A TOAST from PostgreSQL
How Postgres handles data storage of oversized attributes.

By Nishanth Shetty
PostgreSQL is a powerful open source object relational database system, which has been widely adopted as a primary option for many applications.
In this post, we’ll take a look at how Postgres handles database storage and caching.
First, the basics
PostgreSQL database loads all data into page cache, which is different from OS Paging. A page cache of size 8KB is used for storing tuples, indexes, and Query Execution plans. Even the WAL are written to 8KB pages.
While the underlying stack may use a different block size, typically Linux (and most Operating Systems) use 4KB page size. So when PostgreSQL writes data to disk, the underlying stack may break into a smaller chunk depending on its block size (it may be 2 blocks of 4KB or 16 blocks of 512MB). But this is in the case of Full Page Write (FPW)
PostgreSQL limits the tuple (or row) to be stored within this page, which seems like a limitation seeing the size of the data users may want to store and is allowed by the database. But this limitation doesn’t enforce the size restriction on database rows. PostgreSQL handles this differently when the data spills out of the boundary.
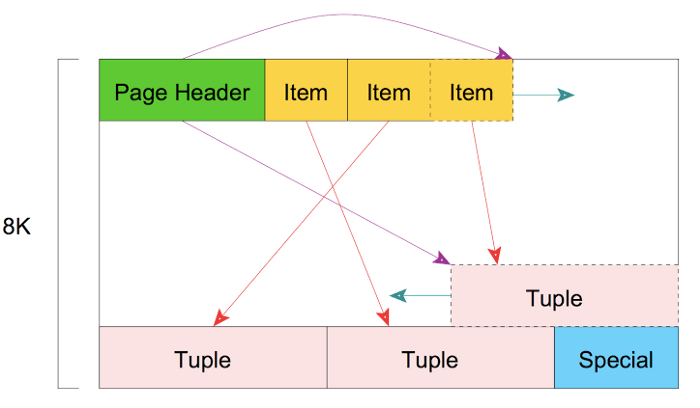
PostgreSQL allows data columns of larger size with types like varchar, text, bytea, json. Let’s understand how it manages to put large data in a fixed size page cache.
TOAST — The Oversized-Attribute Storage Techniques
Toast is a mechanism in PostgreSQL to handle large chunks of data to fit in page buffer. When the data exceeds TOAST_TUPLE_THRESHOLD (2KB default), Postgres will compress the data, trying to fit in 2KB buffer size. If the compressing of the large column data does not lead to smaller block (<2KB), it will be split into smaller chunks.
This is enabled by default and all tables will have the toast table associated with it. You can check the associated toast table in pg_class using the following query:
select relname from pg_class where oid = (select reltoastrelid from pg_class where relname=’TABLE_NAME’)The table name will be pg_toast_$(OID) where oid is the toast table oid, reltoastrelid of original table.
The toast table is in pg_toast schema, so to query you need to use:
select * from pg_toast.pg_toast_$(OID)The above query will print the toasted chunk_id, chunk_seq, chunk_data, if present.
Note: pg_toast_* table entry is only for data which is split into multiple chunks.Out of line storage
If data does not fit in a single page cache even after compression, then the out of line storage technique is used, splitting data into multiple chunks of smaller size.
Toast table storage strategy
All database columns have the storage strategy associated with them, explained as follows:
1. Plain
Does not allow out of line storage or compression, ex : numbers, char type.
2. Extended
Allows out of line storage and compression, default for most data types that can use toast. Compression is attempted first and then if that does not help to fit the data in page, out of line storage is used.
3. External
Allows out of line storage, not compression. Makes substring operation faster on text and bytes columns. Has storage space penalty.
4. Main
Same as external but out of line is performed when there is no way to make the column small enough to fit in page.
All the columns will not take part in toast, as the implicit size limit of types such as char, numbers will not hold large data.
The types which have variable length representation — such as text, varchar — are ideal toast candidates.
This will ensure the data can be loaded into single page buffer. While this is useful when storing large amounts of data, it does add some performance overhead of compression-decompression.
However, this same overhead can be used to our advantage.
Let’s say we have a remote data center storing the data. If we query the toasted data over the network, the data size to be shipped is smaller and decompression time can be less, compared to network latency for large raw data.
Hopefully, this gave you an understanding of how Postgres handles storage and caching. So let me leave you with a question:
Q: Why are the attributes of pg_toast_* storage strategy plain?Leave your answers in the comments, and let me know if this was helpful. If you’d like to know more about this topic, check out the links below:
1. https://www.postgresql.org/docs/current/storage-toast.html
2. https://blog.codinghorror.com/maybe-normalizing-isnt-normal/
3. http://www.25hoursaday.com/weblog/CommentView.aspx?guid=cc0e740c-a828-4b9d-b244-4ee96e2fad4b
4. https://www.citusdata.com/blog/2013/04/30/zfs-compression/
5. https://madusudanan.com/blog/understanding-postgres-caching-in-depth/
6. https://www.2ndquadrant.com/en/blog/on-the-impact-of-full-page-writes/
