A week in {GO-JEK, Consistent Hashing}
.

By Paramananda Ponnaiyan
It has only been a week since I joined GO-JEK and I am already in love with the energy and creativity here. The quality of conversations near our water coolers symbolises the success of culture in a hyper-growth startup. An Architecture major, for example, can talk for hours on how the building structure influences the moods of the occupants and how certain shapes are better for certain occupations.
The same applies to companies. This unbridled energy of solving complex problems is what makes GO-JEK a great place to work. It’s the challenge of how to keep a large company functioning like a startup. And I think GO-JEK is doing a phenomenal job at this. Anyway, more on that in another post.
The problem my team is working on is: sharding of microservices with Kubernetes. Irfan and I are working on the specific problem of how to add a new shard dynamically?
But first, the basics
Shard: A functional group of services with databases and caches (as necessary). Multiple shards of the same group may run, and hence, the databases are actually “sharded” as well.
Sharding function: When a request comes in, this algorithm decides which shard the request should go to. It’s important here that identical requests should always go to the same shard. Remember: The data for the request is also sitting only on that shard’s database.
Sharding Key: The input to the sharding function. For example: Driver Unique ID may be a Sharding Key. In this post, Key and sharding Key are used interchangeably.
Problem statement: How do you add a new shard to the existing cluster without requests going to the wrong shard ?
Background
Consider a cluster consisting of 5 shards named 0 to 4, using a simple modulo Sharding function. A modulo Sharding function just divides the incoming sharding key (lets assume its a number) by the number of shards and returns the remainder. The remainder is the shard number.( key % 5 )
So,
key 10 goes to (10%5 = 0) 0 shard
key 11 goes to (11%5 = 1) 1 shard
key 12 ->2 shard
key 13 ->3 shard
key 14 ->4 shard
key 15 -> 0 shard
If we now add a new shard (5). The modulo function becomes (key %6). Let’s see what happens to the keys now.
key 10 goes to (10%6) 4 shard
key 11 -> 5 shard
key 12 -> 0 shard
key 13 -> 1 shard
key 14 -> 2 shard
key 15 -> 3 shard
As you can see, every key is now going to a different shard.
Consistent Hashing
To solve this problem, we initially looked at Consistent Hashing. If K is the total number of keys and N is the number of servers, then Consistent Hashing promises that if a server gets removed, only K/N of the keys need to be redistributed. Other keys will continue to go to same shards as before the removal. This is significantly better than the modulo function which redirects every key when we add a shard.
In short, in Consistent Hashing, only the keys going to the removed server are touched.
Hypothesis 1: If we remove a server and add 2 more servers to a Consistent Hash, all the keys going to the removed server should now go to the newly added servers.
If Hypothesis 1 is true, then our addition of a new server is simply a removal and 2 additions.
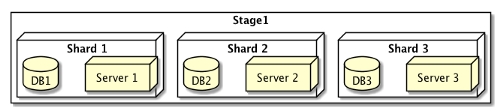
Stage1: Existing cluster
Stage2: Replicate Shard1’s DB
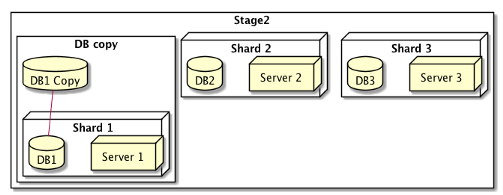
Stage3: Bring up Shard4 and Shard5 with DB’s prepopulated with Shard1’s DB.

Now all of the traffic previously going to Shard1 will go to Shard4 and Shard5. And because both have necessary data, they can respond correctly.
As with everything at GO-JEK, we start with Tests. We tested this and unfortunately the truth is:
Consistent Hashing promises only keys going to the removed shard are touched, but does not promise that they will be given to the new shard added. In-fact, adding a new Shard redistributes keys. Not as bad as modulo, but still randomly enough to make data replication non-trivial.
A virtual solution
The bottom line seems to be that adding or removing a shard always causes key redistribution. So the solution seems to be: don’t remove or add shards. Duh! what kind of solution is that ?
The idea is to have a large number of virtual nodes; more than your actual number of shards. Then map virtual nodes to shards.

Now as long as the Sharding function uniformally distributes keys across all the virtual nodes, Shard 1 and Shard 2 should get half of the traffic each.
Now to add a new node to take some traffic from Shard 1, all we need to do is map a few of the virtual nodes pointing to Shard1 to the new Shard. As before, we give Shard1 a copy of the database of Shard1 to start off with.

As long as you have a large number of virtual nodes, you can continue to add shards. The maximum number of shards you can support in this way is the number of virtual nodes you have.
Another important thing to note: as long as your Sharding function distributes keys uniformly over the virtual nodes, this algorithm will work. For example, the Sharding function could be modulo and this would still work.
What do you ya’ll think? Any tips? Suggestions? Did all of that make no sense whatsoever? Please leave a comment below. Would love to hear more.
We’re also looking to hire engineers who want to create impact at scale. If you fit the bill, come help us redefine scale. Check out gojek.jobs for more!