!
You can find Beast here: 👇
 odpf
odpf
Helm chart for the same can be found here.
Contributions, criticism, feedback, and bug reports are always welcome. 😀

Building things runs in our DNA. Every member of the GO-TROOPS family is passionate about building and contributing to projects, teams, and communities that create real impact. Speaking of which, we’re looking for more passionate people to join our ranks. If that sounds like you, visit gojek.jobs and apply. Let’s build together. ✌️
