An architectural overview of GO-JEK’s card personalisation engine

By Soham Kamani
For the backstory on how we came up with a personalised experience for every GO-JEK user, click here. This post is about the mechanics of how this ambitious project came to fruition.
TLDR; Our system is pull-based rather than push-based, and enforces a guaranteed response time.
GO-JEK currently has multiple internal services that want to get their cards delivered to the user. If the user were to wait for all services to return their own cards, it would limit the overall response time to that of the slowest of these services. Our architecture ensures that the user receives some cards at a reasonable time after making a request.
The responsibility of the Shuffle system as a whole can be summarized as: “Show the user at least some cards when they request for it”. This has been broken down into smaller responsibilities by each component of the system, which can be summarized in the order at which they occur:
- The Shuffle service accepts the users’ card request and sends it to an event queue. This request contains relevant information about the user, like location, time of day, and recent activity on the app.
- Content providers read events from the event queue and push relevant cards to a cache. This is the meat of the work, and is delegated to independent content providers.
(Internally, we call content providers “dealers”, since they are responsible for sending out the actual “cards” to the user) - The Shuffle Service waits for a fixed time after sending the card request and reads the available cards from the cache. This means cards that are not pushed to the cache before this time, expires.
- Finally, the Shuffle Service uses a ranking algorithm to sort all cards obtained from the cache and returns them to the user.
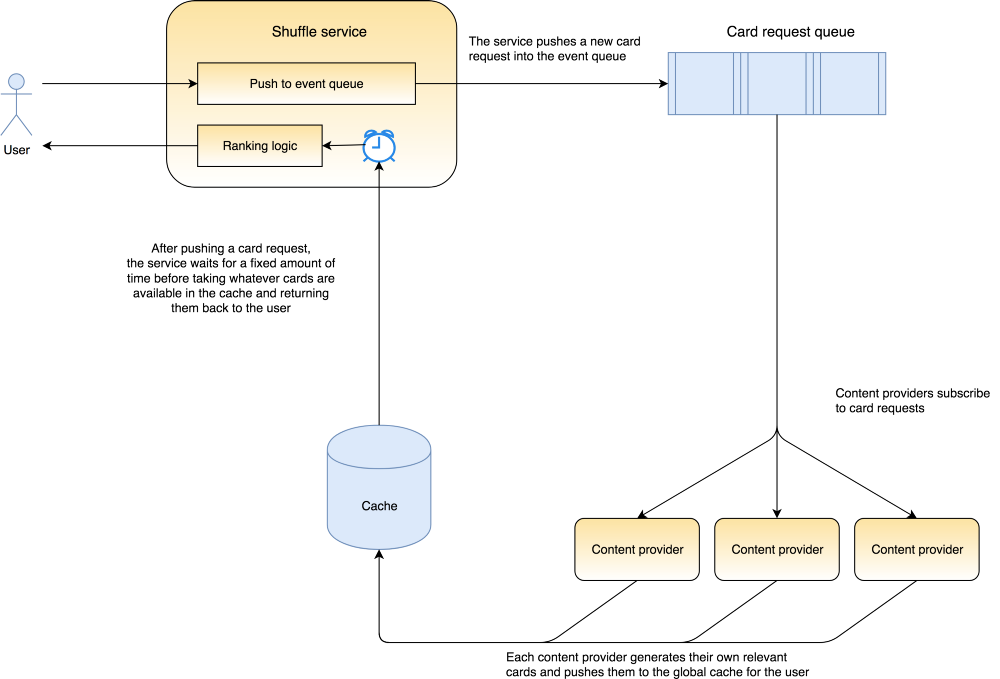
This also allows for greater flexibility in adding new dealers to the system. With the current architecture, the shuffle service does not know anything about the dealers. This means adding a new dealer only requires them to subscribe to the card request events, and push their own cards to the cache once they’re done.
Although the system as a whole performs a variety of complex large scale operations, each component on its own has a much simpler job.
The anatomy of a card
TLDR; We made use of protocol buffers to guarantee that the structure of cards stays consistent.
Now that we have an independently scalable system to deliver cards to the user, there’s another issue of making sure each service is stuck to a fixed data structure to represent the cards information. For example, a mobile application would expect the following structure for a simple card with some picture and text:
{
"title": "...",
"description": "...",
"image_url" : "...",
"priority": 5
}So, all of the dealers would have to comply with this structure.
Initially, we thought of extensively documenting the structure that a users’ application expected, so it would be easy for services to deliver compliant cards. However, we decided to enforce, instead of expect.
The protobuf package allows us to have a data interchange format which is also strongly typed. This means we can have a common contract for card requests and responses across the system, while at the same time enforcing its structure; something which was not in-built in other interchange formats like JSON.
Ranking and prioritization of cards
“Ranking” describes the order in which we display cards to the user. Just like any other dealer, the amount of content we have is way more than the amount of space available on the users’ screen. Our main objective is to see that the order in which the cards appear is the same as the order of their importance to the user.
In order to rank a card, we use a combination of factors that describe a cards’ relevance to the user, such as:
- The time of day at which the card would be relevant (for example, a card to prompt the user to book a ride to go home)
- The location of the subject of the card (how close the nearest GO-PAY top-up point is)
- How many times the user has clicked on this card before
Each of these factors are then multiplied by a weight and added together to determine the final rank of a card. The aforementioned weight is decided based on the type of card shown to the user.
For example, the nearest distance to a GO-PAY top-up point, which the user needs to walk to, is way more important than the nearest distance to the next GO-RIDE. This ranking matrix of weights for each type of card vs each type of factor, constantly evolves based on the data we gather about our orders.
After a rank is assigned to each card, the cards are simply sorted by their rank and shown to the user in that order.
Reduced development time with interfaces
One of the core aims when developing the shuffle system was to enable developers who weren’t familiar with shuffles’ architecture to still be able to work with the system. Making independent dealers kind of fulfilled this goal. But, it would be necessary to know and develop the consumption of card requests from the event queue, and the subsequent pushing of cards to the cache. This seems like a lot of unnecessary work. What we actually want the dealers to answer can be framed in the form of a simple question:
What to you want to show this user at this particular time and location?
For us, the information about a user, their location and the current time can be abstracted as a “Card request”. Each dealer takes this card request and returns a list of cards. What worked for us was exposing this contract as an interface for our developers.
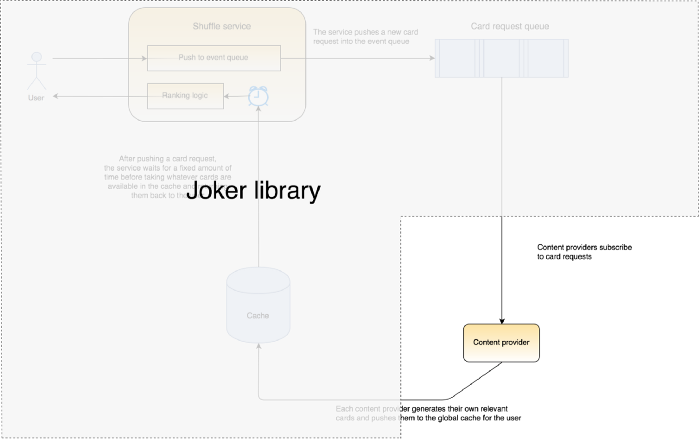
We developed an internal library called “Joker” for this purpose.
Joker abstracts the concepts of listening to the event queue for card requests and pushing cards to the receiver, into a single interface. In pseudo code, the interface can be written as:
interface Service {
function CreateCards(CardRequest) []Cards
}From a developer’s perspective, they need to import the Joker library, initialize an instance of Joker and implement the CreateCards function. This reduces development time dramatically as compared to developing the entire flow from scratch.
Conclusion
Project Shuffle takes advantage of a distributed workload, not just for dealing with the massive scale we face at GO-JEK, but also to distribute development effort across our services. This prevents a single point of failure in both cases.
- If a single dealer goes down, the user experience degrades proportionally, and not completely, since the other healthy dealers can still push their own cards.
- Since the development of dealers is independent, we can push out new types of cards at a faster pace.
In addition to this, by using a timeout mechanism to grab all cards that are sent by the dealers, we enforce a fixed SLA for the shuffle service.
This method, however, sacrifices the guarantee of getting all available cards for a user, in exchange for a guaranteed response time. Since we expect the number of dealers to increase in the future, this is a reasonable trade-off for a better user experience.
And yes, it’s a WIP, And yes, there are many use cases. If you have any tips, suggestions, comments, please leave a comment below. We sure can do with more ideas. Better yet, join us and help us scale, grow and learn! Check out gojek.jobs, we have plenty of opportunities for opinionated developers. Peace. 🖖
