Applying the Single Responsibility Principle to Microservices
The single responsibility principle helped us fix Icebreaker, our chat service. This is how we did it.

By Soham Kamani
The single responsibility principle is one of the most tried-and-tested tenets of software design. Every module or class should do one thing, and do it well. We found this principle was applicable, and incredibly important, while designing our systems.
About a year ago, we released a new chat service (which we internally called Icebreaker). It allowed our users to communicate with drivers through the app itself, rather than use SMS (which cost both the driver and customer money).
However, all was not well. For numerous reasons, the service gave us a lot of issues and late night pagers. This post details the lessons we learnt, and some of the decisions we took to make this service more reliable.
The Problem(s)
In a nutshell, Icebreaker depended on too many other services to function properly. Let’s look at some of the tasks Icebreaker performed in order to create a channel:
- Authorise the API call: This made a call to our authentication service.
- Fetch the customer profile: This required an HTTP call to our customer service.
- Fetch the drivers’ profile: This required an HTTP call to our driver service.
- Verify if the customer-driver pair are in an active order: This made a call to our active booking storage service.
- Create the channel.
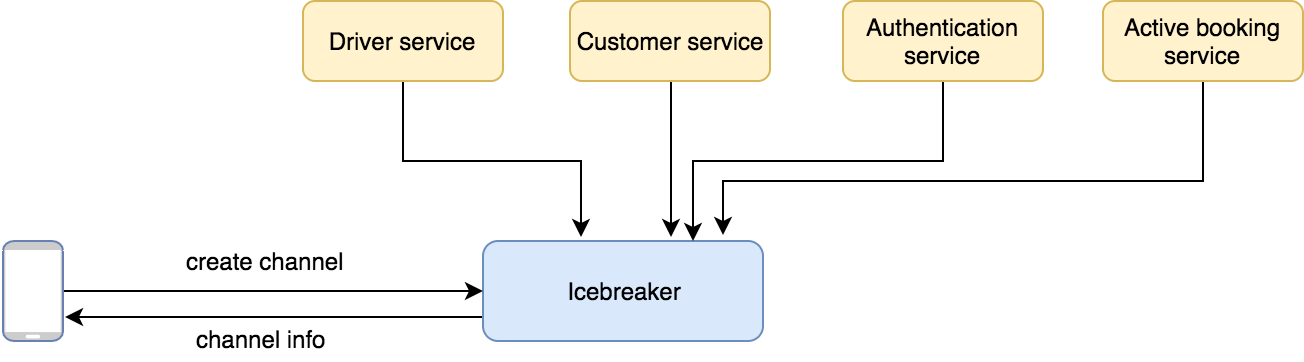
If any of these services failed, Icebreaker would fail as well.
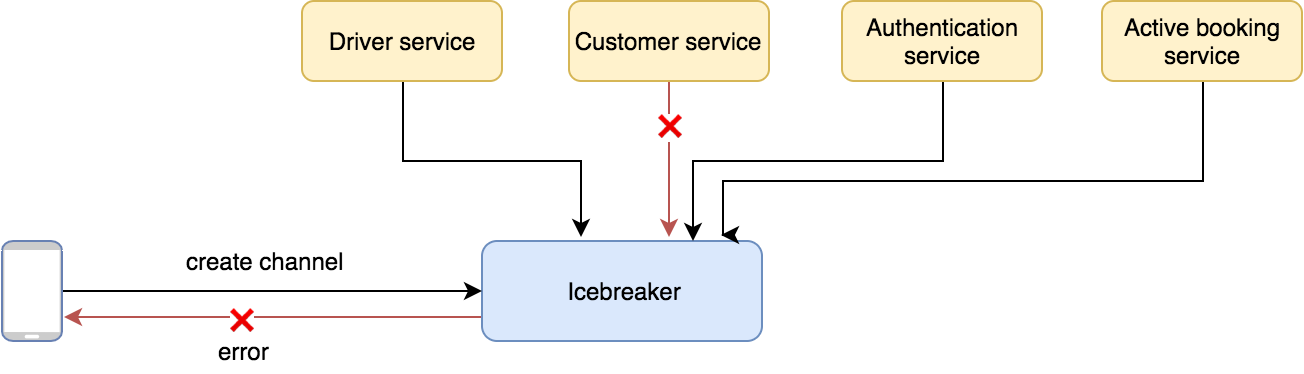
Even if we could ensure 99% uptime for all services in question, that still means the chances of all of them being up at the same time was 96%.
P(icebreaker active) = P(customer service active) * P(driver service active) * P(authentication service active) * P(active booking storage active) = 0.99 * 0.99 * 0.99 * 0.99 ~= 0.96
This means our downtime has increased four times over (4%, as opposed to 1%).
Not my job
When a service starts to do too many things, it’s bound to fail sooner or later. In this case, Icebreaker’s job was to create a channel between a customer and a driver. However, it was doing all this extra stuff: like authentication, verification, and profile retrieval. 🤦♂
Let’s take a look at the changes we made to get rid of each dependency:
Authentication
Every API call arriving to Icebreaker came with an API token which needed authentication. To solve this, we added a Kong API gateway. This authenticated all requests and added information about the authenticated user within the API headers.
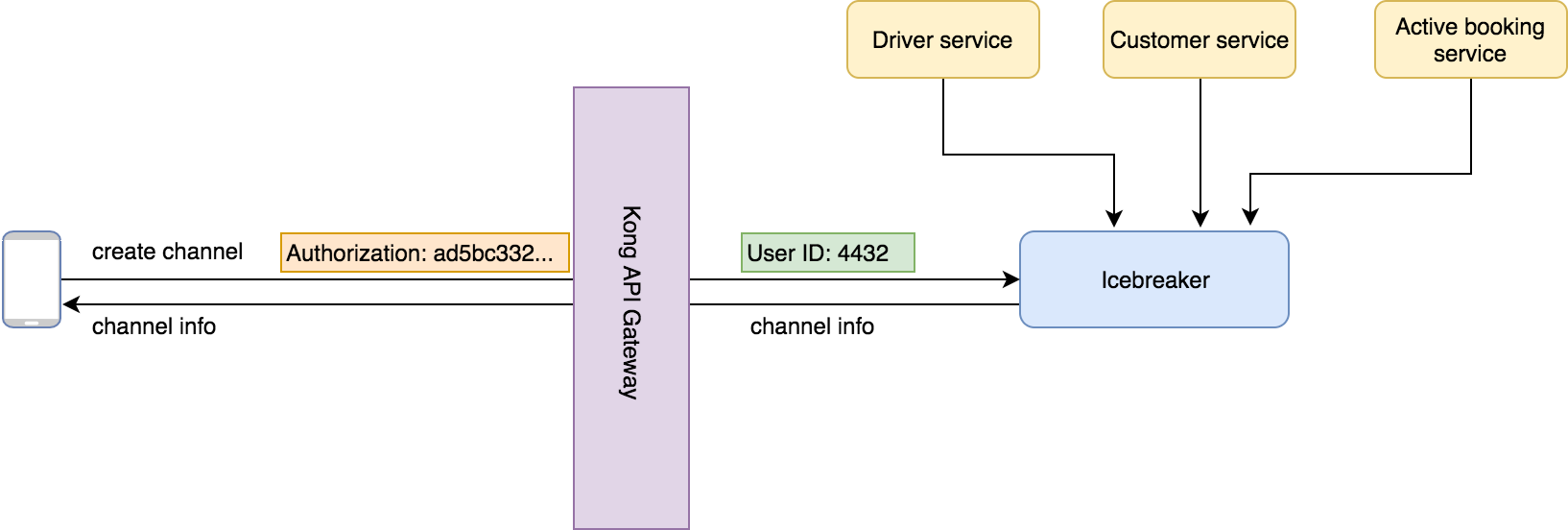
Now, every request arriving to Icebreaker was authenticated.
Key takeaway: Tell, don’t ask. The requests coming from the API gateway told the service that they were authenticated, rather than Icebreaker having to ask another service.
Profile retrieval
In order to create a channel, we needed a piece of information called the ‘chat token’ for each user. This was stored in the customer service for the customer, and the driver service for the driver.

Since Icebreaker was the only service using this token, we moved these tokens to it, and removed them from the customer and driver services.
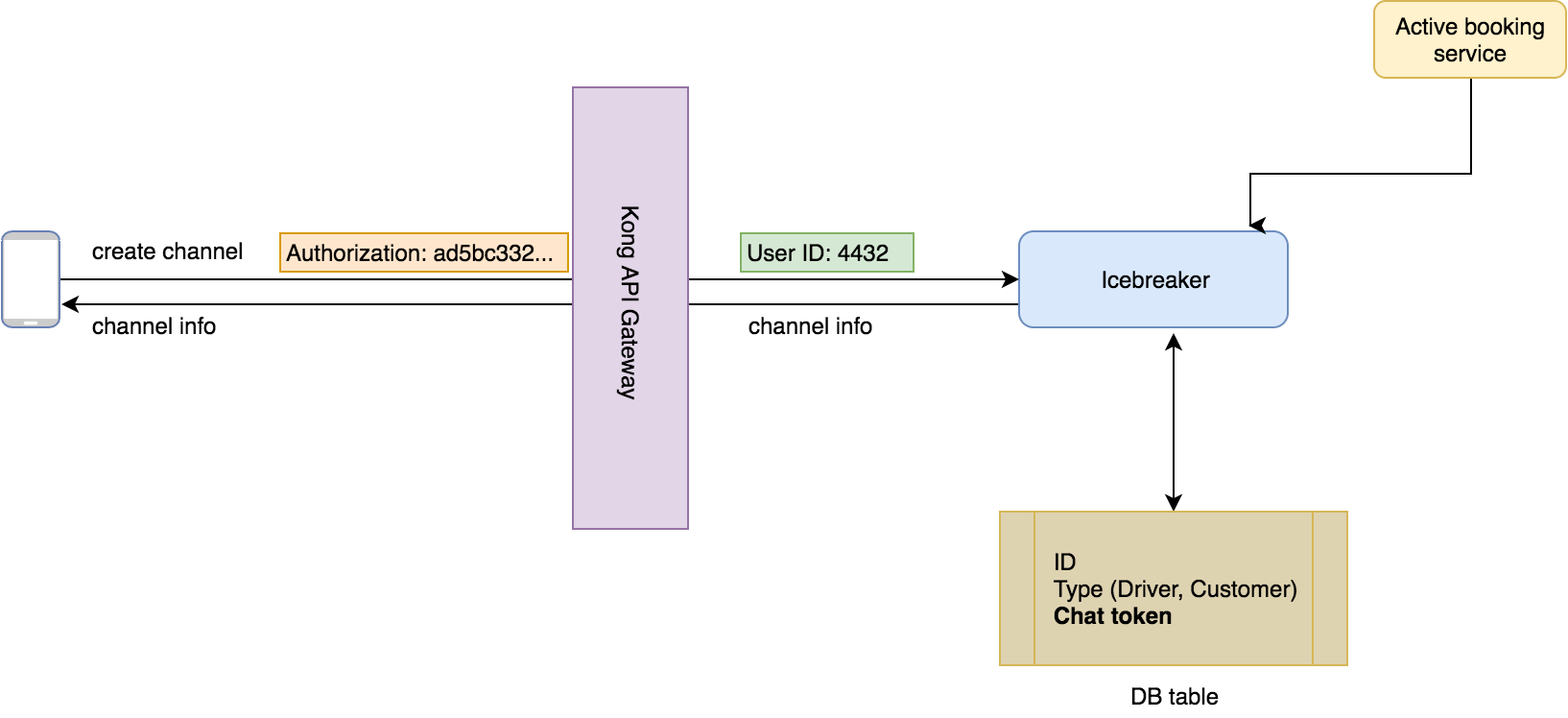
Now,Icebreaker had all the information it needed in its own database, which was a more reliable source of truth as compared to a whole other HTTP service.
Key takeaway: If your service is the only one using any piece of information, it should reside within the service itself
Active booking storage
Icebreaker used to create a channel on-demand every time the user hit its channel creation API. This on-demand creation required us to verify that an active booking existed, for which the user needed to create a channel. After all, it didn’t make sense to create a channel when the parties involved did not have an order with each other.
To fix this, we moved to an asynchronous architecture for channel creation. Instead of on-demand channel creation, we made use of GO-JEKs data pipeline, that published events every time a booking was made. Icebreaker now consisted of two components: the worker and the server.
- The worker consumed booking events every time they were made. It then created a channel between the customer and driver in the booking, and stored the channel information on a Redis cache.
- The server served channel creation requests as before. Only, this time, the channels were already created and cached, along with the order number.
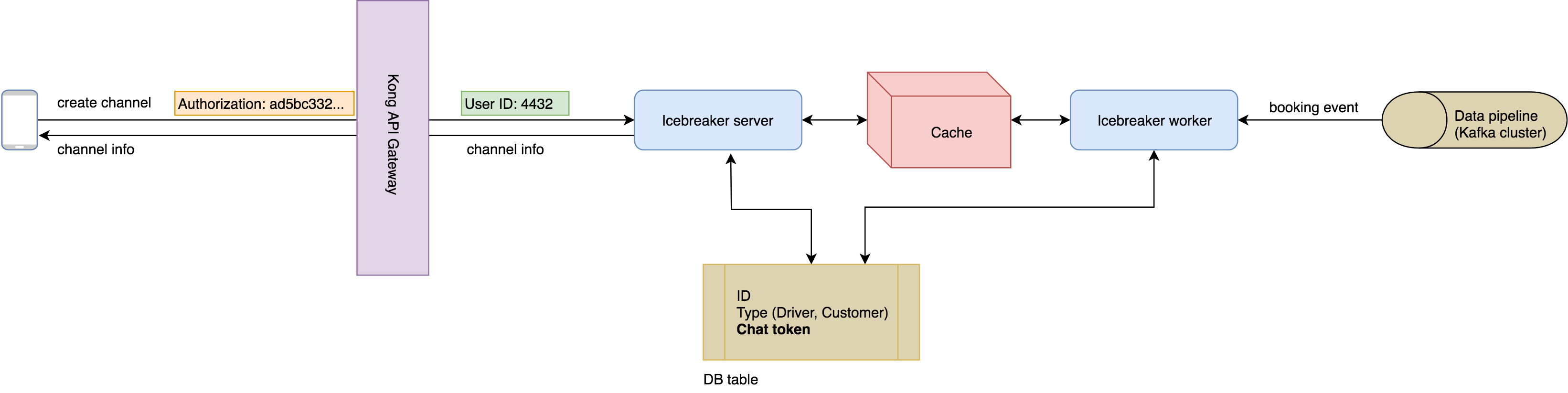
So, instead of on demand channel creation, the channels were created and stored beforehand. Since we were consuming booking events from our own data pipeline, there was no need to verify whether the booking was genuine or not.
Key takeaway: Again, tell, don’t ask. The events coming from our data pipeline told Icebreaker that the bookings were genuine. This meant it could create the channel, instead of hitting a service to verify the authenticity of the booking.
Results
Now Icebreaker did only what it was truly meant to do: create channels.
Since we removed dependencies on most external systems, we no longer had to worry about one system failure causing Icebraker to malfunction. The load on the external services also reduced, since Icebreaker was no longer using their endpoints for channel creation.
Moving to the asynchronous architecture also led to a drastic reduction in response time, from ~200ms to ~10ms, since we were pre-creating and caching channels for every order.
The takeaways we got from this experience conform with the single responsibility principle. In the end, it’s always better to ask ourselves: “Can this service do less?”
Want our stories in your inbox? Sign up for our newsletter!